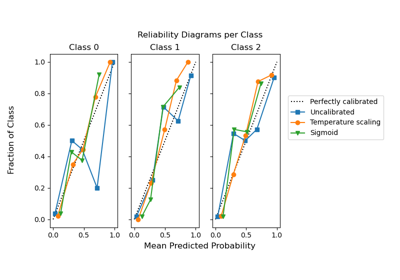
CalibratedClassifierCV#
- класс sklearn.calibration.CalibratedClassifierCV(estimator=None, *, метод='sigmoid', cv=None, n_jobs=None, ансамбль='auto')[источник]#
Калибровка вероятностей с использованием изотонического, сигмоидного или температурного масштабирования.
Этот класс использует перекрестную проверку как для оценки параметров классификатора, так и для последующей калибровки классификатора. С
ensemble=True, для каждого разделения cv он обучает копию базового оценщика на обучающем подмножестве и калибрует его используя тестовое подмножество. Для предсказания предсказанные вероятности усредняются по этим индивидуальным калиброванным классификаторам. Когдаensemble=False, перекрёстная проверка используется для получения несмещённых предсказаний, черезcross_val_predict, которые затем используются для калибровки. Для предсказания используется базовый оценщик, обученный на всех данных. Это метод предсказания, реализованный приprobabilities=TrueдляSVCиNuSVCоценщиков (см. Руководство пользователя подробности).Уже обученные классификаторы можно откалибровать, обернув модель в
FrozenEstimatorВ этом случае все предоставленные данные используются для калибровки. Пользователь должен вручную позаботиться о том, чтобы данные для обучения модели и калибровки были разделены.Калибровка основана на decision_function метод
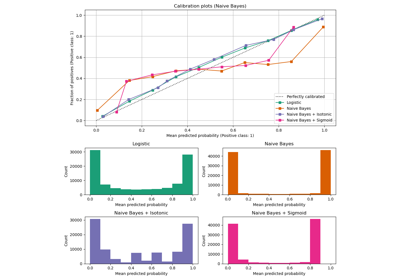
estimatorесли существует, иначе на predict_proba.Подробнее в Руководство пользователя. Чтобы узнать больше о классе CalibratedClassifierCV, см. следующие примеры калибровки: Калибровка вероятностей классификаторов, Кривые калибровки вероятности, и Калибровка вероятностей для классификации на 3 класса.
- Параметры:
- estimatorэкземпляр оценщика, по умолчанию=None
Классификатор, выход которого необходимо откалибровать для обеспечения более точных
predict_probaвыходы. Классификатор по умолчанию - этоLinearSVC.Добавлено в версии 1.2.
- метод{‘sigmoid’, ‘isotonic’, ‘temperature’}, по умолчанию=’sigmoid’
Метод, используемый для калибровки. Может быть:
‘sigmoid’, что соответствует методу Платта (т.е. бинарной логистической регрессионной модели).
'isotonic', который является непараметрическим подходом.
‘temperature’, температурное масштабирование.
Методы калибровки сигмоиды и изотоники изначально поддерживают только бинарные классификаторы и расширяются на многоклассовую классификацию с использованием стратегии «Один против всех» (OvR) с последующей перенормировкой, т.е. корректировкой вероятностей после калибровки, чтобы гарантировать, что их сумма равна 1.
В отличие от этого, температурное масштабирование естественно поддерживает многоклассовую калибровку, применяя
softmax(classifier_logits/T)со значениемT(температура) которая оптимизирует логарифмическую потерю.Для очень некалиброванных классификаторов на очень несбалансированных наборах данных, сигмоидная калибровка может быть предпочтительнее, потому что она подгоняет дополнительный параметр пересечения. Это помогает соответствующим образом смещать границы решений, когда калибруемый классификатор смещен в сторону большинства классов.
Изотоническая калибровка не рекомендуется, когда количество калибровочных выборок слишком мало
(≪1000)поскольку это может привести к переобучению.Изменено в версии 1.8: Добавлена опция ‘temperature’.
- cvint, генератор перекрестной проверки или итерируемый объект, default=None
Определяет стратегию разделения для перекрестной проверки. Возможные значения для cv:
None, чтобы использовать стандартную 5-кратную перекрестную проверку,
целое число, чтобы указать количество фолдов.
Итерируемый объект, возвращающий (обучающие, тестовые) разбиения в виде массивов индексов.
Для целочисленных/None входов, если
yявляется бинарной или многоклассовой,StratifiedKFoldиспользуется. Еслиyне является ни бинарным, ни многоклассовым,KFoldиспользуется.См. Руководство пользователя для различных стратегий перекрестной проверки, которые можно использовать здесь.
Изменено в версии 0.22:
cvзначение по умолчанию, если None изменено с 3-кратного на 5-кратное.- n_jobsint, default=None
Количество параллельно выполняемых задач.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров.Клоны базового оценщика обучаются параллельно по итерациям перекрестной проверки.
См. Глоссарий для получения дополнительной информации.
Добавлено в версии 0.24.
- ансамбльbool или "auto", по умолчанию="auto"
Определяет, как калибратор обучается.
«auto» будет использовать
FalseеслиestimatorявляетсяFrozenEstimator, иTrueв противном случае.Если
True,estimatorобучается с использованием обучающих данных и калибруется с использованием тестовых данных для каждогоcvсгиб. Финальный оценщик является ансамблемn_cvобученные пары классификатор-калибратор, гдеn_cv— это количество перекрестных проверочных фолдов. Выходные данные — это средние предсказанные вероятности всех пар.Если
False,cvиспользуется для вычисления несмещённых предсказаний черезcross_val_predict, которые затем используются для калибровки. Во время предсказания используется классификаторestimatorобучен на всех данных. Обратите внимание, что этот метод также внутренне реализован вsklearn.svmоцениватели сprobabilities=Trueпараметр.Добавлено в версии 0.24.
Изменено в версии 1.6:
"auto"опция добавлена и является значением по умолчанию.
- Атрибуты:
- classes_ndarray формы (n_classes,)
Метки классов.
- n_features_in_int
Количество признаков, замеченных во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Добавлено в версии 1.0.
- calibrated_classifiers_список (len() равен cv или 1, если
ensemble=False) Список пар классификатор-калибратор.
Когда
ensemble=True,n_cvобученныйestimatorи пары калибраторов.n_cv— это количество фолдов перекрестной проверки.Когда
ensemble=False,estimator, обученный на всех данных, и обученный калибратор.
Изменено в версии 0.24: Случай одного калиброванного классификатора, когда
ensemble=False.
Смотрите также
calibration_curveВычислить истинные и предсказанные вероятности для калибровочной кривой.
Ссылки
[1]B. Zadrozny & C. Elkan. Получение калиброванных вероятностных оценок из деревьев решений и наивных байесовских классификаторов, ICML 2001.
[2]B. Zadrozny & C. Elkan. Преобразование оценок классификатора в точные оценки вероятностей для многоклассовой классификации, KDD 2002.
[3]Дж. Платт. Вероятностные выходы для машин опорных векторов и сравнения с методами регуляризованного правдоподобия, 1999.
[4]A. Niculescu-Mizil & R. Caruana. Предсказание хороших вероятностей с обучением с учителем, ICML 2005.
[5]Chuan Guo, Geoff Pleiss, Yu Sun, Kilian Q. Weinberger. О калибровке современных нейронных сетей. Труды 34-й Международной конференции по машинному обучению, PMLR 70:1321-1330, 2017.
Примеры
>>> from sklearn.datasets import make_classification >>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.calibration import CalibratedClassifierCV >>> X, y = make_classification(n_samples=100, n_features=2, ... n_redundant=0, random_state=42) >>> base_clf = GaussianNB() >>> calibrated_clf = CalibratedClassifierCV(base_clf, cv=3) >>> calibrated_clf.fit(X, y) CalibratedClassifierCV(...) >>> len(calibrated_clf.calibrated_classifiers_) 3 >>> calibrated_clf.predict_proba(X)[:5, :] array([[0.110, 0.889], [0.072, 0.927], [0.928, 0.072], [0.928, 0.072], [0.072, 0.928]]) >>> from sklearn.model_selection import train_test_split >>> X, y = make_classification(n_samples=100, n_features=2, ... n_redundant=0, random_state=42) >>> X_train, X_calib, y_train, y_calib = train_test_split( ... X, y, random_state=42 ... ) >>> base_clf = GaussianNB() >>> base_clf.fit(X_train, y_train) GaussianNB() >>> from sklearn.frozen import FrozenEstimator >>> calibrated_clf = CalibratedClassifierCV(FrozenEstimator(base_clf)) >>> calibrated_clf.fit(X_calib, y_calib) CalibratedClassifierCV(...) >>> len(calibrated_clf.calibrated_classifiers_) 1 >>> calibrated_clf.predict_proba([[-0.5, 0.5]]) array([[0.936, 0.063]])
- fit(X, y, sample_weight=None, **fit_params)[источник]#
Обучить калиброванную модель.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие данные.
- yarray-like формы (n_samples,)
Целевые значения.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса образцов. Если None, то образцы имеют одинаковый вес.
- **fit_paramsdict
Параметры для передачи в
fitметод базового классификатора.
- Возвращает:
- selfobject
Возвращает экземпляр self.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать цель для новых образцов.
Предсказанный класс — это класс с наивысшей вероятностью и, следовательно, может отличаться от предсказания некалиброванного классификатора.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Образцы, как принято в
estimator.predict.
- Возвращает:
- Cndarray формы (n_samples,)
Предсказанный класс.
- predict_proba(X)[источник]#
Калиброванные вероятности классификации.
Эта функция возвращает калиброванные вероятности классификации по каждому классу на массиве тестовых векторов X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Образцы, как принято в
estimator.predict_proba.
- Возвращает:
- Cndarray формы (n_samples, n_classes)
Предсказанные вероятности.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') CalibratedClassifierCV[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') CalibratedClassifierCV[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
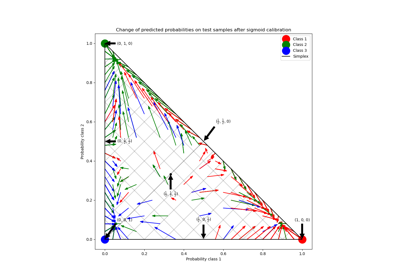
Калибровка вероятностей для классификации на 3 класса