GridSearchCV#
- класс sklearn.model_selection.GridSearchCV(estimator, param_grid, *, оценка=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score=nan, return_train_score=False)[источник]#
Полный перебор по заданным значениям параметров для оценщика.
Важные методы: fit, predict.
GridSearchCV реализует методы "fit" и "score". Также реализует "score_samples", "predict", "predict_proba", "decision_function", "transform" и "inverse_transform", если они реализованы в используемом оценщике.
Параметры оценщика, используемые для применения этих методов, оптимизируются с помощью перекрестной проверки и поиска по сетке параметров.
Подробнее в Руководство пользователя.
- Параметры:
- estimatorобъект оценщика
Предполагается, что это реализует интерфейс оценщика scikit-learn. Любой оценщик должен предоставлять
scoreфункция, илиscoringдолжен быть передан.- param_gridсловарь или список словарей
Словарь с именами параметров (
str) в качестве ключей и списки настроек параметров для перебора в качестве значений, или список таких словарей, в этом случае исследуются сетки, охватываемые каждым словарем в списке. Это позволяет осуществлять поиск по любой последовательности настроек параметров.- оценкаstr, callable, list, tuple или dict, по умолчанию=None
Стратегия для оценки производительности перекрестно проверенной модели на тестовом наборе.
Если
scoringпредставляет собой единичную оценку, можно использовать:одна строка (см. Строковые имена скореров);
вызываемый объект (см. Вызываемые скореры), которая возвращает одно значение;
None,estimator’s критерий оценки по умолчанию используется.
Если
scoringпредставляет несколько оценок, можно использовать:список или кортеж уникальных строк;
вызываемый объект, возвращающий словарь, где ключи — это имена метрик, а значения — оценки метрик;
словарь с именами метрик в качестве ключей и вызываемыми объектами в качестве значений.
См. Указание нескольких метрик для оценки для примера.
- n_jobsint, default=None
Количество параллельно выполняемых задач.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.Изменено в версии v0.20:
n_jobsзначение по умолчанию изменено с 1 на None- refitbool, str или callable, по умолчанию=True
Переобучите оценщик с использованием наилучших найденных параметров на всем наборе данных.
Для множественной метрической оценки это должно быть
strобозначая оценщик, который будет использоваться для поиска лучших параметров для повторной подгонки оценщика в конце.Когда при выборе лучшего оценщика учитываются факторы, отличные от максимальной оценки,
refitможет быть установлена в функцию, которая возвращает выбранныйbest_index_заданcv_results_. В этом случае,best_estimator_иbest_params_будет установлен в соответствии с возвращённымbest_index_в то время какbest_score_атрибут будет недоступен.Переобученный оценщик доступен в
best_estimator_атрибут и позволяет использоватьpredictнепосредственно на этомGridSearchCVэкземпляр.Также для оценки по нескольким метрикам атрибуты
best_index_,best_score_иbest_params_будет доступен только еслиrefitустановлен, и все они будут определены относительно этого конкретного оценщика.См.
scoringпараметр, чтобы узнать больше о множественной метрической оценке.См. Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией чтобы увидеть, как разработать пользовательскую стратегию выбора с использованием вызываемого объекта через
refit.См. этот пример для примера использования
refit=callableдля балансировки сложности модели и кросс-валидированной оценки.Изменено в версии 0.20: Добавлена поддержка callable.
- cvint, генератор кросс-валидации или итерируемый объект, по умолчанию=None
Определяет стратегию разделения для перекрестной проверки. Возможные значения для cv:
None, чтобы использовать стандартную 5-кратную перекрестную проверку,
целое число, чтобы указать количество фолдов в
(Stratified)KFold,Итерируемый объект, возвращающий (обучающие, тестовые) разбиения в виде массивов индексов.
Для целочисленных/None входных данных, если оценщик является классификатором и
yявляется либо бинарным, либо многоклассовым,StratifiedKFoldиспользуется. Во всех остальных случаяхKFoldиспользуется. Эти сплиттеры создаются сshuffle=Falseтак что разбиения будут одинаковыми при всех вызовах.Обратитесь Руководство пользователя для различных стратегий перекрестной проверки, которые можно использовать здесь.
Изменено в версии 0.22:
cvзначение по умолчанию, если None изменено с 3-кратного на 5-кратное.- verboseint
Управляет подробностью вывода: чем выше, тем больше сообщений.
>1 : время вычисления для каждого фолда и кандидата параметра отображается;
>2 : оценка также отображается;
>3 : индексы свертки и кандидатных параметров также отображаются вместе со временем начала вычисления.
- pre_dispatchint, или str, по умолчанию='2*n_jobs'
Управляет количеством задач, отправляемых во время параллельного выполнения. Уменьшение этого числа может быть полезно для избежания взрыва потребления памяти, когда отправляется больше задач, чем процессоров может обработать. Этот параметр может быть:
None, в этом случае все задачи немедленно создаются и запускаются. Используйте это для легковесных и быстро выполняемых задач, чтобы избежать задержек из-за запуска задач по требованию
Целое число, указывающее точное количество создаваемых заданий
Строка, дающая выражение как функцию от n_jobs, например, '2*n_jobs'
- error_score'raise' или числовое, по умолчанию=np.nan
Значение для присвоения оценке, если возникает ошибка при обучении оценщика. Если установлено 'raise', ошибка вызывается. Если задано числовое значение, вызывается FitFailedWarning. Этот параметр не влияет на шаг повторного обучения, который всегда будет вызывать ошибку.
- return_train_scorebool, по умолчанию=False
Если
False,cv_results_атрибут не будет включать оценки обучения. Вычисление оценок обучения используется для получения представления о том, как различные настройки параметров влияют на компромисс переобучения/недообучения. Однако вычисление оценок на обучающем наборе может быть вычислительно затратным и не является строго необходимым для выбора параметров, которые дают наилучшую производительность обобщения.Добавлено в версии 0.19.
Изменено в версии 0.21: Значение по умолчанию было изменено с
TruetoFalse
- Атрибуты:
- cv_results_словарь numpy (маскированных) ndarrays
Словарь с ключами в качестве заголовков столбцов и значениями в качестве столбцов, который можно импортировать в pandas
DataFrame.Например, приведенная ниже таблица
param_kernel
param_gamma
param_degree
split0_test_score
…
rank_t…
'poly'
–
2
0.80
…
2
'poly'
–
3
0.70
…
4
'rbf'
0.1
–
0.80
…
3
'rbf'
0.2
–
0.93
…
1
будет представлен как
cv_results_словарь:{ 'param_kernel': masked_array(data = ['poly', 'poly', 'rbf', 'rbf'], mask = [False False False False]...) 'param_gamma': masked_array(data = [-- -- 0.1 0.2], mask = [ True True False False]...), 'param_degree': masked_array(data = [2.0 3.0 -- --], mask = [False False True True]...), 'split0_test_score' : [0.80, 0.70, 0.80, 0.93], 'split1_test_score' : [0.82, 0.50, 0.70, 0.78], 'mean_test_score' : [0.81, 0.60, 0.75, 0.85], 'std_test_score' : [0.01, 0.10, 0.05, 0.08], 'rank_test_score' : [2, 4, 3, 1], 'split0_train_score' : [0.80, 0.92, 0.70, 0.93], 'split1_train_score' : [0.82, 0.55, 0.70, 0.87], 'mean_train_score' : [0.81, 0.74, 0.70, 0.90], 'std_train_score' : [0.01, 0.19, 0.00, 0.03], 'mean_fit_time' : [0.73, 0.63, 0.43, 0.49], 'std_fit_time' : [0.01, 0.02, 0.01, 0.01], 'mean_score_time' : [0.01, 0.06, 0.04, 0.04], 'std_score_time' : [0.00, 0.00, 0.00, 0.01], 'params' : [{'kernel': 'poly', 'degree': 2}, ...], }
Для примера визуализации и интерпретации результатов GridSearch, см. Статистическое сравнение моделей с использованием поиска по сетке.
ПРИМЕЧАНИЕ
Ключ
'params'используется для хранения списка словарей настроек параметров для всех кандидатов параметров.The
mean_fit_time,std_fit_time,mean_score_timeиstd_score_timeвсе в секундах.Для многометрической оценки оценки всех скореров доступны в
cv_results_словарь по ключам, оканчивающимся на имя этого оценщика ('_) вместо' '_score'показано выше. (‘split0_test_precision’, ‘mean_train_precision’ и т.д.)- best_estimator_estimator
Оценщик, выбранный поиском, т.е. оценщик, который дал наивысший балл (или наименьшие потери, если указано) на отложенных данных. Недоступно, если
refit=False.См.
refitпараметр для получения дополнительной информации о допустимых значениях.- best_score_float
Средний перекрёстно-валидированный счёт лучшего_оценщика
Для многометрической оценки это присутствует только если
refitуказано.Этот атрибут недоступен, если
refitявляется функцией.- best_params_dict
Настройка параметров, которая дала наилучшие результаты на отложенных данных.
Для многометрической оценки это присутствует только если
refitуказано.- best_index_int
Индекс (из
cv_results_массивы), которые соответствуют наилучшей настройке параметров кандидата.Словарь в
search.cv_results_['params'][search.best_index_]даёт настройку параметров для лучшей модели, которая даёт наивысшее среднее значение оценки (search.best_score_).Для многометрической оценки это присутствует только если
refitуказано.- scorer_функция или словарь
Функция оценки, используемая на отложенных данных для выбора лучших параметров модели.
Для многометрической оценки этот атрибут содержит проверенный
scoringсловарь, который сопоставляет ключ оценщика с вызываемым объектом оценщика.- n_splits_int
Количество разбиений перекрестной проверки (фолдов/итераций).
- время повторного обученияfloat
Секунды, затраченные на переобучение лучшей модели на всем наборе данных.
Это присутствует только если
refitне является False.Добавлено в версии 0.20.
- multimetric_bool
Вычисляют ли скореры несколько метрик.
classes_ndarray формы (n_classes,)Метки классов.
n_features_in_intКоличество признаков, замеченных во время fit.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только если
best_estimator_определен (см. документацию дляrefitпараметр для получения дополнительных сведений) и чтоbest_estimator_предоставляетfeature_names_in_при обучении.Добавлено в версии 1.0.
Смотрите также
ParameterGridГенерирует все комбинации сетки гиперпараметров.
train_test_splitВспомогательная функция для разделения данных на набор разработки, пригодный для подбора экземпляра GridSearchCV, и набор оценки для его финальной оценки.
sklearn.metrics.make_scorerСоздать оценщик из метрики производительности или функции потерь.
Примечания
Выбранные параметры — это те, которые максимизируют оценку на исключенных данных, если только не передана явная оценка, в этом случае она используется вместо этого.
Если
n_jobsбыло установлено значение больше единицы, данные копируются для каждой точки сетки (а неn_jobsраз). Это делается для повышения эффективности, если отдельные задачи занимают очень мало времени, но может вызывать ошибки, если набор данных большой и доступно недостаточно памяти. Обходным решением в этом случае является установкаpre_dispatchЗатем память копируется толькоpre_dispatchмного раз. Разумное значение дляpre_dispatchявляется2 * n_jobs.Примеры
>>> from sklearn import svm, datasets >>> from sklearn.model_selection import GridSearchCV >>> iris = datasets.load_iris() >>> parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]} >>> svc = svm.SVC() >>> clf = GridSearchCV(svc, parameters) >>> clf.fit(iris.data, iris.target) GridSearchCV(estimator=SVC(), param_grid={'C': [1, 10], 'kernel': ('linear', 'rbf')}) >>> sorted(clf.cv_results_.keys()) ['mean_fit_time', 'mean_score_time', 'mean_test_score',... 'param_C', 'param_kernel', 'params',... 'rank_test_score', 'split0_test_score',... 'split2_test_score', ... 'std_fit_time', 'std_score_time', 'std_test_score']
- decision_function(X)[источник]#
Вызовите decision_function у оценщика с наилучшими найденными параметрами.
Доступно только если
refit=Trueи базовый оценчик поддерживаетdecision_function.- Параметры:
- Xиндексируемый, длина n_samples
Должен соответствовать входным предположениям базового оценщика.
- Возвращает:
- y_scorendarray формы (n_samples,) или (n_samples, n_classes) или (n_samples, n_classes * (n_classes-1) / 2)
Результат функции принятия решений для
Xна основе оценщика с наилучшими найденными параметрами.
- fit(X, y=None, **params)[источник]#
Запустите fit со всеми наборами параметров.
- Параметры:
- Xмассивоподобный объект формы (n_samples, n_features) или (n_samples, n_samples)
Обучающие векторы, где
n_samples— это количество образцов иn_features— количество признаков. Для предварительно вычисленного ядра или матрицы расстояний ожидаемая форма X — (n_samples, n_samples).- yarray-like формы (n_samples, n_output) или (n_samples,), по умолчанию=None
Целевая переменная относительно X для классификации или регрессии; None для обучения без учителя.
- **paramsdict of str -> object
Параметры, передаваемые в
fitметод оценщика, оценщик, и разделитель CV.Если параметр подгонки является массивоподобным объектом, длина которого равна
num_samplesто он будет разделен с помощью перекрестной проверки вместе сXиy. Например, sample_weight параметр разделяется, потому чтоlen(sample_weights) = len(X). Однако это поведение не применяется кgroupsкоторый передается разделителю, настроенному черезcvпараметр конструктора. Таким образом,groupsиспользуется для выполнения разделения и определяет, какие образцы назначаются на каждую сторону разделения.
- Возвращает:
- selfobject
Экземпляр обученного оценщика.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.4.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Вызовите inverse_transform для оценщика с наилучшими найденными параметрами.
Доступно только если базовый оценщик реализует
inverse_transformиrefit=True.- Параметры:
- Xиндексируемый, длина n_samples
Должен соответствовать входным предположениям базового оценщика.
- Возвращает:
- X_original{ndarray, разреженная матрица} формы (n_samples, n_features)
Результат
inverse_transformфункция дляXна основе оценщика с наилучшими найденными параметрами.
- predict(X)[источник]#
Вызвать predict на оценщике с наилучшими найденными параметрами.
Доступно только если
refit=Trueи базовый оценчик поддерживаетpredict.- Параметры:
- Xиндексируемый, длина n_samples
Должен соответствовать входным предположениям базового оценщика.
- Возвращает:
- y_predndarray формы (n_samples,)
Предсказанные метки или значения для
Xна основе оценщика с наилучшими найденными параметрами.
- predict_log_proba(X)[источник]#
Вызовите predict_log_proba на оценщике с наилучшими найденными параметрами.
Доступно только если
refit=Trueи базовый оценчик поддерживаетpredict_log_proba.- Параметры:
- Xиндексируемый, длина n_samples
Должен соответствовать входным предположениям базового оценщика.
- Возвращает:
- y_predndarray формы (n_samples,) или (n_samples, n_classes)
Предсказанные логарифмические вероятности классов для
Xна основе оценщика с наилучшими найденными параметрами. Порядок классов соответствует порядку во встроенном атрибуте classes_.
- predict_proba(X)[источник]#
Вызвать predict_proba у оценщика с наилучшими найденными параметрами.
Доступно только если
refit=Trueи базовый оценчик поддерживаетpredict_proba.- Параметры:
- Xиндексируемый, длина n_samples
Должен соответствовать входным предположениям базового оценщика.
- Возвращает:
- y_predndarray формы (n_samples,) или (n_samples, n_classes)
Предсказанные вероятности классов для
Xна основе модели с наилучшими найденными параметрами. Порядок классов соответствует порядку в обученном атрибуте classes_.
- score(X, y=None, **params)[источник]#
Возвращает оценку на заданных данных, если оценщик был переобучен.
Это использует оценку, определенную
scoringгде предоставлено, иbest_estimator_.scoreметод в противном случае.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные данные, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples, n_output) или (n_samples,), по умолчанию=None
Целевая переменная относительно X для классификации или регрессии; None для обучения без учителя.
- **paramsdict
Параметры, передаваемые в базовый оценщик(и).
Добавлено в версии 1.4: Доступно только если
enable_metadata_routing=True. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- scorefloat
Оценка, определяемая
scoringесли предоставлен, иbest_estimator_.scoreметод в противном случае.
- score_samples(X)[источник]#
Вызовите score_samples на оценщике с наилучшими найденными параметрами.
Доступно только если
refit=Trueи базовый оценчик поддерживаетscore_samples.Добавлено в версии 0.24.
- Параметры:
- Xитерируемый объект
Данные для предсказания. Должны удовлетворять входным требованиям базового оценщика.
- Возвращает:
- y_scorendarray формы (n_samples,)
The
best_estimator_.score_samplesметод.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Вызовите transform на оценщике с наилучшими найденными параметрами.
Доступно только если базовый оценщик поддерживает
transformиrefit=True.- Параметры:
- Xиндексируемый, длина n_samples
Должен соответствовать входным предположениям базового оценщика.
- Возвращает:
- Xt{ndarray, разреженная матрица} формы (n_samples, n_features)
Xпреобразованы в новом пространстве на основе оценщика с наилучшими найденными параметрами.
Примеры галереи#

Выбор уменьшения размерности с помощью Pipeline и GridSearchCV
Конвейеризация: объединение PCA и логистической регрессии

Объединение нескольких методов извлечения признаков
Оценка ковариации сжатием: LedoitWolf vs OAS и максимальное правдоподобие

Выбор модели с вероятностным PCA и факторным анализом (FA)

Сравнение моделей случайных лесов и градиентного бустинга на гистограммах


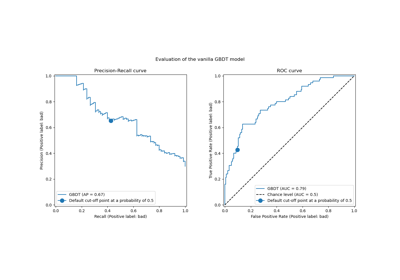
Последующая настройка порога принятия решений для обучения с учетом стоимости

Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией
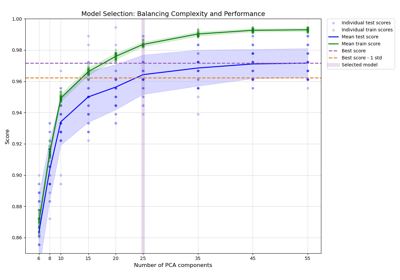
Баланс сложности модели и кросс-валидационной оценки
Статистическое сравнение моделей с использованием поиска по сетке

Примерный пайплайн для извлечения и оценки текстовых признаков
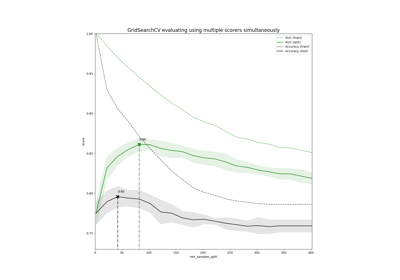
Демонстрация многометрической оценки на cross_val_score и GridSearchCV


Сравнение рандомизированного поиска и поиска по сетке для оценки гиперпараметров
Сравнение между поиском по сетке и последовательным сокращением вдвое

Построение границ классификации с различными ядрами SVM