Примечание
Перейти в конец чтобы скачать полный пример кода или запустить этот пример в браузере через JupyterLite или Binder.
SVM-Anova: SVM с одномерным отбором признаков#
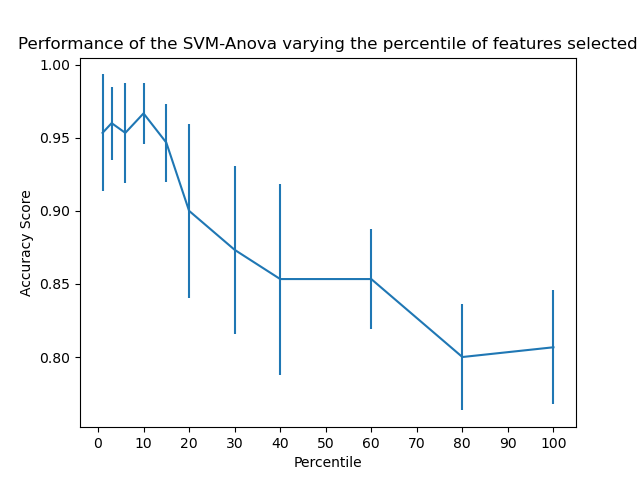
Этот пример показывает, как выполнить одномерный отбор признаков перед запуском SVC (классификатора опорных векторов) для улучшения оценок классификации. Мы используем набор данных iris (4 признака) и добавляем 36 неинформативных признаков. Мы можем обнаружить, что наша модель достигает наилучшей производительности, когда мы выбираем около 10% признаков.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Загрузите некоторые данные для работы#
import numpy as np
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
# Add non-informative features
rng = np.random.RandomState(0)
X = np.hstack((X, 2 * rng.random((X.shape[0], 36))))
Создать конвейер#
from sklearn.feature_selection import SelectPercentile, f_classif
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# Create a feature-selection transform, a scaler and an instance of SVM that we
# combine together to have a full-blown estimator
clf = Pipeline(
[
("anova", SelectPercentile(f_classif)),
("scaler", StandardScaler()),
("svc", SVC(gamma="auto")),
]
)
Построить график оценки перекрестной проверки в зависимости от процентиля признаков#
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
score_means = list()
score_stds = list()
percentiles = (1, 3, 6, 10, 15, 20, 30, 40, 60, 80, 100)
for percentile in percentiles:
clf.set_params(anova__percentile=percentile)
this_scores = cross_val_score(clf, X, y)
score_means.append(this_scores.mean())
score_stds.append(this_scores.std())
plt.errorbar(percentiles, score_means, np.array(score_stds))
plt.title("Performance of the SVM-Anova varying the percentile of features selected")
plt.xticks(np.linspace(0, 100, 11, endpoint=True))
plt.xlabel("Percentile")
plt.ylabel("Accuracy Score")
plt.axis("tight")
plt.show()
Общее время выполнения скрипта: (0 минут 0.297 секунд)
Связанные примеры

Объединение нескольких методов извлечения признаков
Объединение нескольких методов извлечения признаков
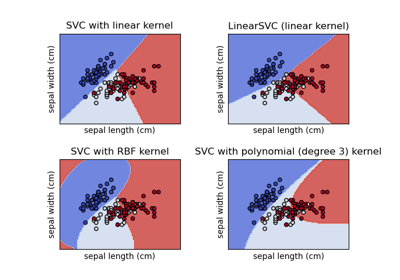
Построение различных классификаторов SVM на наборе данных iris
Построение различных классификаторов SVM на наборе данных iris