LinearSVC#
- класс sklearn.svm.LinearSVC(штраф='l2', потеря='squared_hinge', *, dual='auto', tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)[источник]#
Линейная классификация методом опорных векторов.
Аналогично SVC с параметром kernel='linear', но реализовано с использованием liblinear, а не libsvm, поэтому имеет большую гибкость в выборе штрафов и функций потерь и должен лучше масштабироваться на большое количество образцов.
Основные различия между
LinearSVCиSVCзаключаются в функции потерь, используемой по умолчанию, и в обработке регуляризации свободного члена между этими двумя реализациями.Этот класс поддерживает как плотные, так и разреженные входные данные, а многоклассовая поддержка обрабатывается по схеме «один против остальных».
Подробнее в Руководство пользователя.
- Параметры:
- штраф{‘l1’, ‘l2’}, по умолчанию=’l2’
Определяет норму, используемую в штрафе. Штраф 'l2' является стандартным для SVC. Штраф 'l1' приводит к
coef_векторы, которые являются разреженными.- потеря{'hinge', 'squared_hinge'}, по умолчанию='squared_hinge'
Определяет функцию потерь. 'hinge' — стандартная потеря SVM (используется, например, классом SVC), а 'squared_hinge' — квадрат потери hinge. Комбинация
penalty='l1'иloss='hinge'не поддерживается.- dual“auto” или bool, по умолчанию=”auto”
Выберите алгоритм для решения двойной или прямой задачи оптимизации. Предпочитайте dual=False, когда n_samples > n_features.
dual="auto"автоматически выберет значение параметра на основе значенийn_samples,n_features,loss,multi_classиpenalty. Еслиn_samples<n_featuresи оптимизатор поддерживает выбранныйloss,multi_classиpenalty, тогда dual будет установлен в True, в противном случае он будет установлен в False.Изменено в версии 1.3: The
"auto"опция добавлена в версии 1.3 и будет использоваться по умолчанию в версии 1.5.- tolfloat, по умолчанию=1e-4
Допуск для критериев остановки.
- Cfloat, по умолчанию=1.0
Параметр регуляризации. Сила регуляризации обратно пропорциональна C. Должна быть строго положительной. Для интуитивной визуализации эффектов масштабирования параметра регуляризации C см. Масштабирование параметра регуляризации для SVC.
- multi_class{'ovr', 'crammer_singer'}, по умолчанию='ovr'
Определяет стратегию для многоклассовой классификации, если
yсодержит более двух классов."ovr"обучает n_classes классификаторов один-против-всех, в то время как"crammer_singer"оптимизирует совместную цель по всем классам. В то время какcrammer_singerинтересен с теоретической точки зрения, так как он согласован, но редко используется на практике, так как редко приводит к лучшей точности и дороже в вычислении. Если"crammer_singer"выбран, параметры loss, penalty и dual будут проигнорированы.- fit_interceptbool, по умолчанию=True
Следует ли подгонять свободный член. Если установлено True, вектор признаков расширяется для включения свободного члена:
[x_1, ..., x_n, 1], где 1 соответствует свободному члену. Если установлено в False, свободный член не будет использоваться в вычислениях (т.е. данные ожидаются уже центрированными).- intercept_scalingfloat, по умолчанию=1.0
Когда
fit_interceptравно True, вектор экземпляра x становится[x_1, ..., x_n, intercept_scaling], т.е. «синтетический» признак с постоянным значением, равнымintercept_scalingдобавляется к вектору экземпляра. Перехват становится intercept_scaling * синтетический вес признака. Обратите внимание, что liblinear внутренне штрафует перехват, обращаясь с ним как с любым другим членом в векторе признаков. Чтобы уменьшить влияние регуляризации на перехват,intercept_scalingпараметр может быть установлен в значение больше 1; чем выше значениеintercept_scaling, тем меньше влияние регуляризации на него. Затем веса становятся[w_x_1, ..., w_x_n, w_intercept*intercept_scaling], гдеw_x_1, ..., w_x_nпредставляют веса признаков, а вес пересечения масштабируется наintercept_scaling. Это масштабирование позволяет члену пересечения иметь другое регуляризационное поведение по сравнению с другими признаками.- class_weightdict или 'balanced', по умолчанию=None
Установить параметр C класса i в
class_weight[i]*Cдля SVC. Если не задано, предполагается, что все классы имеют вес один. Режим "balanced" использует значения y для автоматической настройки весов обратно пропорционально частотам классов во входных данных какn_samples / (n_classes * np.bincount(y)).- verboseint, по умолчанию=0
Включить подробный вывод. Обратите внимание, что этот параметр использует настройку времени выполнения на процесс в liblinear, которая, если включена, может некорректно работать в многопоточном контексте.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет псевдослучайной генерацией чисел для перемешивания данных при двойственном координатном спуске (если
dual=True). Когдаdual=Falseбазовая реализацияLinearSVCне является случайным иrandom_stateне влияет на результаты. Передайте целое число для воспроизводимых результатов при многократных вызовах функции. См. Глоссарий.- max_iterint, по умолчанию=1000
Максимальное количество итераций для выполнения.
- Атрибуты:
- coef_ndarray формы (1, n_features), если n_classes == 2, иначе (n_classes, n_features)
Веса, присвоенные признакам (коэффициенты в прямой задаче).
coef_является свойством только для чтения, производным отraw_coef_который следует внутренней структуре памяти liblinear.- intercept_ndarray формы (1,) если n_classes == 2 иначе (n_classes,)
Константы в функции принятия решений.
- classes_ndarray формы (n_classes,)
Уникальные метки классов.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Максимальное количество итераций, выполняемых для всех классов.
Смотрите также
SVCРеализация классификатора метода опорных векторов с использованием libsvm: ядро может быть нелинейным, но его алгоритм SMO не масштабируется на большое количество выборок, как это делает LinearSVC. Кроме того, многоклассовый режим SVC реализован с использованием схемы один против одного, в то время как LinearSVC использует один против всех. Можно реализовать один против всех с SVC, используя
OneVsRestClassifierобертка. Наконец, SVC может обучаться на плотных данных без копирования памяти, если входные данные C-непрерывны. Разреженные данные все равно приведут к копированию памяти.sklearn.linear_model.SGDClassifierSGDClassifier может оптимизировать ту же функцию стоимости, что и LinearSVC, путём настройки параметров штрафа и потерь. Кроме того, он требует меньше памяти, позволяет инкрементное (онлайн) обучение и реализует различные функции потерь и режимы регуляризации.
Примечания
Базовая реализация на C использует генератор случайных чисел для выбора признаков при обучении модели. Поэтому нередко получаются слегка разные результаты для одних и тех же входных данных. Если это происходит, попробуйте с меньшим
tolпараметр.Базовая реализация, liblinear, использует разреженное внутреннее представление данных, что приведет к копированию памяти.
Прогнозируемый вывод может не совпадать с выводом standalone liblinear в некоторых случаях. См. отличия от liblinear в повествовательной документации.
Ссылки
LIBLINEAR: Библиотека для крупномасштабной линейной классификации
Примеры
>>> from sklearn.svm import LinearSVC >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.datasets import make_classification >>> X, y = make_classification(n_features=4, random_state=0) >>> clf = make_pipeline(StandardScaler(), ... LinearSVC(random_state=0, tol=1e-5)) >>> clf.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('linearsvc', LinearSVC(random_state=0, tol=1e-05))])
>>> print(clf.named_steps['linearsvc'].coef_) [[0.141 0.526 0.679 0.493]]
>>> print(clf.named_steps['linearsvc'].intercept_) [0.1693] >>> print(clf.predict([[0, 0, 0, 0]])) [1]
- decision_function(X)[источник]#
Предсказывает оценки уверенности для образцов.
Оценка уверенности для образца пропорциональна знаковому расстоянию от этого образца до гиперплоскости.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Матрица данных, для которой мы хотим получить оценки уверенности.
- Возвращает:
- scoresndarray формы (n_samples,) или (n_samples, n_classes)
Оценки уверенности для каждого
(n_samples, n_classes)комбинация. В двоичном случае оценка уверенности дляself.classes_[1]где >0 означает, что этот класс будет предсказан.
- densify()[источник]#
Преобразовать матрицу коэффициентов в плотный формат массива.
Преобразует
coef_преобразование (обратное) в numpy.ndarray. Это формат по умолчаниюcoef_и требуется для обучения, поэтому вызов этого метода необходим только для моделей, которые ранее были разрежены; в противном случае это пустая операция.- Возвращает:
- self
Обученный оценщик.
- fit(X, y, sample_weight=None)[источник]#
Обучает модель на основе предоставленных обучающих данных.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Вектор обучения, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевой вектор относительно X.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Массив весов, которые назначаются отдельным выборкам. Если не предоставлен, то каждой выборке присваивается единичный вес.
Добавлено в версии 0.18.
- Возвращает:
- selfobject
Экземпляр оценивателя.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать метки классов для выборок в X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Матрица данных, для которой мы хотим получить предсказания.
- Возвращает:
- y_predndarray формы (n_samples,)
Вектор, содержащий метки классов для каждого образца.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearSVC[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearSVC[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
- разрежать()[источник]#
Преобразовать матрицу коэффициентов в разреженный формат.
Преобразует
coef_члену разреженной матрицы scipy.sparse, что для моделей с L1-регуляризацией может быть значительно более эффективным по памяти и хранению, чем обычное представление numpy.ndarray.The
intercept_Член не преобразован.- Возвращает:
- self
Обученный оценщик.
Примечания
Для неразреженных моделей, т.е. когда в
coef_, это может фактически увеличить использование памяти, поэтому используйте этот метод с осторожностью. Эмпирическое правило: количество нулевых элементов, которое можно вычислить с помощью(coef_ == 0).sum(), должно быть больше 50%, чтобы это обеспечивало значительные преимущества.После вызова этого метода дальнейшее обучение с помощью метода partial_fit (если он есть) не будет работать, пока вы не вызовете densify.
Примеры галереи#
Трансформер столбцов с разнородными источниками данных
Выбор уменьшения размерности с помощью Pipeline и GridSearchCV


Масштабируемое обучение с полиномиальной аппроксимацией ядра
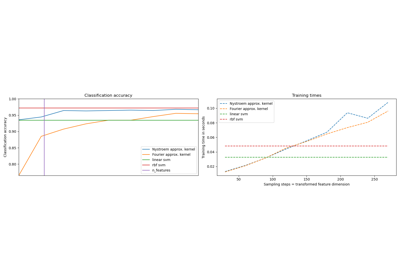
Аппроксимация явного отображения признаков для RBF-ядер

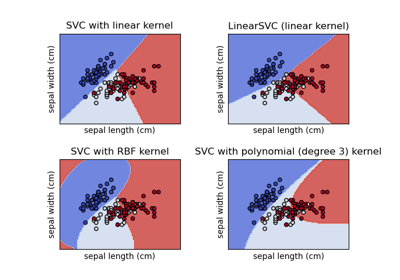
Построение различных классификаторов SVM на наборе данных iris

Классификация текстовых документов с использованием разреженных признаков