Ridge#
- класс sklearn.linear_model.Ridge(alpha=1.0, *, fit_intercept=True, copy_X=True, max_iter=None, tol=0.0001, solver='auto', положительный=False, random_state=None)[источник]#
Линейные наименьшие квадраты с L2-регуляризацией.
Минимизирует целевую функцию:
||y - Xw||^2_2 + alpha * ||w||^2_2
Эта модель решает регрессионную модель, где функция потерь - линейная функция наименьших квадратов, а регуляризация задается l2-нормой. Также известна как гребневая регрессия или регуляризация Тихонова. Этот оценщик имеет встроенную поддержку многомерной регрессии (т.е., когда y - 2d-массив формы (n_samples, n_targets)).
Подробнее в Руководство пользователя.
- Параметры:
- alpha{float, ndarray формы (n_targets,)}, по умолчанию=1.0
Константа, умножающая член L2, контролирующая силу регуляризации.
alphaдолжно быть неотрицательным числом с плавающей точкой, т.е. в[0, inf).Когда
alpha = 0, цель эквивалентна обычному методу наименьших квадратов, решаемому с помощьюLinearRegressionобъект. По численным причинам, использованиеalpha = 0сRidgeобъекта не рекомендуется. Вместо этого следует использоватьLinearRegressionобъект.Если передан массив, штрафы предполагаются специфичными для целей. Следовательно, они должны соответствовать по количеству.
- fit_interceptbool, по умолчанию=True
Следует ли подгонять свободный член для этой модели. Если установлено false, свободный член не будет использоваться в вычислениях (т.е.
Xиyожидается, что они центрированы).- copy_Xbool, по умолчанию=True
Если True, X будет скопирован; иначе, он может быть перезаписан.
- max_iterint, default=None
Максимальное количество итераций для решателя сопряженных градиентов. Для решателей 'sparse_cg' и 'lsqr' значение по умолчанию определяется scipy.sparse.linalg. Для решателя 'sag' значение по умолчанию равно 1000. Для решателя 'lbfgs' значение по умолчанию равно 15000.
- tolfloat, по умолчанию=1e-4
Точность решения (
coef_) определяетсяtol, который задает разные критерии сходимости для каждого решателя:'svd':
tolне оказывает влияния.‘cholesky’:
tolне оказывает влияния.‘sparse_cg’: норма остатков меньше, чем
tol.'lsqr':
tolустанавливается как atol и btol scipy.sparse.linalg.lsqr, которые контролируют норму вектора остатков в терминах норм матрицы и коэффициентов.‘sag’ и ‘saga’: относительное изменение коэффициента меньше, чем
tol.‘lbfgs’: максимум абсолютного (спроецированного) градиента=max|остатки| меньше, чем
tol.
Изменено в версии 1.2: Значение по умолчанию изменено с 1e-3 на 1e-4 для согласованности с другими линейными моделями.
- solver{‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, по умолчанию=’auto’
Решатель для использования в вычислительных процедурах:
'auto' автоматически выбирает решатель на основе типа данных.
‘svd’ использует сингулярное разложение X для вычисления коэффициентов Ridge. Это наиболее стабильный решатель, в частности более стабильный для сингулярных матриц, чем ‘cholesky’, за счёт более медленной работы.
‘cholesky’ использует стандартный
scipy.linalg.solveфункции для получения аналитического решения.‘sparse_cg’ использует решатель сопряженных градиентов, как в
scipy.sparse.linalg.cg. Как итеративный алгоритм, этот решатель более подходит, чем 'cholesky', для данных большого масштаба (возможность установитьtolиmax_iter).‘lsqr’ использует специализированную процедуру регуляризованных наименьших квадратов
scipy.sparse.linalg.lsqr. Это самый быстрый метод, использующий итеративную процедуру.'sag' использует стохастический средний градиентный спуск, а 'saga' использует его улучшенную, несмещённую версию под названием SAGA. Оба метода также используют итерационную процедуру и часто быстрее других решателей, когда и n_samples, и n_features велики. Обратите внимание, что быстрая сходимость 'sag' и 'saga' гарантируется только для признаков с примерно одинаковым масштабом. Вы можете предварительно обработать данные с помощью масштабатора из
sklearn.preprocessing.‘lbfgs’ использует алгоритм L-BFGS-B, реализованный в
scipy.optimize.minimize. Может использоваться только когдаpositiveравно True.
Все решатели, кроме 'svd', поддерживают как плотные, так и разреженные данные. Однако только 'lsqr', 'sag', 'sparse_cg' и 'lbfgs' поддерживают разреженный ввод, когда
fit_interceptравно True.Добавлено в версии 0.17: Решатель стохастического среднего градиентного спуска.
Добавлено в версии 0.19: SAGA solver.
- положительныйbool, по умолчанию=False
При установке значения
True, заставляет коэффициенты быть положительными. Только решатель 'lbfgs' поддерживается в этом случае.- random_stateint, экземпляр RandomState, по умолчанию=None
Используется, когда
solver== 'sag' или 'saga' для перемешивания данных. См. Глоссарий подробности.Добавлено в версии 0.17:
random_stateдля поддержки Stochastic Average Gradient.
- Атрибуты:
- coef_ndarray формы (n_features,) или (n_targets, n_features)
Вектор(ы) весов.
- intercept_float или ndarray формы (n_targets,)
Независимый член в функции решения. Установлен в 0.0, если
fit_intercept = False.- n_iter_None или ndarray формы (n_targets,)
Фактическое количество итераций для каждой цели. Доступно только для решателей 'sag' и 'lsqr'. Другие решатели вернут None.
Добавлено в версии 0.17.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- solver_str
Решатель, который использовался во время обучения вычислительными процедурами.
Добавлено в версии 1.5.
Смотрите также
RidgeClassifierКлассификатор Ridge.
RidgeCVРидж-регрессия со встроенной кросс-валидацией.
KernelRidgeЯдерная гребневая регрессия сочетает гребневую регрессию с ядерным трюком.
Примечания
Регуляризация улучшает обусловленность задачи и уменьшает дисперсию оценок. Большие значения указывают на более сильную регуляризацию. Alpha соответствует
1 / (2C)в других линейных моделях, таких какLogisticRegressionилиLinearSVC.Примеры
>>> from sklearn.linear_model import Ridge >>> import numpy as np >>> n_samples, n_features = 10, 5 >>> rng = np.random.RandomState(0) >>> y = rng.randn(n_samples) >>> X = rng.randn(n_samples, n_features) >>> clf = Ridge(alpha=1.0) >>> clf.fit(X, y) Ridge()
- fit(X, y, sample_weight=None)[источник]#
Обучить модель регрессии Ridge.
- Параметры:
- X{ndarray, разреженная матрица} формы (n_samples, n_features)
Обучающие данные.
- yndarray формы (n_samples,) или (n_samples, n_targets)
Целевые значения.
- sample_weightfloat или ndarray формы (n_samples,), по умолчанию=None
Индивидуальные веса для каждого образца. Если задано число с плавающей точкой, каждый образец будет иметь одинаковый вес.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Прогнозирование с использованием линейной модели.
- Параметры:
- Xмассивоподобный или разреженная матрица, форма (n_samples, n_features)
Образцы.
- Возвращает:
- Cмассив, формы (n_samples,)
Возвращает предсказанные значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Ridge[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Ridge[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#

Компрессионное зондирование: реконструкция томографии с априорным распределением L1 (Lasso)
Сравнение ядерной гребневой регрессии и регрессии по методу Гауссовских процессов
Заполнение пропущенных значений с вариантами IterativeImputer

Распространённые ошибки в интерпретации коэффициентов линейных моделей
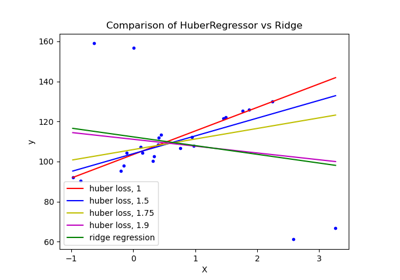
HuberRegressor против Ridge на наборе данных с сильными выбросами
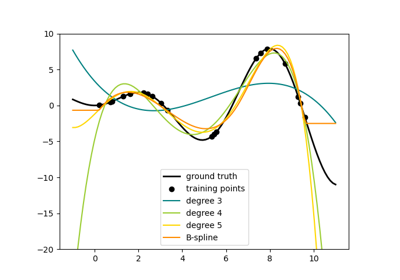
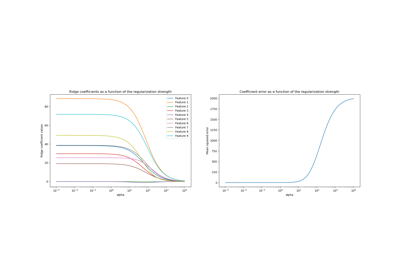
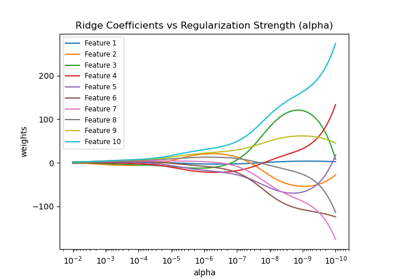
Построение коэффициентов Ridge как функции регуляризации