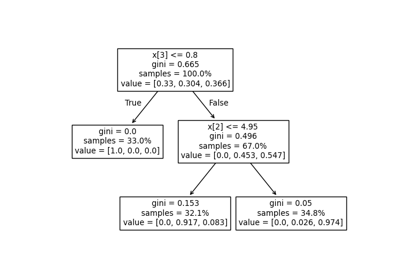
train_test_split#
- sklearn.model_selection.train_test_split(*массивы, test_size=None, train_size=None, random_state=None, перемешивание=True, stratify=None)[источник]#
Разделить массивы или матрицы на случайные обучающую и тестовую подвыборки.
Быстрая утилита, которая оборачивает проверку входных данных,
next(ShuffleSplit().split(X, y)), и применение к входным данным в один вызов для разделения (и, возможно, субдискретизации) данных в одну строку.Подробнее в Руководство пользователя.
- Параметры:
- *arraysпоследовательность индексируемых объектов с одинаковой длиной / shape[0]
Допустимые входные данные: списки, массивы numpy, разреженные матрицы scipy или фреймы данных pandas.
- test_sizefloat или int, по умолчанию=None
Если float, должно быть между 0.0 и 1.0 и представлять долю набора данных для включения в тестовое разделение. Если int, представляет абсолютное количество тестовых выборок. Если None, значение устанавливается как дополнение к размеру обучающей выборки. Если
train_sizeтакже None, он будет установлен в 0.25.- train_sizefloat или int, по умолчанию=None
Если float, должно быть между 0.0 и 1.0 и представлять долю набора данных для включения в обучающее разбиение. Если int, представляет абсолютное число обучающих выборок. Если None, значение автоматически устанавливается как дополнение к размеру тестовой выборки.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет перемешиванием, применяемым к данным перед разделением. Передайте целое число для воспроизводимого результата при нескольких вызовах функции. См. Глоссарий.
- перемешиваниеbool, по умолчанию=True
Перемешивать ли данные перед разделением. Если shuffle=False, то stratify должен быть None.
- stratifyarray-like, default=None
Если не None, данные разделяются стратифицированно, используя это как метки классов. Подробнее в Руководство пользователя.
- Возвращает:
- разделениесписок, длина=2 * len(arrays)
Список, содержащий разделение обучающих и тестовых данных входов.
Добавлено в версии 0.16: Если вход разреженный, выход будет
scipy.sparse.csr_matrix. В противном случае тип вывода такой же, как тип ввода.
Примеры
>>> import numpy as np >>> from sklearn.model_selection import train_test_split >>> X, y = np.arange(10).reshape((5, 2)), range(5) >>> X array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]]) >>> list(y) [0, 1, 2, 3, 4]
>>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, test_size=0.33, random_state=42) ... >>> X_train array([[4, 5], [0, 1], [6, 7]]) >>> y_train [2, 0, 3] >>> X_test array([[2, 3], [8, 9]]) >>> y_test [1, 4]
>>> train_test_split(y, shuffle=False) [[0, 1, 2], [3, 4]]
>>> from sklearn import datasets >>> iris = datasets.load_iris(as_frame=True) >>> X, y = iris['data'], iris['target'] >>> X.head() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 >>> y.head() 0 0 1 0 2 0 3 0 4 0 ...
>>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, test_size=0.33, random_state=42) ... >>> X_train.head() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 96 5.7 2.9 4.2 1.3 105 7.6 3.0 6.6 2.1 66 5.6 3.0 4.5 1.5 0 5.1 3.5 1.4 0.2 122 7.7 2.8 6.7 2.0 >>> y_train.head() 96 1 105 2 66 1 0 0 122 2 ... >>> X_test.head() sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 73 6.1 2.8 4.7 1.2 18 5.7 3.8 1.7 0.3 118 7.7 2.6 6.9 2.3 78 6.0 2.9 4.5 1.5 76 6.8 2.8 4.8 1.4 >>> y_test.head() 73 1 18 0 118 2 78 1 76 1 ...
Примеры галереи#

Удаление шума с изображения с использованием ядерного PCA
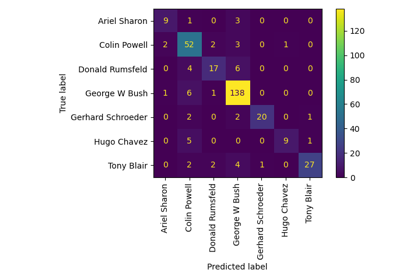
Пример распознавания лиц с использованием собственных лиц и SVM

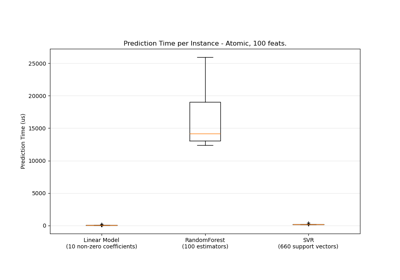
Лаггированные признаки для прогнозирования временных рядов

Эффект преобразования целей в регрессионной модели
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов
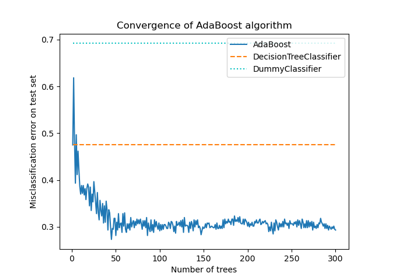
Многоклассовые деревья решений с бустингом AdaBoost
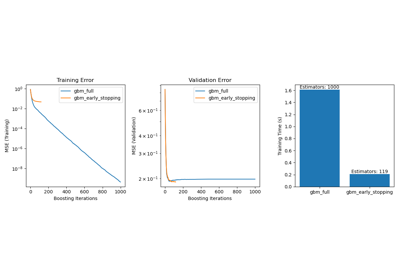
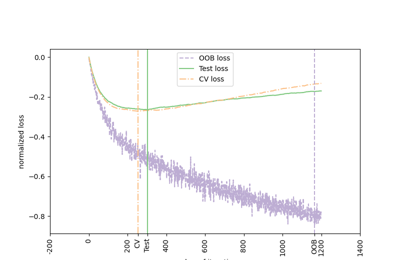

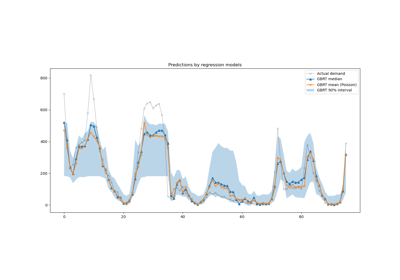
Интервалы прогнозирования для регрессии градиентного бустинга


Признаки в деревьях с градиентным бустингом на гистограммах

Сравнение случайных лесов и мета-оценщика с множественным выходом


Неспособность машинного обучения выводить причинно-следственные связи

Распространённые ошибки в интерпретации коэффициентов линейных моделей
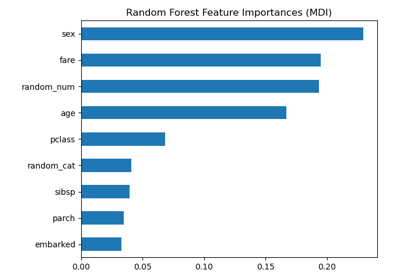
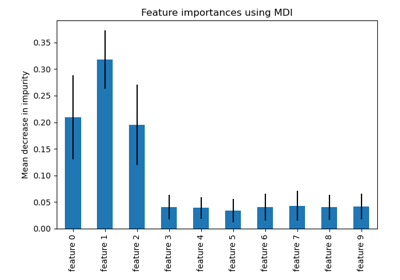
Важность перестановок против важности признаков случайного леса (MDI)
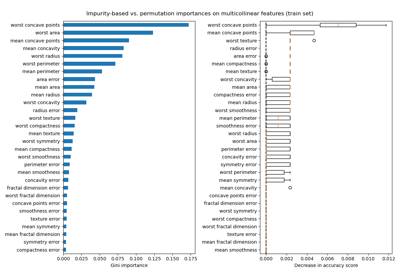
Важность перестановок с мультиколлинеарными или коррелированными признаками

Масштабируемое обучение с полиномиальной аппроксимацией ядра
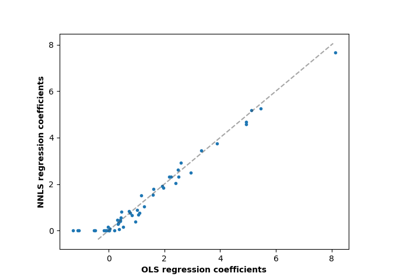
Метод наименьших квадратов с неотрицательными ограничениями
Ранняя остановка стохастического градиентного спуска
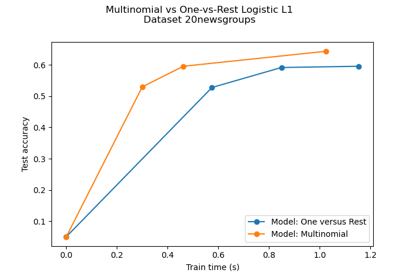
Многоклассовая разреженная логистическая регрессия на 20newsgroups
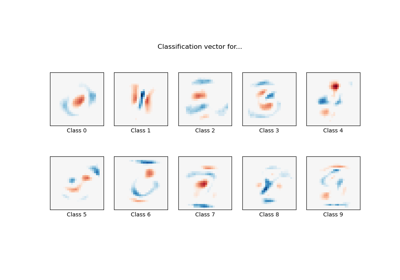
Классификация MNIST с использованием мультиномиальной логистической регрессии + L1


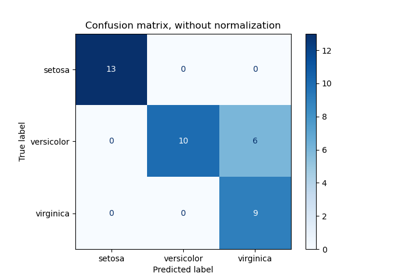
Оценить производительность классификатора с помощью матрицы ошибок
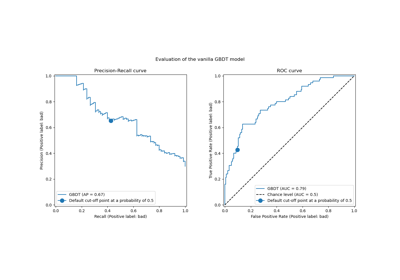
Последующая настройка порога принятия решений для обучения с учетом стоимости

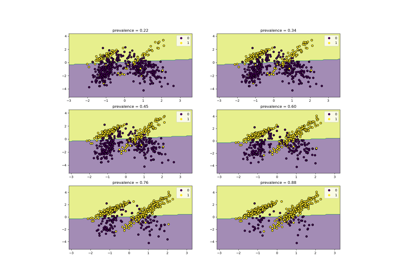
Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией
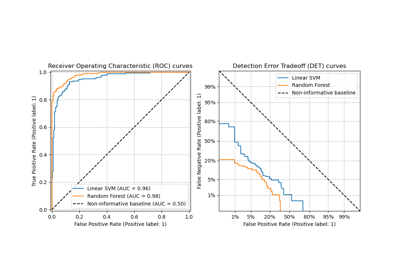
Многоклассовая рабочая характеристика приемника (ROC)

Влияние регуляризации модели на ошибку обучения и тестирования
Многометочная классификация с использованием цепочки классификаторов
Сравнение ближайших соседей с анализом компонент соседства и без него
Снижение размерности с помощью анализа компонентов соседства
Изменение регуляризации в многослойном перцептроне


Признаки ограниченной машины Больцмана для классификации цифр

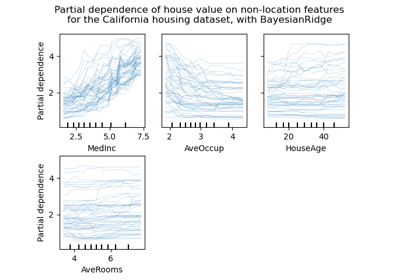
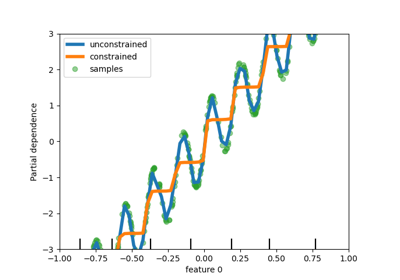
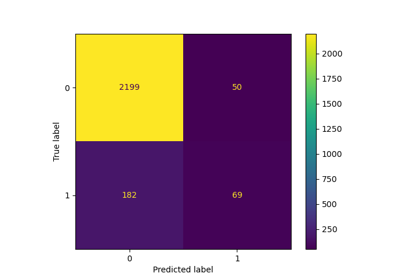
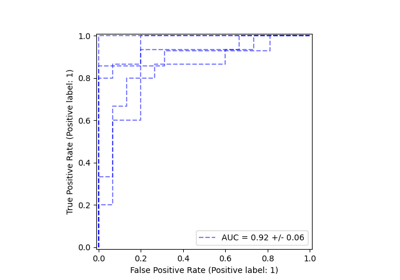
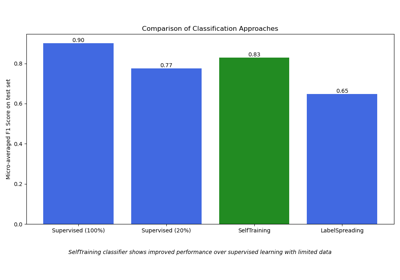
Полу-контролируемая классификация на текстовом наборе данных

Пост-обрезка деревьев решений с обрезкой по стоимости сложности