r2_score#
- sklearn.metrics.r2_score(y_true, y_pred, *, sample_weight=None, multioutput='uniform_average', force_finite=True)[источник]#
\(R^2\) (коэффициент детерминации) функция оценки регрессии.
Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). В общем случае, когда истинное y непостоянно, постоянная модель, которая всегда предсказывает среднее y, игнорируя входные признаки, получила бы \(R^2\) оценка 0.0.
В частном случае, когда
y_trueпостоянна, то \(R^2\) оценка не конечна: она либоNaN(идеальные предсказания) или-Inf(несовершенные предсказания). Чтобы предотвратить загрязнение высокоуровневых экспериментов, таких как перекрестная проверка по сетке, этими неконечными числами, по умолчанию эти случаи заменяются на 1.0 (идеальные предсказания) или 0.0 (несовершенные предсказания) соответственно. Вы можете установитьforce_finitetoFalseчтобы предотвратить это исправление.Этот пример также будет работать при замене \(R^2\) оценка идентична
Explained Variance score.Подробнее в Руководство пользователя.
- Параметры:
- y_truearray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные (правильные) целевые значения.
- y_predarray-like формы (n_samples,) или (n_samples, n_outputs)
Оцененные целевые значения.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- multioutput{'raw_values', 'uniform_average', 'variance_weighted'}, array-like формы (n_outputs,) или None, по умолчанию='uniform_average'
Определяет агрегирование нескольких выходных оценок. Значение в виде массива определяет веса, используемые для усреднения оценок. По умолчанию "uniform_average".
- 'raw_values' :
Возвращает полный набор оценок в случае многомерного ввода.
- 'uniform_average' :
Оценки всех выходов усредняются с равномерным весом.
- 'variance_weighted' :
Оценки всех выходов усредняются, взвешенные по дисперсиям каждого отдельного выхода.
Изменено в версии 0.19: Значение по умолчанию для multioutput — 'uniform_average'.
- force_finitebool, по умолчанию=True
Флаг, указывающий, если
NaNи-Infоценки, полученные из постоянных данных, должны быть заменены реальными числами (1.0если предсказание идеально,0.0в противном случае). По умолчаниюTrue, удобная настройка для процедур поиска гиперпараметров (например, поиск по сетке кросс-валидация).Добавлено в версии 1.1.
- Возвращает:
- zfloat или ndarray из floats
The \(R^2\) оценка или ndarray оценок, если 'multioutput' равен 'raw_values'.
Примечания
Это не симметричная функция.
В отличие от большинства других оценок, \(R^2\) оценка может быть отрицательной (она не обязательно должна быть квадратом величины R).
Эта метрика не определена для отдельных выборок и вернет значение NaN, если n_samples меньше двух.
Ссылки
Примеры
>>> from sklearn.metrics import r2_score >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> r2_score(y_true, y_pred) 0.948... >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> r2_score(y_true, y_pred, ... multioutput='variance_weighted') 0.938... >>> y_true = [1, 2, 3] >>> y_pred = [1, 2, 3] >>> r2_score(y_true, y_pred) 1.0 >>> y_true = [1, 2, 3] >>> y_pred = [2, 2, 2] >>> r2_score(y_true, y_pred) 0.0 >>> y_true = [1, 2, 3] >>> y_pred = [3, 2, 1] >>> r2_score(y_true, y_pred) -3.0 >>> y_true = [-2, -2, -2] >>> y_pred = [-2, -2, -2] >>> r2_score(y_true, y_pred) 1.0 >>> r2_score(y_true, y_pred, force_finite=False) nan >>> y_true = [-2, -2, -2] >>> y_pred = [-2, -2, -2 + 1e-8] >>> r2_score(y_true, y_pred) 0.0 >>> r2_score(y_true, y_pred, force_finite=False) -inf
Примеры галереи#
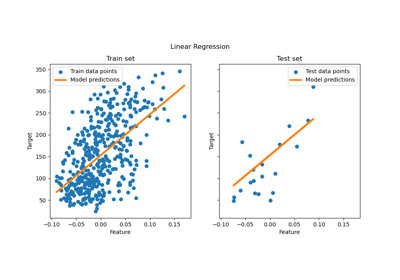
Эффект преобразования целей в регрессионной модели
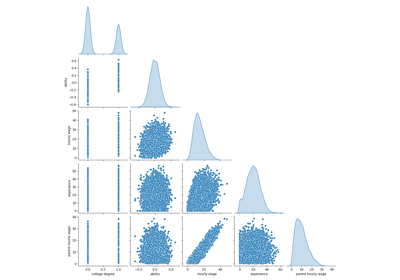
Неспособность машинного обучения выводить причинно-следственные связи
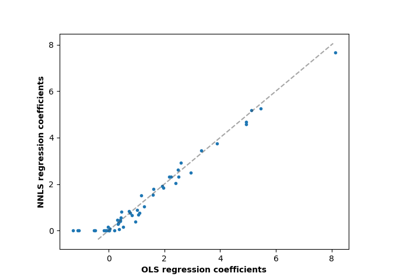
Метод наименьших квадратов с неотрицательными ограничениями