ColumnTransformer#
- класс sklearn.compose.ColumnTransformer(преобразователи, *, остаток='drop', sparse_threshold=0.3, n_jobs=None, transformer_weights=None, verbose=False, verbose_feature_names_out=True, force_int_remainder_cols='устаревший')[источник]#
Применяет преобразователи к столбцам массива или pandas DataFrame.
Этот оценщик позволяет преобразовывать разные столбцы или подмножества столбцов входных данных отдельно, и признаки, сгенерированные каждым преобразователем, будут объединены для формирования единого пространства признаков. Это полезно для разнородных или столбцовых данных, чтобы объединить несколько механизмов извлечения признаков или преобразований в единый преобразователь.
Подробнее в Руководство пользователя.
Добавлено в версии 0.20.
- Параметры:
- преобразователисписок кортежей
Список кортежей (имя, трансформер, столбцы), определяющих объекты трансформеров, применяемые к подмножествам данных.
- имяstr
Как в Pipeline и FeatureUnion, это позволяет установить преобразователь и его параметры с помощью
set_paramsи ищутся в сеточном поиске.- преобразователь{‘drop’, ‘passthrough’} или оценщик
Оценщик должен поддерживать fit и преобразовать. Специальные строки 'drop' и 'passthrough' также принимаются, чтобы указать удалить столбцы или передать их без преобразования, соответственно.
- столбцыstr, array-like из str, int, array-like из int, array-like из bool, slice или callable
Индексирует данные по второй оси. Целые числа интерпретируются как позиционные столбцы, в то время как строки могут ссылаться на столбцы DataFrame по имени. Скалярная строка или целое число должны использоваться там, где
transformerожидает, что X будет одномерным массивоподобным объектом (вектором), иначе двумерный массив будет передан трансформатору. Вызываемый объект получает входные данныеXи может возвращать любой из вышеперечисленных. Чтобы выбрать несколько столбцов по имени или типу данных, вы можете использоватьmake_column_selector.
- остаток{‘drop’, ‘passthrough’} или estimator, default=’drop’
По умолчанию, только указанные столбцы в
transformersпреобразуются и объединяются в выходных данных, а неуказанные столбцы удаляются. (по умолчанию'drop'). Указавremainder='passthrough', все оставшиеся столбцы, которые не были указаны вtransformers, но присутствуют в данных, переданных вfitбудет автоматически пропущен. Это подмножество столбцов объединяется с выходом преобразователей. Для датафреймов дополнительные столбцы, не встречавшиеся во времяfitбудет исключен из вывода функцииtransform. Установивremainderчтобы быть оценщиком, оставшиеся неуказанные столбцы будут использоватьremainderоценщик. Оценщик должен поддерживать fit и преобразовать. Обратите внимание, что использование этой функции требует, чтобы столбцы DataFrame, введённые в fit и преобразовать имеют одинаковый порядок.- sparse_thresholdfloat, default=0.3
Если выходные данные различных преобразователей содержат разреженные матрицы, они будут объединены в разреженную матрицу, если общая плотность ниже этого значения. Используйте
sparse_threshold=0всегда возвращать плотные данные. Когда преобразованный вывод состоит из всех плотных данных, сложенный результат будет плотным, и это ключевое слово будет проигнорировано.- n_jobsint, default=None
Количество параллельно выполняемых задач.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- transformer_weightsdict, по умолчанию=None
Мультипликативные веса для признаков на трансформатор. Выход трансформатора умножается на эти веса. Ключи — имена трансформаторов, значения — веса.
- verbosebool, по умолчанию=False
Если True, затраченное время на обучение каждого преобразователя будет выводиться по завершении.
- verbose_feature_names_outbool, str или Callable[[str, str], str], по умолчанию=True
Если True,
ColumnTransformer.get_feature_names_outбудет добавлять префикс ко всем именам признаков с именем трансформера, который сгенерировал этот признак. Это эквивалентно установкеverbose_feature_names_out="{transformer_name}__{feature_name}".Если False,
ColumnTransformer.get_feature_names_outне будет добавлять префиксы к именам признаков и выдаст ошибку, если имена признаков не уникальны.Если
Callable[[str, str], str],ColumnTransformer.get_feature_names_outпереименует все признаки, используя имя преобразователя. Первый аргумент вызываемого объекта — имя преобразователя, второй — имя признака. Возвращаемая строка будет новым именем признака.Если
str, это должна быть строка, готовая к форматированию. Данная строка будет отформатирована с использованием двух имен полей:transformer_nameиfeature_name. например,"{feature_name}__{transformer_name}". См.str.formatметод из стандартной библиотеки для получения дополнительной информации.
Добавлено в версии 1.0.
Изменено в версии 1.6:
verbose_feature_names_outможет быть вызываемым объектом или строкой для форматирования.- force_int_remainder_colsbool, по умолчанию=False
Этот параметр не оказывает влияния.
Примечание
Если вы не обращаетесь к списку столбцов для оставшихся столбцов в
transformers_подобранный атрибут, вам не нужно устанавливать этот параметр.Добавлено в версии 1.5.
Изменено в версии 1.7: Значение по умолчанию для
force_int_remainder_colsизменится сTruetoFalseв версии 1.7.Устарело с версии 1.7:
force_int_remainder_colsустарел и будет удалён в версии 1.9.
- Атрибуты:
- transformers_list
Коллекция обученных трансформеров в виде кортежей (имя, обученный_трансформер, столбец).
fitted_transformerможет быть оценщиком,'drop';'passthrough'заменяется эквивалентнымFunctionTransformer. В случае, если не было выбрано ни одного столбца, это будет неподогнанный трансформер. Если остались столбцы, последний элемент представляет собой кортеж вида: ('remainder', transformer, remaining_columns), соответствующийremainderпараметр. Если остаются столбцы, тоlen(transformers_)==len(transformers)+1, иначеlen(transformers_)==len(transformers).Добавлено в версии 1.7: Формат оставшихся столбцов теперь пытается соответствовать формату других преобразователей: если все столбцы были предоставлены как имена столбцов (
str), оставшиеся столбцы сохраняются как имена столбцов; если все столбцы были предоставлены как массивы-маски (bool), то же самое и с оставшимися столбцами; во всех остальных случаях оставшиеся столбцы хранятся как индексы (int).named_transformers_BunchПолучите доступ к обученному преобразователю по имени.
- sparse_output_bool
Логический флаг, указывающий, должен ли вывод
transformявляется разреженной матрицей или плотным массивом numpy, что зависит от вывода отдельных преобразователей иsparse_thresholdключевое слово.- output_indices_dict
Словарь от имени каждого преобразователя к срезу, где срез соответствует индексам в преобразованном выводе. Это полезно для проверки, какой преобразователь отвечает за какие преобразованные признаки.
Добавлено в версии 1.0.
- n_features_in_int
Количество признаков, замеченных во время fit. Определено только если базовые преобразователи предоставляют такой атрибут при обучении.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
make_column_transformerУдобная функция для объединения выходов нескольких объектов-трансформеров, примененных к подмножествам столбцов исходного пространства признаков.
make_column_selectorУдобная функция для выбора столбцов на основе типа данных или имени столбца с помощью регулярного выражения.
Примечания
Порядок столбцов в преобразованной матрице признаков соответствует порядку, в котором столбцы указаны в
transformersсписок. Столбцы исходной матрицы признаков, которые не указаны, удаляются из результирующей преобразованной матрицы признаков, если не указано вpassthroughключевое слово. Те столбцы, которые указаны сpassthroughдобавляются справа к выходу преобразователей.Примеры
>>> import numpy as np >>> from sklearn.compose import ColumnTransformer >>> from sklearn.preprocessing import Normalizer >>> ct = ColumnTransformer( ... [("norm1", Normalizer(norm='l1'), [0, 1]), ... ("norm2", Normalizer(norm='l1'), slice(2, 4))]) >>> X = np.array([[0., 1., 2., 2.], ... [1., 1., 0., 1.]]) >>> # Normalizer scales each row of X to unit norm. A separate scaling >>> # is applied for the two first and two last elements of each >>> # row independently. >>> ct.fit_transform(X) array([[0. , 1. , 0.5, 0.5], [0.5, 0.5, 0. , 1. ]])
ColumnTransformerможет быть настроен с преобразователем, требующим одномерный массив, установив столбец в строку:>>> from sklearn.feature_extraction.text import CountVectorizer >>> from sklearn.preprocessing import MinMaxScaler >>> import pandas as pd >>> X = pd.DataFrame({ ... "documents": ["First item", "second one here", "Is this the last?"], ... "width": [3, 4, 5], ... }) >>> # "documents" is a string which configures ColumnTransformer to >>> # pass the documents column as a 1d array to the CountVectorizer >>> ct = ColumnTransformer( ... [("text_preprocess", CountVectorizer(), "documents"), ... ("num_preprocess", MinMaxScaler(), ["width"])]) >>> X_trans = ct.fit_transform(X)
Для более подробного примера использования см. Трансформер столбцов со смешанными типами.
- fit(X, y=None, **params)[источник]#
Обучить все преобразователи, используя X.
- Параметры:
- X{array-like, dataframe} формы (n_samples, n_features)
Входные данные, из которых указанные подмножества используются для обучения преобразователей.
- yarray-like формы (n_samples,…), по умолчанию=None
Целевые переменные для обучения с учителем.
- **paramsdict, по умолчанию=None
Параметры для передачи в базовые преобразователи
fitиtransformметоды.Вы можете передать это только если включена маршрутизация метаданных, что вы можете включить с помощью
sklearn.set_config(enable_metadata_routing=True).Добавлено в версии 1.4.
- Возвращает:
- selfColumnTransformer
Этот оценщик.
- fit_transform(X, y=None, **params)[источник]#
Обучить все преобразователи, преобразовать данные и объединить результаты.
- Параметры:
- X{array-like, dataframe} формы (n_samples, n_features)
Входные данные, из которых указанные подмножества используются для обучения преобразователей.
- yarray-like формы (n_samples,), по умолчанию=None
Целевые переменные для обучения с учителем.
- **paramsdict, по умолчанию=None
Параметры для передачи в базовые преобразователи
fitиtransformметоды.Вы можете передать это только если включена маршрутизация метаданных, что вы можете включить с помощью
sklearn.set_config(enable_metadata_routing=True).Добавлено в версии 1.4.
- Возвращает:
- X_t{array-like, sparse matrix} формы (n_samples, sum_n_components)
Горизонтально сложенные результаты трансформеров. sum_n_components — это сумма n_components (размерности выхода) по трансформерам. Если какой-либо результат является разреженной матрицей, всё будет преобразовано в разреженные матрицы.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.4.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
Возвращает параметры, заданные в конструкторе, а также оценщики, содержащиеся в
transformersизColumnTransformer.- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить выходной контейнер, когда
"transform"и"fit_transform"вызываются.Вызов
set_outputустановит выход всех оценщиков вtransformersиtransformers_.- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**kwargs)[источник]#
Установить параметры этого оценщика.
Допустимые ключи параметров можно перечислить с помощью
get_params(). Обратите внимание, что вы можете напрямую устанавливать параметры оценщиков, содержащихся вtransformersofColumnTransformer.- Параметры:
- **kwargsdict
Параметры оценщика.
- Возвращает:
- selfColumnTransformer
Этот оценщик.
- преобразовать(X, **params)[источник]#
Преобразуйте X отдельно каждым трансформером, объедините результаты.
- Параметры:
- X{array-like, dataframe} формы (n_samples, n_features)
Данные для преобразования подмножеством.
- **paramsdict, по умолчанию=None
Параметры для передачи в базовые преобразователи
transformметод.Вы можете передать это только если включена маршрутизация метаданных, что вы можете включить с помощью
sklearn.set_config(enable_metadata_routing=True).Добавлено в версии 1.4.
- Возвращает:
- X_t{array-like, sparse matrix} формы (n_samples, sum_n_components)
Горизонтально сложенные результаты трансформеров. sum_n_components — это сумма n_components (размерности выхода) по трансформерам. Если какой-либо результат является разреженной матрицей, всё будет преобразовано в разреженные матрицы.
Примеры галереи#

Трансформер столбцов с разнородными источниками данных
Графики частичной зависимости и индивидуального условного ожидания
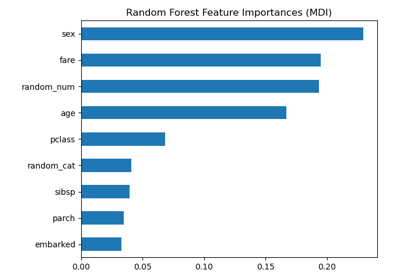
Важность перестановок против важности признаков случайного леса (MDI)