accuracy_score#
- sklearn.metrics.accuracy_score(y_true, y_pred, *, нормализовать=True, sample_weight=None)[источник]#
Оценка точности классификации.
В многометочной классификации эта функция вычисляет точность подмножества: набор меток, предсказанных для образца, должен точно соответствуют соответствующему набору меток в y_true.
Подробнее в Руководство пользователя.
- Параметры:
- y_true1d array-like, или массив индикаторов меток / разреженная матрица
Истинные (правильные) метки. Разреженная матрица поддерживается только когда метки имеют многометочный тип.
- y_pred1d array-like, или массив индикаторов меток / разреженная матрица
Предсказанные метки, как возвращенные классификатором. Разреженная матрица поддерживается только когда метки имеют многометочный тип.
- нормализоватьbool, по умолчанию=True
Если
False, возвращает количество правильно классифицированных образцов. В противном случае возвращает долю правильно классифицированных образцов.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Если
normalize == True, возвращает долю правильно классифицированных выборок, иначе возвращает количество правильно классифицированных выборок.Лучшая производительность составляет 1.0 с
normalize == Trueи количество выборок сnormalize == False.
Смотрите также
balanced_accuracy_scoreВычислить сбалансированную точность для работы с несбалансированными наборами данных.
jaccard_scoreВычисляет коэффициент сходства Жаккара.
hamming_lossВычислить среднюю потерю Хэмминга или расстояние Хэмминга между двумя наборами образцов.
zero_one_lossВычислить потерю классификации Zero-one. По умолчанию функция вернет процент неправильно предсказанных подмножеств.
Примеры
>>> from sklearn.metrics import accuracy_score >>> y_pred = [0, 2, 1, 3] >>> y_true = [0, 1, 2, 3] >>> accuracy_score(y_true, y_pred) 0.5 >>> accuracy_score(y_true, y_pred, normalize=False) 2.0
В случае многометочной классификации с бинарными индикаторами меток:
>>> import numpy as np >>> accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2))) 0.5
Примеры галереи#
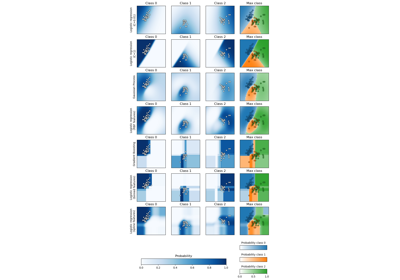
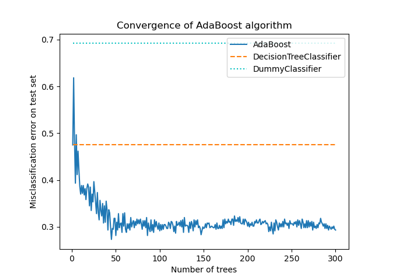
Многоклассовые деревья решений с бустингом AdaBoost
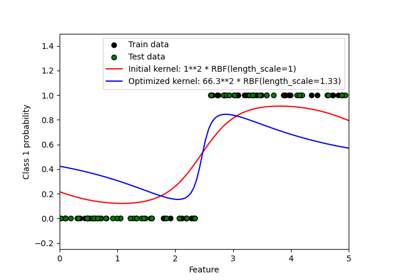
Вероятностные предсказания с гауссовским процессом классификации (GPC)
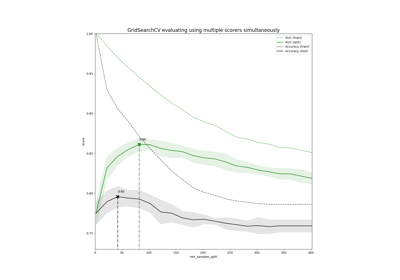
Демонстрация многометрической оценки на cross_val_score и GridSearchCV

Классификация текстовых документов с использованием разреженных признаков