Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
Последовательные итерации деления пополам#
Этот пример иллюстрирует, как последовательный поиск с уменьшением вдвое (HalvingGridSearchCV и
HalvingRandomSearchCV)
итеративно выбирает наилучшую комбинацию параметров из
нескольких кандидатов.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import randint
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv # noqa: F401
from sklearn.model_selection import HalvingRandomSearchCV
Сначала определяем пространство параметров и обучаем
HalvingRandomSearchCV экземпляр.
rng = np.random.RandomState(0)
X, y = datasets.make_classification(n_samples=400, n_features=12, random_state=rng)
clf = RandomForestClassifier(n_estimators=20, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 6),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
Теперь мы можем использовать cv_results_ атрибут поискового оценщика для проверки
и построения эволюции поиска.
results = pd.DataFrame(rsh.cv_results_)
results["params_str"] = results.params.apply(str)
results.drop_duplicates(subset=("params_str", "iter"), inplace=True)
mean_scores = results.pivot(
index="iter", columns="params_str", values="mean_test_score"
)
ax = mean_scores.plot(legend=False, alpha=0.6)
labels = [
f"iter={i}\nn_samples={rsh.n_resources_[i]}\nn_candidates={rsh.n_candidates_[i]}"
for i in range(rsh.n_iterations_)
]
ax.set_xticks(range(rsh.n_iterations_))
ax.set_xticklabels(labels, rotation=45, multialignment="left")
ax.set_title("Scores of candidates over iterations")
ax.set_ylabel("mean test score", fontsize=15)
ax.set_xlabel("iterations", fontsize=15)
plt.tight_layout()
plt.show()
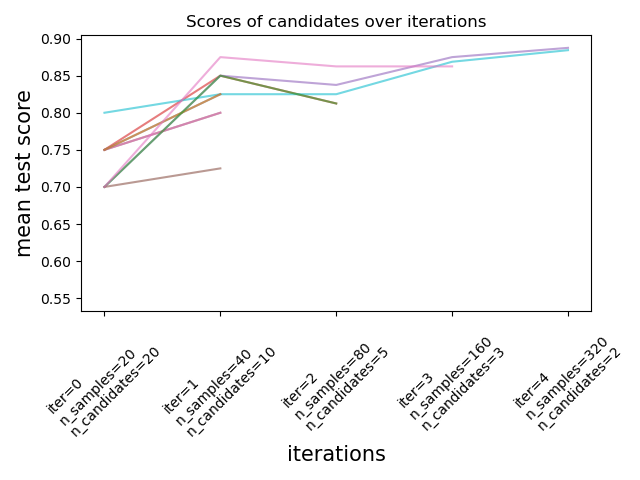
Количество кандидатов и объем ресурса на каждой итерации#
На первой итерации используется небольшое количество ресурсов. Ресурсом здесь является количество образцов, на которых обучаются оценщики. Все кандидаты оцениваются.
На второй итерации оценивается только лучшая половина кандидатов. Количество выделенных ресурсов удваивается: кандидаты оцениваются на удвоенном количестве образцов.
Этот процесс повторяется до последней итерации, где остаются только 2 кандидата. Лучший кандидат — это тот, который имеет наилучший балл на последней итерации.
Общее время выполнения скрипта: (0 минут 6.306 секунд)
Связанные примеры
Сравнение между поиском по сетке и последовательным сокращением вдвое

Сравнение рандомизированного поиска и поиска по сетке для оценки гиперпараметров

Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией