Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Пример IsolationForest#
Пример использования IsolationForest для обнаружения
аномалий.
The Isolation Forest представляет собой ансамбль "деревьев изоляции", которые "изолируют" наблюдения с помощью рекурсивного случайного разбиения, что может быть представлено древовидной структурой. Количество разбиений, необходимых для изоляции образца, меньше для выбросов и больше для нормальных точек.
В данном примере мы демонстрируем два способа визуализации границы решения Isolation Forest, обученного на игрушечном наборе данных.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Генерация данных#
Мы генерируем два кластера (каждый содержит n_samples) путем случайного
выборки из стандартного нормального распределения, возвращаемого
numpy.random.randn. Один из них сферический, а другой слегка деформирован.
Для согласованности с IsolationForest обозначениях,
выбросы (т.е. гауссовы кластеры) имеют истинную метку 1
тогда как выбросы (созданные с помощью numpy.random.uniform) присваивается
метка -1.
import numpy as np
from sklearn.model_selection import train_test_split
n_samples, n_outliers = 120, 40
rng = np.random.RandomState(0)
covariance = np.array([[0.5, -0.1], [0.7, 0.4]])
cluster_1 = 0.4 * rng.randn(n_samples, 2) @ covariance + np.array([2, 2]) # general
cluster_2 = 0.3 * rng.randn(n_samples, 2) + np.array([-2, -2]) # spherical
outliers = rng.uniform(low=-4, high=4, size=(n_outliers, 2))
X = np.concatenate([cluster_1, cluster_2, outliers])
y = np.concatenate(
[np.ones((2 * n_samples), dtype=int), -np.ones((n_outliers), dtype=int)]
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
Мы можем визуализировать полученные кластеры:
import matplotlib.pyplot as plt
scatter = plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
handles, labels = scatter.legend_elements()
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.title("Gaussian inliers with \nuniformly distributed outliers")
plt.show()

Обучение модели#
from sklearn.ensemble import IsolationForest
clf = IsolationForest(max_samples=100, random_state=0)
clf.fit(X_train)
Построить дискретную границу решений#
Мы используем класс DecisionBoundaryDisplay для визуализации дискретной границы решений. Цвет фона показывает, предсказывается ли образец в данной области как выброс или нет. Точечная диаграмма отображает истинные метки.
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="predict",
alpha=0.5,
)
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
disp.ax_.set_title("Binary decision boundary \nof IsolationForest")
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.show()

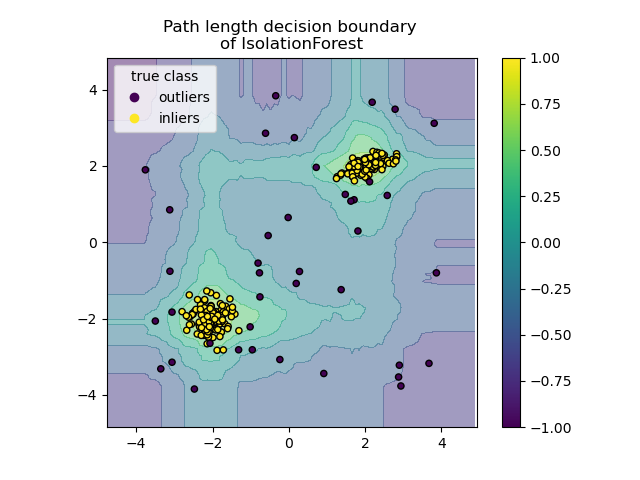
Построить границу принятия решений по длине пути#
Установкой response_method="decision_function", фон
DecisionBoundaryDisplay представляет меру
нормальности наблюдения. Такой показатель задается средней длиной пути
по лесу случайных деревьев, который, в свою очередь, задается глубиной листа
(или, что эквивалентно, количеством разбиений), необходимой для изоляции данного образца.
Когда лес случайных деревьев коллективно создает короткие пути
для изоляции некоторых конкретных образцов, они с высокой вероятностью являются аномалиями, и
мера нормальности близка к 0. Аналогично, большие пути соответствуют значениям, близким к 1 и с большей вероятностью являются инлайерами.
disp = DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
alpha=0.5,
)
disp.ax_.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor="k")
disp.ax_.set_title("Path length decision boundary \nof IsolationForest")
plt.axis("square")
plt.legend(handles=handles, labels=["outliers", "inliers"], title="true class")
plt.colorbar(disp.ax_.collections[1])
plt.show()
Общее время выполнения скрипта: (0 минут 0.406 секунд)
Связанные примеры
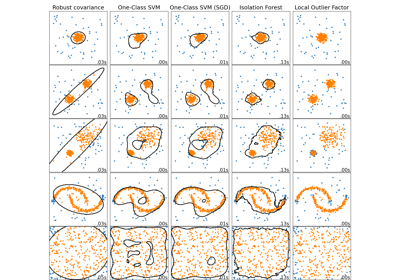
Сравнение алгоритмов обнаружения аномалий для выявления выбросов на игрушечных наборах данных