RandomForestRegressor#
- класс sklearn.ensemble.RandomForestRegressor(n_estimators=100, *, критерий='squared_error', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=1.0, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None, monotonic_cst=None)[источник]#
Регрессор случайного леса.
Случайный лес — это мета-оценщик, который обучает несколько регрессоров дерева решений на различных подвыборках набора данных и использует усреднение для улучшения прогностической точности и контроля переобучения. Деревья в лесу используют стратегию наилучшего разделения, т.е. эквивалентно передаче
splitter="best"к лежащему в основеDecisionTreeRegressor. Размер подвыборки контролируется с помощьюmax_samplesпараметр еслиbootstrap=True(по умолчанию), в противном случае весь набор данных используется для построения каждого дерева.Этот оценщик имеет встроенную поддержку пропущенных значений (NaN). Во время обучения алгоритм построения дерева изучает на каждой точке разделения, должны ли выборки с пропущенными значениями идти в левого или правого потомка, на основе потенциального выигрыша. При прогнозировании выборки с пропущенными значениями соответственно назначаются левому или правому потомку. Если во время обучения для данного признака не встречались пропущенные значения, то выборки с пропущенными значениями направляются к тому потомку, у которого больше выборок.
Для сравнения ансамблевых моделей на основе деревьев см. пример Сравнение моделей случайных лесов и градиентного бустинга на гистограммах.
Подробнее в Руководство пользователя.
- Параметры:
- n_estimatorsint, по умолчанию=100
Количество деревьев в лесу.
Изменено в версии 0.22: Значение по умолчанию для
n_estimatorsизменено с 10 на 100 в версии 0.22.- критерий{“squared_error”, “absolute_error”, “friedman_mse”, “poisson”}, по умолчанию=”squared_error”
Функция для измерения качества разделения. Поддерживаемые критерии: "squared_error" для среднеквадратичной ошибки, которая равна снижению дисперсии как критерию выбора признаков и минимизирует потерю L2 с использованием среднего значения каждого терминального узла, "friedman_mse", который использует среднеквадратичную ошибку с улучшенным счетом Фридмана для потенциальных разделений, "absolute_error" для средней абсолютной ошибки, которая минимизирует потерю L1 с использованием медианы каждого терминального узла, и "poisson", который использует снижение девиансы Пуассона для поиска разделений. Обучение с использованием "absolute_error" значительно медленнее, чем при использовании "squared_error".
Добавлено в версии 0.18: Критерий средней абсолютной ошибки (MAE).
Добавлено в версии 1.0: Критерий Пуассона.
- max_depthint, default=None
Максимальная глубина дерева. Если None, то узлы расширяются до тех пор, пока все листья не станут чистыми или пока все листья не будут содержать менее min_samples_split выборок.
- min_samples_splitint или float, по умолчанию=2
Минимальное количество образцов, необходимое для разделения внутреннего узла:
Если int, то рассматривать
min_samples_splitкак минимальное число.Если float, то
min_samples_splitявляется дробью иceil(min_samples_split * n_samples)минимальное количество образцов для каждого разделения.
Изменено в версии 0.18: Добавлены дробные значения.
- min_samples_leafint или float, по умолчанию=1
Минимальное количество выборок, требуемое для нахождения в листовом узле. Точка разделения на любой глубине будет рассматриваться только если она оставляет по крайней мере
min_samples_leafобучающих выборок в каждой из левой и правой ветвей. Это может сгладить модель, особенно в регрессии.Если int, то рассматривать
min_samples_leafкак минимальное число.Если float, то
min_samples_leafявляется дробью иceil(min_samples_leaf * n_samples)являются минимальным количеством образцов для каждого узла.
Изменено в версии 0.18: Добавлены дробные значения.
- min_weight_fraction_leaffloat, по умолчанию=0.0
Минимальная взвешенная доля от общей суммы весов (всех входных выборок), требуемая для листового узла. Выборки имеют равный вес, когда sample_weight не предоставлен.
- max_features{“sqrt”, “log2”, None}, int или float, по умолчанию=1.0
Количество признаков, которые следует учитывать при поиске наилучшего разделения:
Если int, то рассматривать
max_featuresпризнаков на каждом разбиении.Если float, то
max_featuresявляется дробью иmax(1, int(max_features * n_features_in_))признаков рассматривается на каждом разделении.Если "sqrt", то
max_features=sqrt(n_features).Если "log2", то
max_features=log2(n_features).Если None или 1.0, то
max_features=n_features.
Примечание
Значение по умолчанию 1.0 эквивалентно деревьям с бэггингом, и большая случайность может быть достигнута установкой меньших значений, например 0.3.
Изменено в версии 1.1: Значение по умолчанию для
max_featuresизменено с"auto"до 1.0.Истинные (правильные) целевые значения. Требуется y_true > 0.
max_featuresпризнаков.- max_leaf_nodesint, default=None
Выращивайте деревья с
max_leaf_nodesв порядке лучшего первого. Лучшие узлы определяются как относительное снижение неоднородности. Если None, то неограниченное количество листовых узлов.- min_impurity_decreasefloat, по умолчанию=0.0
Узел будет разделен, если это разделение вызывает уменьшение неопределенности, большее или равное этому значению.
Уравнение взвешенного уменьшения неопределённости следующее:
N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)
где
N— это общее количество выборок,N_t— это количество выборок в текущем узле,N_t_L— это количество образцов в левом дочернем узле, иN_t_Rэто количество выборок в правом дочернем узле.N,N_t,N_t_RиN_t_Lвсе относятся к взвешенной сумме, еслиsample_weightпередается.Добавлено в версии 0.19.
- bootstrapbool, по умолчанию=True
Используются ли бутстрап-выборки при построении деревьев. Если False, весь набор данных используется для построения каждого дерева.
- oob_scorebool или callable, default=False
Использовать ли внепакетные образцы для оценки обобщающей способности. По умолчанию,
r2_scoreиспользуется. Предоставьте вызываемый объект с сигнатуройmetric(y_true, y_pred)использовать пользовательскую метрику. Доступно только еслиbootstrap=True.Для иллюстрации оценки ошибки вне пакета (OOB) см. пример Ошибки OOB для случайных лесов.
- n_jobsint, default=None
Количество параллельно выполняемых задач.
fit,predict,decision_pathиapplyвсе параллелизованы по деревьям.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет как случайностью бутстрэппинга выборок, используемых при построении деревьев (если
bootstrap=True) и выборки признаков для рассмотрения при поиске наилучшего разделения в каждом узле (еслиmax_features < n_features). См. Глоссарий подробности.- verboseint, по умолчанию=0
Управляет подробностью вывода при обучении и предсказании.
- warm_startbool, по умолчанию=False
При установке значения
True, повторно использовать решение предыдущего вызова fit и добавить больше оценщиков в ансамбль, в противном случае просто обучить полностью новый лес. См. Глоссарий и Добавление дополнительных деревьев подробности.- ccp_alphaнеотрицательное число с плавающей точкой, default=0.0
Параметр сложности, используемый для минимальной стоимостно-сложностной обрезки. Поддерево с наибольшей стоимостью сложности, которое меньше чем
ccp_alphaбудет выбрано. По умолчанию обрезка не выполняется. См. Минимальная обрезка по стоимости-сложности для подробностей. См. Пост-обрезка деревьев решений с обрезкой по стоимости сложности для примера такой обрезки.Добавлено в версии 0.22.
- max_samplesint или float, по умолчанию=None
Если bootstrap равен True, количество образцов для выборки из X для обучения каждого базового оценщика.
Если None (по умолчанию), то рисуется
X.shape[0]выборки.Если int, то нарисовать
max_samplesвыборки.Если float, то нарисовать
max(round(n_samples * max_samples), 1)выборок. Таким образом,max_samplesдолжен находиться в интервале(0.0, 1.0].
Добавлено в версии 0.22.
- monotonic_cstarray-like of int of shape (n_features), default=None
- Указывает ограничение монотонности, применяемое к каждому признаку.
1: монотонно возрастающий
0: без ограничений
-1: монотонно убывающая
Если monotonic_cst равен None, ограничения не применяются.
- Ограничения монотонности не поддерживаются для:
многомерные регрессии (т.е. когда
n_outputs_ > 1),регрессии, обученные на данных с пропущенными значениями.
Подробнее в Руководство пользователя.
Добавлено в версии 1.4.
- Атрибуты:
- estimator_
DecisionTreeRegressor Шаблон дочернего оценщика, используемый для создания коллекции обученных под-оценщиков.
Добавлено в версии 1.2:
base_estimator_был переименован вestimator_.- estimators_список DecisionTreeRegressor
Коллекция обученных суб-оценщиков.
feature_importances_ndarray формы (n_features,)Важность признаков на основе нечистоты.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_outputs_int
Количество выходов, когда
fitвыполняется.- oob_score_float
Оценка обучающего набора данных, полученная с использованием out-of-bag оценки. Этот атрибут существует только когда
oob_scoreравно True.- oob_prediction_ndarray формы (n_samples,) или (n_samples, n_outputs)
Предсказание, вычисленное с использованием оценки out-of-bag на обучающем наборе. Этот атрибут существует только когда
oob_scoreравно True.estimators_samples_список массивовПодмножество выбранных выборок для каждого базового оценщика.
- estimator_
Смотрите также
sklearn.tree.DecisionTreeRegressorРегрессор дерева решений.
sklearn.ensemble.ExtraTreesRegressorАнсамбль экстремально рандомизированных деревьев-регрессоров.
sklearn.ensemble.HistGradientBoostingRegressorГистограммное дерево регрессии с градиентным бустингом, очень быстрое для больших наборов данных (n_samples >= 10_000).
Примечания
Значения по умолчанию для параметров, контролирующих размер деревьев (например,
max_depth,min_samples_leaf, и т.д.) приводят к полностью выращенным и необрезанным деревьям, которые потенциально могут быть очень большими на некоторых наборах данных. Чтобы уменьшить потребление памяти, сложность и размер деревьев должны быть контролируемы установкой значений этих параметров.Признаки всегда случайным образом перемешиваются при каждом разделении. Поэтому, наилучшее найденное разделение может варьироваться, даже с теми же обучающими данными,
max_features=n_featuresиbootstrap=False, если улучшение критерия идентично для нескольких разбиений, перечисленных во время поиска лучшего разбиения. Для получения детерминированного поведения во время обучения,random_stateдолжен быть фиксированным.Значение по умолчанию
max_features=1.0используетn_featuresвместоn_features / 3. Последний был первоначально предложен в [1], тогда как первый был недавно эмпирически обоснован в [2].Ссылки
[2]P. Geurts, D. Ernst. и L. Wehenkel, “Extremely randomized trees”, Machine Learning, 63(1), 3-42, 2006.
Примеры
>>> from sklearn.ensemble import RandomForestRegressor >>> from sklearn.datasets import make_regression >>> X, y = make_regression(n_features=4, n_informative=2, ... random_state=0, shuffle=False) >>> regr = RandomForestRegressor(max_depth=2, random_state=0) >>> regr.fit(X, y) RandomForestRegressor(...) >>> print(regr.predict([[0, 0, 0, 0]])) [-8.32987858]
- apply(X)[источник]#
Применить деревья в лесу к X, вернуть индексы листьев.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные выборки. Внутренне их тип данных будет преобразован в
dtype=np.float32. Если предоставлена разреженная матрица, она будет преобразована в разреженнуюcsr_matrix.
- Возвращает:
- X_leavesndarray формы (n_samples, n_estimators)
Для каждой точки данных x в X и для каждого дерева в лесу вернуть индекс листа, в который попадает x.
- decision_path(X)[источник]#
Возвращает путь принятия решений в лесу.
Добавлено в версии 0.18.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные выборки. Внутренне их тип данных будет преобразован в
dtype=np.float32. Если предоставлена разреженная матрица, она будет преобразована в разреженнуюcsr_matrix.
- Возвращает:
- индикаторразреженная матрица формы (n_samples, n_nodes)
Вернуть матрицу индикаторов узлов, где ненулевые элементы указывают, что выборки проходят через узлы. Матрица имеет формат CSR.
- n_nodes_ptrndarray формы (n_estimators + 1,)
Столбцы из indicator[n_nodes_ptr[i]:n_nodes_ptr[i+1]] дают значение индикатора для i-го оценщика.
- fit(X, y, sample_weight=None)[источник]#
Построить лес деревьев из обучающего набора (X, y).
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие входные образцы. Внутренне их тип данных будет преобразован в
dtype=np.float32. Если предоставлена разреженная матрица, она будет преобразована в разреженнуюcsc_matrix.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Целевые значения (метки классов в классификации, вещественные числа в регрессии).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок. Если None, то выборки имеют одинаковый вес. Разделения, которые создадут дочерние узлы с нулевым или отрицательным суммарным весом, игнорируются при поиске разделения в каждом узле. В случае классификации разделения также игнорируются, если они приведут к тому, что любой отдельный класс будет иметь отрицательный вес в любом из дочерних узлов.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать регрессионную цель для X.
Предсказанная регрессионная цель для входного образца вычисляется как среднее предсказанных регрессионных целей деревьев в лесу.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные выборки. Внутренне их тип данных будет преобразован в
dtype=np.float32. Если предоставлена разреженная матрица, она будет преобразована в разреженнуюcsr_matrix.
- Возвращает:
- yndarray формы (n_samples,) или (n_samples, n_outputs)
Предсказанные значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RandomForestRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RandomForestRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#

Сравнение моделей случайных лесов и градиентного бустинга на гистограммах

Сравнение случайных лесов и мета-оценщика с множественным выходом

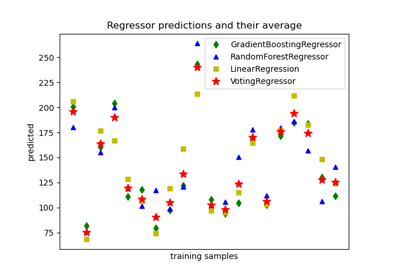
Построить индивидуальные и голосующие регрессионные предсказания
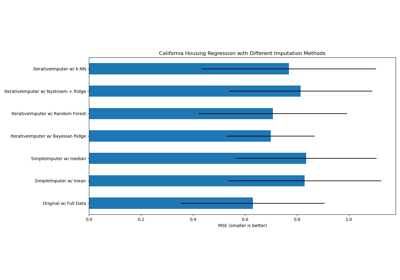
Заполнение пропущенных значений с вариантами IterativeImputer
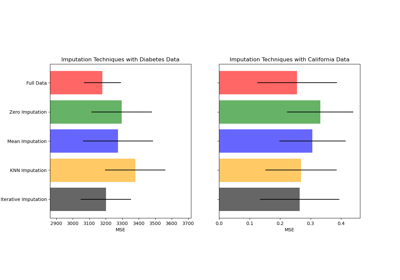
Заполнение пропущенных значений перед построением оценщика