GaussianNB#
- класс sklearn.naive_bayes.GaussianNB(*, априорные вероятности=None, var_smoothing=1e-09)[источник]#
Гауссовский наивный байесовский классификатор (GaussianNB).
Может выполнять онлайн-обновления параметров модели через
partial_fit. Подробности об алгоритме, используемом для онлайн-обновления средних значений и дисперсий признаков, см. в Технический отчет Stanford CS STAN-CS-79-773 от Chan, Golub и LeVeque.Подробнее в Руководство пользователя.
- Параметры:
- априорные вероятностиarray-like формы (n_classes,), по умолчанию=None
Априорные вероятности классов. Если указаны, априорные вероятности не корректируются в соответствии с данными.
- var_smoothingfloat, по умолчанию=1e-9
Часть наибольшей дисперсии всех признаков, которая добавляется к дисперсиям для стабильности вычислений.
Добавлено в версии 0.20.
- Атрибуты:
- class_count_ndarray формы (n_classes,)
количество обучающих выборок, наблюдаемых в каждом классе.
- class_prior_ndarray формы (n_classes,)
вероятность каждого класса.
- classes_ndarray формы (n_classes,)
метки классов, известные классификатору.
- epsilon_float
абсолютное аддитивное значение для дисперсий.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- var_ndarray формы (n_classes, n_features)
Дисперсия каждого признака по классам.
Добавлено в версии 1.0.
- theta_ndarray формы (n_classes, n_features)
среднее значение каждого признака по классу.
Смотрите также
BernoulliNBНаивный байесовский классификатор для многомерных моделей Бернулли.
CategoricalNBНаивный байесовский классификатор для категориальных признаков.
ComplementNBКомплементарный наивный байесовский классификатор.
MultinomialNBНаивный байесовский классификатор для мультиномиальных моделей.
Примеры
>>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> Y = np.array([1, 1, 1, 2, 2, 2]) >>> from sklearn.naive_bayes import GaussianNB >>> clf = GaussianNB() >>> clf.fit(X, Y) GaussianNB() >>> print(clf.predict([[-0.8, -1]])) [1] >>> clf_pf = GaussianNB() >>> clf_pf.partial_fit(X, Y, np.unique(Y)) GaussianNB() >>> print(clf_pf.predict([[-0.8, -1]])) [1]
- fit(X, y, sample_weight=None)[источник]#
Обучить наивный байесовский классификатор по X, y.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие векторы, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевые значения.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса, применяемые к отдельным образцам (1. для невзвешенных).
Добавлено в версии 0.17: Наивный байесовский классификатор Гаусса поддерживает обучение с sample_weight.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X, y, классы=None, sample_weight=None)[источник]#
Инкрементное обучение на пакете образцов.
Этот метод предназначен для многократного последовательного вызова на различных частях набора данных для реализации внеядерного или онлайн-обучения.
Это особенно полезно, когда весь набор данных слишком велик, чтобы поместиться в память сразу.
Этот метод имеет некоторые накладные расходы на производительность и численную устойчивость, поэтому лучше вызывать partial_fit на блоках данных, которые максимально велики (в пределах доступной памяти), чтобы скрыть эти накладные расходы.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевые значения.
- классыarray-like формы (n_classes,), по умолчанию=None
Список всех классов, которые могут появиться в векторе y.
Должен быть предоставлен при первом вызове partial_fit, может быть опущен в последующих вызовах.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса, применяемые к отдельным образцам (1. для невзвешенных).
Добавлено в версии 0.17.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- predict(X)[источник]#
Выполнить классификацию на массиве тестовых векторов X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Cndarray формы (n_samples,)
Предсказанные целевые значения для X.
- predict_joint_log_proba(X)[источник]#
Возвращает совместные оценки логарифмической вероятности для тестового вектора X.
Для каждой строки x из X и класса y совместная логарифмическая вероятность задается как
log P(x, y) = log P(y) + log P(x|y),гдеlog P(y)является априорной вероятностью класса иlog P(x|y)является условной вероятностью класса.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Cndarray формы (n_samples, n_classes)
Возвращает совместную логарифмическую вероятность выборок для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- predict_log_proba(X)[источник]#
Возвращает оценки логарифмической вероятности для тестового вектора X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Carray-like формы (n_samples, n_classes)
Возвращает логарифм вероятности образцов для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- predict_proba(X)[источник]#
Возвращает оценки вероятности для тестового вектора X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные образцы.
- Возвращает:
- Carray-like формы (n_samples, n_classes)
Возвращает вероятность выборок для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianNB[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, классы: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') GaussianNB[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- классыstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
classesпараметр вpartial_fit.- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianNB[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
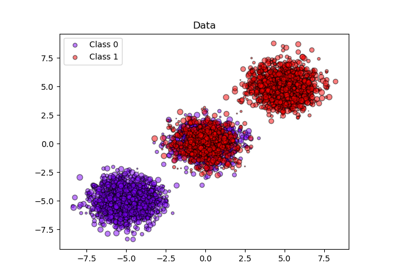
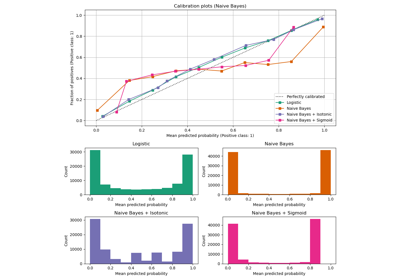
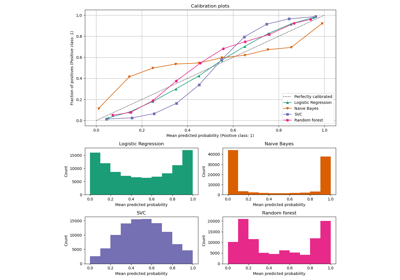

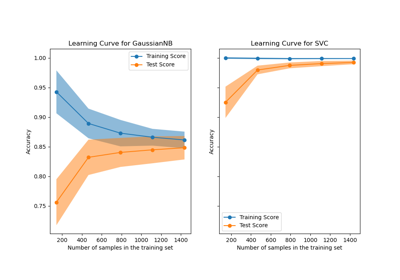
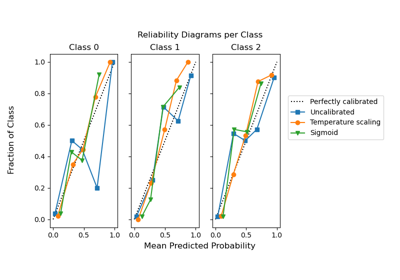
Построение кривых обучения и проверка масштабируемости моделей