OneClassSVM#
- класс sklearn.svm.OneClassSVM(*, ядро='rbf', степень=3, gamma='scale', coef0=0.0, tol=0.001, nu=0.5, сжатие=True, cache_size=200, verbose=False, max_iter=-1)[источник]#
Обнаружение выбросов без учителя.
Оценка поддержки многомерного распределения.
Реализация основана на libsvm.
Подробнее в Руководство пользователя.
- Параметры:
- ядро{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} или вызываемый объект, по умолчанию=’rbf’
Определяет тип ядра, используемый в алгоритме. Если ничего не указано, будет использоваться ‘rbf’. Если указана вызываемая функция, она используется для предварительного вычисления матрицы ядра.
- степеньint, по умолчанию=3
Степень полиномиальной ядерной функции ('poly'). Должна быть неотрицательной. Игнорируется всеми другими ядрами.
- gamma{‘scale’, ‘auto’} или float, по умолчанию='scale'
Коэффициент ядра для 'rbf', 'poly' и 'sigmoid'.
if
gamma='scale'(по умолчанию) передается, тогда используется 1 / (n_features * X.var()) в качестве значения gamma,если 'auto', использует 1 / n_features
если float, должно быть неотрицательным.
Изменено в версии 0.22: Значение по умолчанию для
gammaизменено с 'auto' на 'scale'.- coef0float, по умолчанию=0.0
Независимый член в ядерной функции. Значим только для 'poly' и 'sigmoid'.
- tolfloat, по умолчанию=1e-3
Допуск для критерия остановки.
- nufloat, по умолчанию=0.5
Верхняя граница доли ошибок обучения и нижняя граница доли опорных векторов. Должна находиться в интервале (0, 1]. По умолчанию принимается значение 0.5.
- сжатиеbool, по умолчанию=True
Использовать ли эвристику сжатия. См. Руководство пользователя.
- cache_sizefloat, default=200
Укажите размер кэша ядра (в МБ).
- verbosebool, по умолчанию=False
Включить подробный вывод. Обратите внимание, что этот параметр использует настройку времени выполнения на процесс в libsvm, которая, если включена, может работать некорректно в многопоточном контексте.
- max_iterint, по умолчанию=-1
Жесткое ограничение на итерации внутри решателя, или -1 для отсутствия ограничения.
- Атрибуты:
coef_ndarray формы (1, n_features)Веса, присвоенные признакам, когда
kernel="linear".- dual_coef_ndarray формы (1, n_SV)
Коэффициенты опорных векторов в решающей функции.
- fit_status_int
0, если модель корректно обучена, 1 в противном случае (будет выдано предупреждение)
- intercept_ndarray формы (1,)
Константа в функции принятия решений.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество итераций, выполняемых процедурой оптимизации для обучения модели.
Добавлено в версии 1.1.
n_support_ndarray формы (n_classes,), dtype=int32Количество опорных векторов для каждого класса.
- offset_float
Смещение, используемое для определения решающей функции из исходных оценок. У нас есть соотношение: decision_function = score_samples -
offset_. Смещение является противоположнымintercept_и предоставляется для согласованности с другими алгоритмами обнаружения выбросов.Добавлено в версии 0.20.
- shape_fit_кортеж int формы (n_dimensions_of_X,)
Размерности массива обучающего вектора
X.- support_ndarray формы (n_SV,)
Индексы опорных векторов.
- support_vectors_ndarray формы (n_SV, n_features)
Support vectors.
Смотрите также
sklearn.linear_model.SGDOneClassSVMРешает линейную One-Class SVM с использованием стохастического градиентного спуска.
sklearn.neighbors.LocalOutlierFactorОбнаружение выбросов без учителя с использованием локального фактора выбросов (LOF).
sklearn.ensemble.IsolationForestАлгоритм Isolation Forest.
Примеры
>>> from sklearn.svm import OneClassSVM >>> X = [[0], [0.44], [0.45], [0.46], [1]] >>> clf = OneClassSVM(gamma='auto').fit(X) >>> clf.predict(X) array([-1, 1, 1, 1, -1]) >>> clf.score_samples(X) array([1.7798, 2.0547, 2.0556, 2.0561, 1.7332])
Для более подробного примера, см. Моделирование распределения видов
- decision_function(X)[источник]#
Знаковое расстояние до разделяющей гиперплоскости.
Знаковое расстояние положительно для выброса и отрицательно для аномалии.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Матрица данных.
- Возвращает:
- декndarray формы (n_samples,)
Возвращает функцию принятия решений для образцов.
- fit(X, y=None, sample_weight=None)[источник]#
Обнаружение мягкой границы набора образцов X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Набор выборок, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого образца. Масштабируют C для каждого образца. Более высокие веса заставляют классификатор уделять больше внимания этим точкам.
- Возвращает:
- selfobject
Обученный оценщик.
Примечания
Если X не является массивом с непрерывным порядком C, он копируется.
- fit_predict(X, y=None, **kwargs)[источник]#
Выполнить подгонку на X и вернуть метки для X.
Возвращает -1 для выбросов и 1 для нормальных точек.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные образцы.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **kwargsdict
Аргументы, передаваемые в
fit.Добавлено в версии 1.4.
- Возвращает:
- yndarray формы (n_samples,)
1 для нормальных объектов, -1 для выбросов.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Выполняет классификацию для выборок в X.
Для одноклассовой модели возвращается +1 или -1.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples_test, n_samples_train)
Для kernel="precomputed" ожидаемая форма X (n_samples_test, n_samples_train).
- Возвращает:
- y_predndarray формы (n_samples,)
Метки классов для образцов в X.
- score_samples(X)[источник]#
Необработанная функция оценки выборок.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Матрица данных.
- Возвращает:
- score_samplesndarray формы (n_samples,)
Возвращает (несдвинутую) функцию оценки для выборок.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') OneClassSVM[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
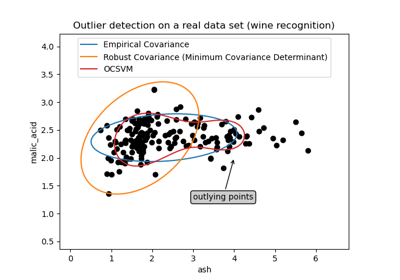
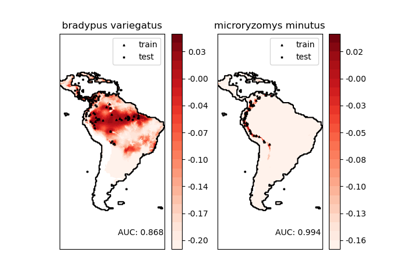
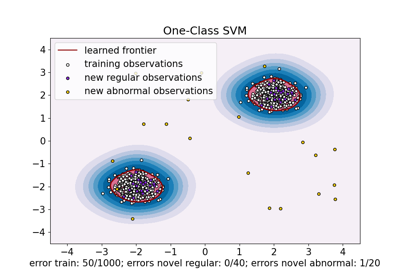
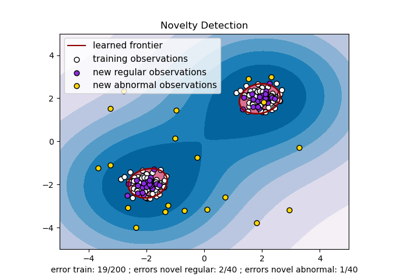
One-Class SVM против One-Class SVM с использованием стохастического градиентного спуска
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных