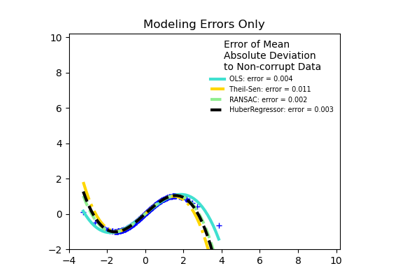
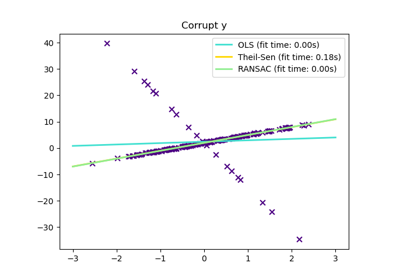
RANSACRegressor#
- класс sklearn.linear_model.RANSACRegressor(estimator=None, *, min_samples=None, residual_threshold=None, is_data_valid=None, is_model_valid=None, max_trials=100, max_skips=inf, stop_n_inliers=inf, stop_score=inf, stop_probability=0.99, потеря='absolute_error', random_state=None)[источник]#
Алгоритм RANSAC (RANdom SAmple Consensus).
RANSAC — это итеративный алгоритм для робастной оценки параметров из подмножества инлайеров из полного набора данных.
Подробнее в Руководство пользователя.
- Параметры:
- estimatorobject, default=None
Базовый объект оценщика, который реализует следующие методы:
fit(X, y): Обучить модель на предоставленных обучающих данных и целевых значениях.score(X, y): Возвращает среднюю точность на заданных тестовых данных, которая используется для критерия остановки, определенногоstop_score. Кроме того, оценка используется для выбора, какой из двух одинаково больших консенсусных наборов считается лучшим.predict(X): Возвращает предсказанные значения с использованием линейной модели, которая используется для вычисления остаточной ошибки с помощью функции потерь.
Если
estimatorравно None, тогдаLinearRegressionиспользуется для целевых значений типа float.Обратите внимание, что текущая реализация поддерживает только регрессионные оценщики.
- min_samplesint (>= 1) или float ([0, 1]), default=None
Минимальное количество выборок, случайно выбранных из исходных данных. Рассматривается как абсолютное количество выборок для
min_samples >= 1, рассматриваемое как относительное числоceil(min_samples * X.shape[0])дляmin_samples < 1. Обычно выбирается как минимальное количество образцов, необходимое для оценки данногоestimator. По умолчаниюLinearRegressionпредполагается, что оценщик иmin_samplesвыбирается какX.shape[1] + 1. Этот параметр сильно зависит от модели, поэтому еслиestimatorкромеLinearRegressionиспользуется, пользователь должен предоставить значение.- residual_thresholdfloat, по умолчанию=None
Максимальный остаток для выборки данных, чтобы она была классифицирована как нормальная. По умолчанию порог выбирается как MAD (медианное абсолютное отклонение) целевых значений
y. Точки, чьи остатки строго равны порогу, считаются выбросами.- is_data_validвызываемый объект, по умолчанию=None
Эта функция вызывается со случайно выбранными данными перед тем, как модель обучается на них:
is_data_valid(X, y). Если его возвращаемое значение равно False, текущий случайно выбранный подвыборок пропускается.- is_model_validвызываемый объект, по умолчанию=None
Эта функция вызывается с оцененной моделью и случайно выбранными данными:
is_model_valid(model, X, y). Если его возвращаемое значение False, текущая случайно выбранная подвыборка пропускается. Отклонение выборок с этой функцией вычислительно дороже, чем сis_data_valid.is_model_validпоэтому следует использовать только если оцененная модель необходима для принятия решения об отклонении.- max_trialsint, по умолчанию=100
Максимальное количество итераций для случайного выбора образцов.
- max_skipsint, по умолчанию=np.inf
Максимальное количество итераций, которые можно пропустить из-за нахождения нулевых внутренних точек или недопустимых данных, определенных
is_data_validили недопустимые модели, определенныеis_model_valid.Добавлено в версии 0.19.
- stop_n_inliersint, по умолчанию=np.inf
Остановить итерацию, если найдено хотя бы это количество выбросов.
- stop_scorefloat, по умолчанию=np.inf
Остановить итерацию, если оценка больше или равна этому порогу.
- stop_probabilityfloat в диапазоне [0, 1], по умолчанию=0.99
Итерация RANSAC останавливается, если хотя бы один набор обучающих данных без выбросов выбран в RANSAC. Это требует генерации как минимум N образцов (итераций):
N >= log(1 - probability) / log(1 - e**m)
где вероятность (уверенность) обычно устанавливается на высокое значение, например 0.99 (по умолчанию), а e - текущая доля инлайеров относительно общего количества образцов.
- потеряstr, callable, default='absolute_error'
Поддерживаются строковые входы ‘absolute_error’ и ‘squared_error’, которые находят абсолютную ошибку и квадратичную ошибку на каждый образец соответственно.
Если
lossявляется вызываемым объектом, то это должна быть функция, принимающая два массива в качестве входных данных — истинные и предсказанные значения — и возвращающая одномерный массив, где i-е значение массива соответствует потере наX[i].Если потери на образце превышают
residual_threshold, тогда этот образец классифицируется как выброс.Добавлено в версии 0.18.
- random_stateint, экземпляр RandomState, по умолчанию=None
Генератор, используемый для инициализации центров. Передайте целое число для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.
- Атрибуты:
- estimator_object
Финальная модель, обученная на инлайнах, предсказанных «лучшей» моделью, найденной во время выборки RANSAC (копия
estimatorобъект).- n_trials_int
Количество попыток случайного выбора до достижения одного из критериев остановки. Это всегда
<= max_trials.- inlier_mask_логический массив формы [n_samples]
Булева маска невыбросов, классифицированных как
True.- n_skips_no_inliers_int
Количество итераций, пропущенных из-за обнаружения нулевых инлайеров.
Добавлено в версии 0.19.
- n_skips_invalid_data_int
Количество итераций, пропущенных из-за недопустимых данных, определенных
is_data_valid.Добавлено в версии 0.19.
- n_skips_invalid_model_int
Количество итераций, пропущенных из-за невалидной модели, определённой
is_model_valid.Добавлено в версии 0.19.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
HuberRegressorЛинейная регрессионная модель, устойчивая к выбросам.
TheilSenRegressorМногомерная регрессионная модель Theil-Sen Estimator, устойчивая к выбросам.
SGDRegressorПодгоняется путем минимизации регуляризованной эмпирической потери с помощью SGD.
Ссылки
Примеры
>>> from sklearn.linear_model import RANSACRegressor >>> from sklearn.datasets import make_regression >>> X, y = make_regression( ... n_samples=200, n_features=2, noise=4.0, random_state=0) >>> reg = RANSACRegressor(random_state=0).fit(X, y) >>> reg.score(X, y) 0.9885 >>> reg.predict(X[:1,]) array([-31.9417])
Для более подробного примера см. Робастная оценка линейной модели с использованием RANSAC
- fit(X, y, sample_weight=None, **fit_params)[источник]#
Обучить оценщик с использованием алгоритма RANSAC.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные.
- yмассивоподобный формы (n_samples,) или (n_samples, n_targets)
Целевые значения.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Индивидуальные веса для каждой выборки вызывают ошибку, если sample_weight передаётся, а метод fit оценщика не поддерживает его.
Добавлено в версии 0.18.
- **fit_paramsdict
Параметры, перенаправленные в
fitметод суб-оценщика через API маршрутизации метаданных.Добавлено в версии 1.5: Доступно только если
sklearn.set_config(enable_metadata_routing=True)установлено. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- selfobject
Обученная
RANSACRegressorоценщик.
- Вызывает:
- ValueError
Если не удалось найти допустимый консенсусный набор. Это происходит, если
is_data_validиis_model_validвозвращает False для всехmax_trialsслучайно выбранные подвыборки.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.5.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X, **params)[источник]#
Прогнозирование с использованием оцененной модели.
Это обёртка для
estimator_.predict(X).- Параметры:
- X{array-like или разреженная матрица} формы (n_samples, n_features)
Входные данные.
- **paramsdict
Параметры, перенаправленные в
predictметод под-оценщика через API маршрутизации метаданных.Добавлено в версии 1.5: Доступно только если
sklearn.set_config(enable_metadata_routing=True)установлено. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- yarray, форма = [n_samples] или [n_samples, n_targets]
Возвращает предсказанные значения.
- score(X, y, **params)[источник]#
Возвращает оценку предсказания.
Это обёртка для
estimator_.score(X, y).- Параметры:
- X(массивоподобный или разреженная матрица) формы (n_samples, n_features)
Обучающие данные.
- yмассивоподобный формы (n_samples,) или (n_samples, n_targets)
Целевые значения.
- **paramsdict
Параметры, перенаправленные в
scoreметод под-оценщика через API маршрутизации метаданных.Добавлено в версии 1.5: Доступно только если
sklearn.set_config(enable_metadata_routing=True)установлено. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- zfloat
Оценка предсказания.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RANSACRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
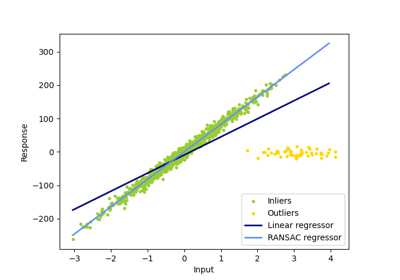
Робастная оценка линейной модели с использованием RANSAC