SVC#
- класс sklearn.svm.SVC(*, C=1.0, ядро='rbf', степень=3, gamma='scale', coef0=0.0, сжатие=True, вероятность=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)[источник]#
Классификация методом опорных векторов с C-регуляризацией.
Реализация основана на libsvm. Время обучения масштабируется как минимум квадратично с количеством выборок и может быть непрактичным за пределами десятков тысяч выборок. Для больших наборов данных рассмотрите использование
LinearSVCилиSGDClassifierвместо этого, возможно, послеNystroemпреобразователь или другой Аппроксимация ядра.Поддержка многоклассовой классификации обрабатывается по схеме "один против одного".
Для подробного математического описания предоставленных функций ядра и того, как
gamma,coef0иdegreeвлияют друг на друга, см. соответствующий раздел в повествовательной документации: Функции ядра.Чтобы узнать, как настраивать гиперпараметры SVC, см. следующий пример: Вложенная и невложенная перекрестная проверка
Подробнее в Руководство пользователя.
- Параметры:
- Cfloat, по умолчанию=1.0
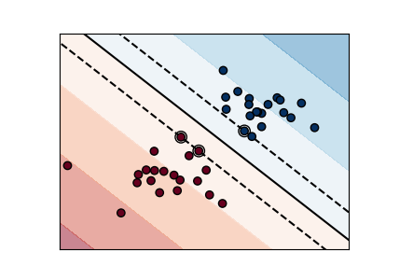
Параметр регуляризации. Сила регуляризации обратно пропорциональна C. Должен быть строго положительным. Штраф является квадратичным штрафом l2. Для интуитивной визуализации эффектов масштабирования параметра регуляризации C см. Масштабирование параметра регуляризации для SVC.
- ядро{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} или вызываемый объект, по умолчанию=’rbf’
Указывает тип ядра, используемый в алгоритме. Если ничего не указано, будет использоваться ‘rbf’. Если указана вызываемая функция, она используется для предварительного вычисления матрицы ядра из матриц данных; эта матрица должна быть массивом формы
(n_samples, n_samples). Для интуитивной визуализации различных типов ядер см. Построение границ классификации с различными ядрами SVM.- степеньint, по умолчанию=3
Степень полиномиальной ядерной функции ('poly'). Должна быть неотрицательной. Игнорируется всеми другими ядрами.
- gamma{‘scale’, ‘auto’} или float, по умолчанию='scale'
Коэффициент ядра для 'rbf', 'poly' и 'sigmoid'.
if
gamma='scale'(по умолчанию) передается, тогда используется 1 / (n_features * X.var()) в качестве значения gamma,если 'auto', использует 1 / n_features
если float, должно быть неотрицательным.
Изменено в версии 0.22: Значение по умолчанию для
gammaизменено с 'auto' на 'scale'.- coef0float, по умолчанию=0.0
Независимый член в ядерной функции. Значим только для 'poly' и 'sigmoid'.
- сжатиеbool, по умолчанию=True
Использовать ли эвристику сжатия. См. Руководство пользователя.
- вероятностьbool, по умолчанию=False
Включить ли оценку вероятностей. Это должно быть включено до вызова
fit, замедлит этот метод, так как он внутренне использует 5-кратную кросс-валидацию, иpredict_probaможет быть несовместимым сpredict. Подробнее в Руководство пользователя.- tolfloat, по умолчанию=1e-3
Допуск для критерия остановки.
- cache_sizefloat, default=200
Укажите размер кэша ядра (в МБ).
- class_weightdict или 'balanced', по умолчанию=None
Установите параметр C для класса i в class_weight[i]*C для SVC. Если не задано, предполагается, что все классы имеют вес один. Режим 'balanced' использует значения y для автоматической настройки весов, обратно пропорциональных частотам классов во входных данных, как
n_samples / (n_classes * np.bincount(y)).- verbosebool, по умолчанию=False
Включить подробный вывод. Обратите внимание, что этот параметр использует настройку времени выполнения на процесс в libsvm, которая, если включена, может работать некорректно в многопоточном контексте.
- max_iterint, по умолчанию=-1
Жесткое ограничение на итерации внутри решателя, или -1 для отсутствия ограничения.
- decision_function_shape{‘ovo’, ‘ovr’}, по умолчанию ‘ovr’
Возвращать ли функцию принятия решений 'один против всех' ('ovr') формы (n_samples, n_classes) как у всех других классификаторов, или оригинальную функцию принятия решений 'один против одного' ('ovo') из libsvm, которая имеет форму (n_samples, n_classes * (n_classes - 1) / 2). Однако обратите внимание, что внутри всегда используется стратегия 'один против одного' ('ovo') для обучения многоклассовых моделей; матрица ovr строится только из матрицы ovo. Параметр игнорируется для бинарной классификации.
Изменено в версии 0.19: decision_function_shape по умолчанию имеет значение 'ovr'.
Добавлено в версии 0.17: decision_function_shape='ovr' рекомендуется.
Изменено в версии 0.17: Устаревший decision_function_shape='ovo' и None.
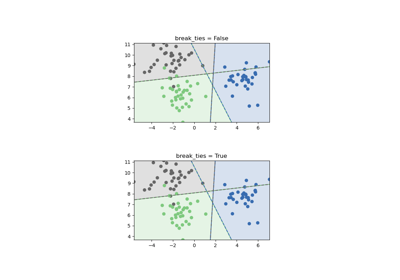
- break_tiesbool, по умолчанию=False
Если true,
decision_function_shape='ovr', и количество классов > 2, predict будет разрешать ничьи в соответствии со значениями достоверности decision_function; в противном случае возвращается первый класс среди связанных классов. Обратите внимание, что разрешение связей требует относительно высоких вычислительных затрат по сравнению с простым предсказанием. См. Пример разрешения ничьей в SVM для примера его использования сdecision_function_shape='ovr'.Добавлено в версии 0.22.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет псевдослучайной генерацией чисел для перемешивания данных при оценке вероятностей. Игнорируется, когда
probabilityравно False. Передайте int для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.
- Атрибуты:
- class_weight_ndarray формы (n_classes,)
Множители параметра C для каждого класса. Вычисляются на основе
class_weightпараметр.- classes_ndarray формы (n_classes,)
Метки классов.
coef_ndarray формы (n_classes * (n_classes - 1) / 2, n_features)Веса, присвоенные признакам, когда
kernel="linear".- dual_coef_ndarray формы (n_classes -1, n_SV)
Двойные коэффициенты опорного вектора в функции принятия решений (см. Математическая формулировка), умноженные на их цели. Для многоклассовой классификации, коэффициент для всех классификаторов 1-vs-1. Расположение коэффициентов в многоклассовом случае несколько нетривиально. См. раздел многоклассовой классификации в руководстве пользователя подробности.
- fit_status_int
0, если модель корректно обучена, 1 в противном случае (будет выдано предупреждение)
- intercept_ndarray формы (n_classes * (n_classes - 1) / 2,)
Константы в функции принятия решений.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_ndarray формы (n_classes * (n_classes - 1) // 2,)
Количество итераций, выполняемых процедурой оптимизации для обучения модели. Форма этого атрибута зависит от количества оптимизированных моделей, которое в свою очередь зависит от количества классов.
Добавлено в версии 1.1.
- support_ndarray формы (n_SV)
Индексы опорных векторов.
- support_vectors_ndarray формы (n_SV, n_features)
Опорные векторы. Пустой массив, если ядро предвычислено.
n_support_ndarray формы (n_classes,), dtype=int32Количество опорных векторов для каждого класса.
probA_ndarray формы (n_classes * (n_classes - 1) / 2)Параметр, изученный при масштабировании Платта, когда
probability=True.probB_ndarray формы (n_classes * (n_classes - 1) / 2)Параметр, изученный при масштабировании Платта, когда
probability=True.- shape_fit_кортеж int формы (n_dimensions_of_X,)
Размерности массива обучающего вектора
X.
Смотрите также
Ссылки
Примеры
>>> import numpy as np >>> from sklearn.pipeline import make_pipeline >>> from sklearn.preprocessing import StandardScaler >>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]]) >>> y = np.array([1, 1, 2, 2]) >>> from sklearn.svm import SVC >>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto')) >>> clf.fit(X, y) Pipeline(steps=[('standardscaler', StandardScaler()), ('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]])) [1]
Для сравнения SVC с другими классификаторами см.: Построить график вероятности классификации.
- decision_function(X)[источник]#
Оценить функцию принятия решений для выборок в X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Xndarray формы (n_samples, n_classes * (n_classes-1) / 2)
Возвращает функцию принятия решения для каждого класса в модели. Если decision_function_shape='ovr', форма (n_samples, n_classes).
Примечания
Если decision_function_shape='ovo', значения функции пропорциональны расстоянию образцов X до разделяющей гиперплоскости. Если требуются точные расстояния, разделите значения функции на норму вектора весов (
coef_). См. также этот вопрос для получения дополнительных сведений. Если decision_function_shape='ovr', функция принятия решений является монотонным преобразованием функции принятия решений ovo.
- fit(X, y, sample_weight=None)[источник]#
Обучите модель SVM в соответствии с предоставленными обучающими данными.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples)
Обучающие векторы, где
n_samplesэто количество образцов иn_features— это количество признаков. Для kernel="precomputed" ожидаемая форма X — (n_samples, n_samples).- yarray-like формы (n_samples,)
Целевые значения (метки классов в классификации, вещественные числа в регрессии).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса для каждого образца. Масштабируют C для каждого образца. Более высокие веса заставляют классификатор уделять больше внимания этим точкам.
- Возвращает:
- selfobject
Обученный оценщик.
Примечания
Если X и y не являются C-упорядоченными и непрерывными массивами np.float64 и X не является scipy.sparse.csr_matrix, X и/или y могут быть скопированы.
Если X является плотным массивом, то другие методы не будут поддерживать разреженные матрицы в качестве входных данных.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Выполняет классификацию для выборок в X.
Для одноклассовой модели возвращается +1 или -1.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples_test, n_samples_train)
Для kernel="precomputed" ожидаемая форма X (n_samples_test, n_samples_train).
- Возвращает:
- y_predndarray формы (n_samples,)
Метки классов для образцов в X.
- predict_log_proba(X)[источник]#
Вычислить логарифмы вероятностей возможных исходов для выборок в X.
Модель должна иметь информацию о вероятностях, вычисленную во время обучения: обучение с атрибутом
probabilityустановлено в True.- Параметры:
- Xarray-like формы (n_samples, n_features) или (n_samples_test, n_samples_train)
Для kernel="precomputed" ожидаемая форма X (n_samples_test, n_samples_train).
- Возвращает:
- Tndarray формы (n_samples, n_classes)
Возвращает логарифмы вероятностей выборки для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
Примечания
Вероятностная модель создается с использованием перекрестной проверки, поэтому результаты могут немного отличаться от полученных с помощью predict. Кроме того, она даст бессмысленные результаты на очень маленьких наборах данных.
- predict_proba(X)[источник]#
Вычислите вероятности возможных исходов для выборок в X.
Модель должна иметь информацию о вероятностях, вычисленную во время обучения: обучение с атрибутом
probabilityустановлено в True.- Параметры:
- Xarray-like формы (n_samples, n_features)
Для kernel="precomputed" ожидаемая форма X (n_samples_test, n_samples_train).
- Возвращает:
- Tndarray формы (n_samples, n_classes)
Возвращает вероятность образца для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
Примечания
Вероятностная модель создается с использованием перекрестной проверки, поэтому результаты могут немного отличаться от полученных с помощью predict. Кроме того, она даст бессмысленные результаты на очень маленьких наборах данных.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') SVC[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
Пример распознавания лиц с использованием собственных лиц и SVM


Объединение нескольких методов извлечения признаков

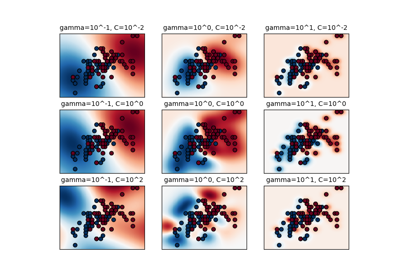
Масштабируемое обучение с полиномиальной аппроксимацией ядра
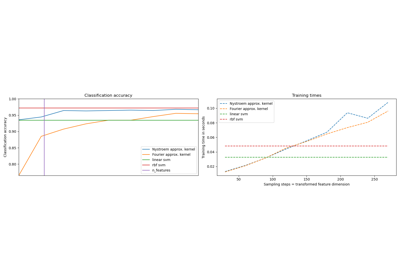
Аппроксимация явного отображения признаков для RBF-ядер


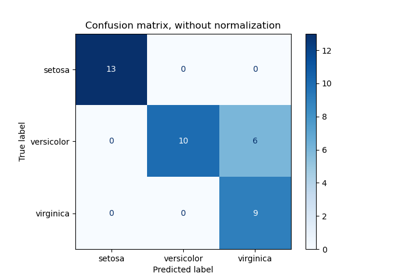
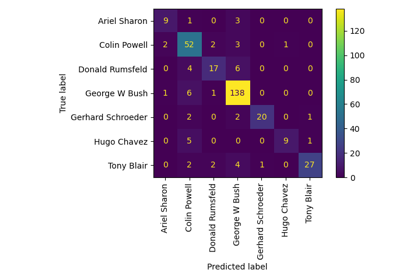
Оценить производительность классификатора с помощью матрицы ошибок

Пользовательская стратегия повторного обучения для поиска по сетке с кросс-валидацией
Статистическое сравнение моделей с использованием поиска по сетке
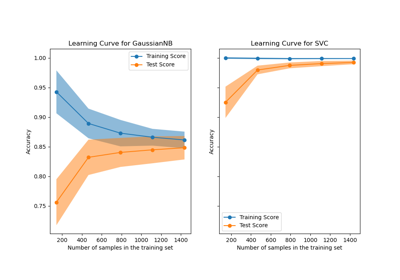
Построение кривых обучения и проверка масштабируемости моделей


Тест с перестановками для значимости оценки классификации
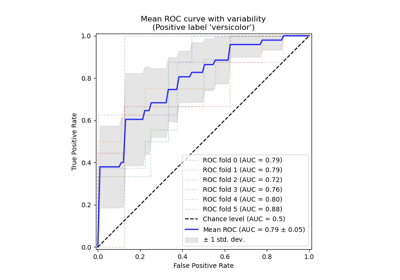
Рабочая характеристика приёмника (ROC) с перекрёстной проверкой
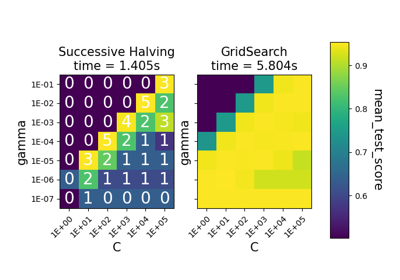
Сравнение между поиском по сетке и последовательным сокращением вдвое

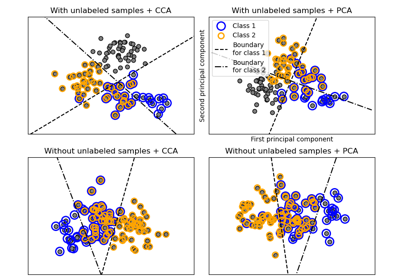
Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris
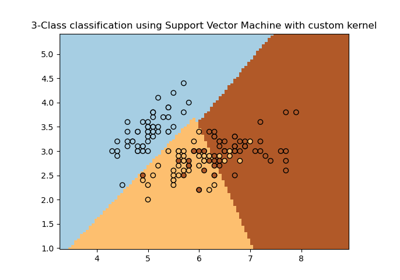
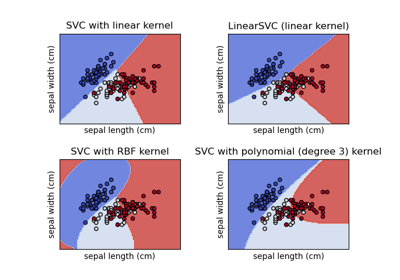
Построение различных классификаторов SVM на наборе данных iris
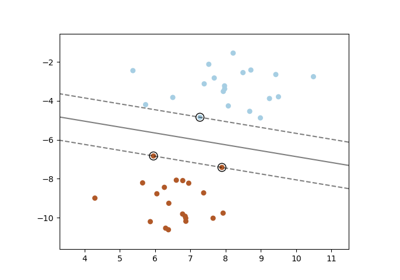
SVM: Разделяющая гиперплоскость с максимальным зазором

SVM: Разделяющая гиперплоскость для несбалансированных классов
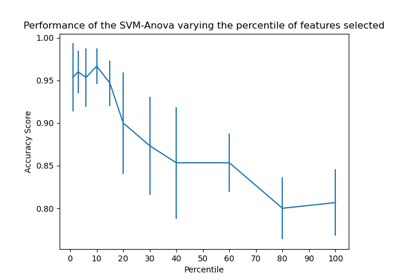
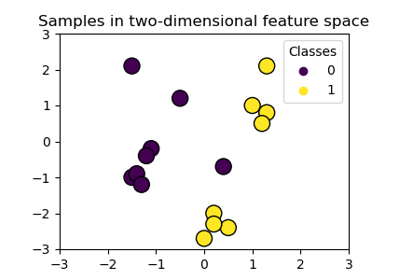
Построение границ классификации с различными ядрами SVM