Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Обнаружение выбросов на реальном наборе данных#
Этот пример иллюстрирует необходимость робастного оценивания ковариации на реальном наборе данных. Это полезно как для обнаружения выбросов, так и для лучшего понимания структуры данных.
Мы выбрали два набора из двух переменных из набора данных Wine в качестве иллюстрации того, какой анализ можно выполнить с помощью нескольких инструментов обнаружения выбросов. Для целей визуализации мы работаем с двумерными примерами, но следует иметь в виду, что в многомерном пространстве все не так просто, как будет указано.
В обоих примерах ниже основной результат заключается в том, что эмпирическая оценка ковариации, будучи не робастной, сильно зависит от неоднородной структуры наблюдений. Хотя робастная оценка ковариации способна фокусироваться на основном режиме распределения данных, она придерживается предположения, что данные должны быть распределены по Гауссу, что даёт некоторую смещённую оценку структуры данных, но всё же точную в определённой степени. One-Class SVM не предполагает никакой параметрической формы распределения данных и поэтому может моделировать сложную форму данных гораздо лучше.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
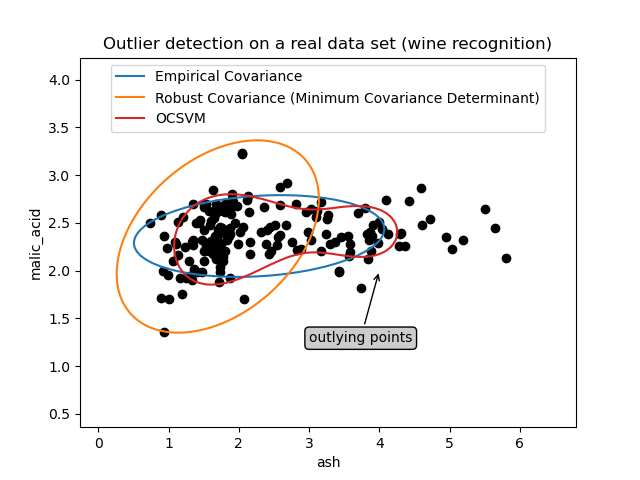
Первый пример#
Первый пример иллюстрирует, как робастный оценщик минимального ковариационного определителя может помочь сконцентрироваться на релевантном кластере при наличии выбросов. Здесь эмпирическая оценка ковариации искажена точками вне основного кластера. Конечно, некоторые инструменты скрининга указали бы на наличие двух кластеров (метод опорных векторов, гауссовские смеси, одномерное обнаружение выбросов, …). Но если бы это был пример высокой размерности, ни один из этих методов не мог бы быть применён так легко.
from sklearn.covariance import EllipticEnvelope
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.svm import OneClassSVM
estimators = {
"Empirical Covariance": EllipticEnvelope(support_fraction=1.0, contamination=0.25),
"Robust Covariance (Minimum Covariance Determinant)": EllipticEnvelope(
contamination=0.25
),
"OCSVM": OneClassSVM(nu=0.25, gamma=0.35),
}
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
X = load_wine()["data"][:, [1, 2]] # two clusters
fig, ax = plt.subplots()
colors = ["tab:blue", "tab:orange", "tab:red"]
# Learn a frontier for outlier detection with several classifiers
legend_lines = []
for color, (name, estimator) in zip(colors, estimators.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
bbox_args = dict(boxstyle="round", fc="0.8")
arrow_args = dict(arrowstyle="->")
ax.annotate(
"outlying points",
xy=(4, 2),
xycoords="data",
textcoords="data",
xytext=(3, 1.25),
bbox=bbox_args,
arrowprops=arrow_args,
)
ax.legend(handles=legend_lines, loc="upper center")
_ = ax.set(
xlabel="ash",
ylabel="malic_acid",
title="Outlier detection on a real data set (wine recognition)",
)
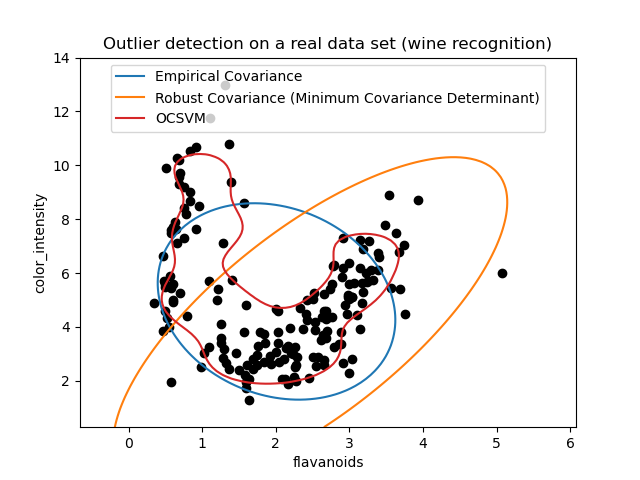
Второй пример#
Второй пример показывает способность робастного оценщика ковариации Minimum Covariance Determinant концентрироваться на основном режиме распределения данных: местоположение, кажется, хорошо оценено, хотя ковариацию трудно оценить из-за бананообразного распределения. В любом случае, мы можем избавиться от некоторых выбросов. One-Class SVM способен захватить реальную структуру данных, но сложность заключается в настройке параметра ширины ядра, чтобы получить хороший компромисс между формой матрицы рассеяния данных и риском переобучения данных.
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
fig, ax = plt.subplots()
colors = ["tab:blue", "tab:orange", "tab:red"]
# Learn a frontier for outlier detection with several classifiers
legend_lines = []
for color, (name, estimator) in zip(colors, estimators.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Outlier detection on a real data set (wine recognition)",
)
plt.show()
Общее время выполнения скрипта: (0 минут 0.445 секунд)
Связанные примеры
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных
Обнаружение выбросов с помощью фактора локальных выбросов (LOF)
Линейный и квадратичный дискриминантный анализ с эллипсоидом ковариации