KNeighborsRegressor#
- класс sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, *, веса='uniform', алгоритм='auto', leaf_size=30, p=2, метрика='minkowski', metric_params=None, n_jobs=None)[источник]#
Регрессия на основе k ближайших соседей.
Целевая переменная предсказывается путем локальной интерполяции целевых значений, связанных с ближайшими соседями в обучающей выборке.
Подробнее в Руководство пользователя.
Добавлено в версии 0.9.
- Параметры:
- n_neighborsint, по умолчанию=5
Количество соседей для использования по умолчанию для
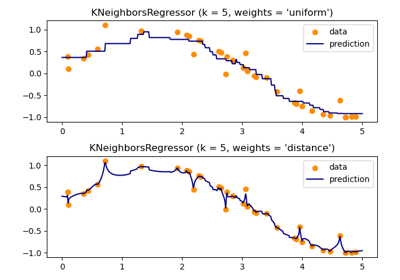
kneighborsзапросы.- веса{‘uniform’, ‘distance’}, вызываемый или None, по умолчанию=’uniform’
Функция веса, используемая в предсказании. Возможные значения:
‘uniform’ : равномерные веса. Все точки в каждом соседстве взвешиваются одинаково.
'distance' : взвешивать точки обратно пропорционально их расстоянию. в этом случае ближайшие соседи точки запроса будут иметь большее влияние, чем соседи, находящиеся дальше.
ndarray типа float формы=(len(list(cv)),)
По умолчанию используются равномерные веса.
Смотрите следующий пример для демонстрации влияния различных схем взвешивания на предсказания: Регрессия методом ближайших соседей.
- алгоритм{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, по умолчанию=’auto’
Алгоритм, используемый для вычисления ближайших соседей:
'ball_tree' будет использовать
BallTree'kd_tree' будет использовать
KDTree'brute' будет использовать поиск методом грубой силы.
'auto' попытается определить наиболее подходящий алгоритм на основе значений, переданных в
fitметод.
Примечание: обучение на разреженных входных данных переопределит настройку этого параметра, используя метод грубой силы.
- leaf_sizeint, по умолчанию=30
Размер листа, передаваемый в BallTree или KDTree. Это может влиять на скорость построения и запросов, а также на память, требуемую для хранения дерева. Оптимальное значение зависит от характера задачи.
- pfloat, по умолчанию=2
Степенной параметр для метрики Минковского. При p = 1 это эквивалентно использованию manhattan_distance (l1) и euclidean_distance (l2) при p = 2. Для произвольного p используется minkowski_distance (l_p).
- метрикаstr, объект DistanceMetric или вызываемый объект, по умолчанию='minkowski'
Метрика для вычисления расстояния. По умолчанию “minkowski”, что дает стандартное евклидово расстояние при p = 2. См. документацию scipy.spatial.distance и метрики, перечисленные в
distance_metricsдля допустимых значений метрик.Если метрика "precomputed", X считается матрицей расстояний и должна быть квадратной во время подгонки. X может быть разреженный граф, в этом случае только "ненулевые" элементы могут считаться соседями.
Если metric - вызываемая функция, она принимает два массива, представляющих 1D векторы, в качестве входных данных и должна возвращать одно значение, указывающее расстояние между этими векторами. Это работает для метрик Scipy, но менее эффективно, чем передача имени метрики в виде строки.
Если metric является объектом DistanceMetric, он будет передан непосредственно в базовые вычислительные процедуры.
- metric_paramsdict, по умолчанию=None
Дополнительные именованные аргументы для метрической функции.
- n_jobsint, default=None
Количество параллельных задач для поиска соседей.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительных подробностей. Не затрагиваетfitметод.
- Атрибуты:
- effective_metric_str или callable
Метрика расстояния для использования. Она будет такой же, как
metricпараметр или его синоним, например, 'euclidean', еслиmetricПараметр установлен в ‘minkowski’ иpпараметр установлен в 2.- effective_metric_params_dict
Дополнительные ключевые аргументы для функции метрики. Для большинства метрик будут такими же, как в
metric_paramsпараметр, но также может содержатьpзначение параметра, еслиeffective_metric_атрибут установлен в ‘minkowski’.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_samples_fit_int
Количество образцов в обученных данных.
Смотрите также
NearestNeighborsНеконтролируемый обучающийся для реализации поиска соседей.
RadiusNeighborsRegressorРегрессия на основе соседей в пределах фиксированного радиуса.
KNeighborsClassifierКлассификатор, реализующий голосование k ближайших соседей.
RadiusNeighborsClassifierКлассификатор, реализующий голосование среди соседей в заданном радиусе.
Примечания
См. Ближайшие соседи в онлайн-документации для обсуждения выбора
algorithmиleaf_size.Предупреждение
Что касается алгоритмов ближайших соседей, если обнаружено, что два соседа, сосед
k+1иk, имеют одинаковые расстояния, но разные метки, результаты будут зависеть от порядка обучающих данных.https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
Примеры
>>> X = [[0], [1], [2], [3]] >>> y = [0, 0, 1, 1] >>> from sklearn.neighbors import KNeighborsRegressor >>> neigh = KNeighborsRegressor(n_neighbors=2) >>> neigh.fit(X, y) KNeighborsRegressor(...) >>> print(neigh.predict([[1.5]])) [0.5]
- fit(X, y)[источник]#
Обучите регрессор k-ближайших соседей на обучающем наборе данных.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features) или (n_samples, n_samples) если metric='precomputed'
Обучающие данные.
- y{array-like, sparse matrix} формы (n_samples,) или (n_samples, n_outputs)
Целевые значения.
- Возвращает:
- selfKNeighborsRegressor
Обученный регрессор k-ближайших соседей.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- kneighbors(X=None, n_neighbors=None, return_distance=True)[источник]#
Найти K ближайших соседей точки.
Возвращает индексы и расстояния до соседей каждой точки.
- Параметры:
- X{array-like, sparse matrix}, shape (n_queries, n_features), или (n_queries, n_indexed) если metric == 'precomputed', default=None
Точка или точки запроса. Если не указано, возвращаются соседи каждой индексированной точки. В этом случае точка запроса не считается своим собственным соседом.
- n_neighborsint, default=None
Количество соседей, требуемых для каждого образца. По умолчанию используется значение, переданное конструктору.
- return_distancebool, по умолчанию=True
Возвращать ли расстояния.
- Возвращает:
- neigh_distndarray формы (n_queries, n_neighbors)
Массив, представляющий длины до точек, присутствует только если return_distance=True.
- neigh_indndarray формы (n_queries, n_neighbors)
Индексы ближайших точек в матрице популяции.
Примеры
В следующем примере мы создаем класс NearestNeighbors из массива, представляющего наш набор данных, и спрашиваем, какая точка ближе всего к [1,1,1]
>>> samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=1) >>> neigh.fit(samples) NearestNeighbors(n_neighbors=1) >>> print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]]))
Как видите, он возвращает [[0.5]] и [[2]], что означает, что элемент находится на расстоянии 0.5 и является третьим элементом выборок (индексы начинаются с 0). Вы также можете запросить несколько точек:
>>> X = [[0., 1., 0.], [1., 0., 1.]] >>> neigh.kneighbors(X, return_distance=False) array([[1], [2]]...)
- kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')[источник]#
Вычислить (взвешенный) граф k-ближайших соседей для точек в X.
- Параметры:
- X{array-like, sparse matrix} формы (n_queries, n_features), или (n_queries, n_indexed) если metric == ‘precomputed’, default=None
Точка или точки запроса. Если не предоставлено, возвращаются соседи каждой индексированной точки. В этом случае точка запроса не считается своим собственным соседом. Для
metric='precomputed'форма должна быть (n_queries, n_indexed). В противном случае форма должна быть (n_queries, n_features).- n_neighborsint, default=None
Количество соседей для каждой выборки. По умолчанию используется значение, переданное конструктору.
- mode{'connectivity', 'distance'}, по умолчанию='connectivity'
Тип возвращаемой матрицы: 'connectivity' вернет матрицу связности с единицами и нулями, в 'distance' ребра являются расстояниями между точками, тип расстояния зависит от выбранного параметра metric в классе NearestNeighbors.
- Возвращает:
- Aразреженная матрица формы (n_queries, n_samples_fit)
n_samples_fitэто количество образцов в подогнанных данных.A[i, j]дает вес ребра, соединяющегоitoj. Матрица имеет формат CSR.
Смотрите также
NearestNeighbors.radius_neighbors_graphВычислить (взвешенный) граф соседей для точек в X.
Примеры
>>> X = [[0], [3], [1]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=2) >>> neigh.fit(X) NearestNeighbors(n_neighbors=2) >>> A = neigh.kneighbors_graph(X) >>> A.toarray() array([[1., 0., 1.], [0., 1., 1.], [1., 0., 1.]])
- predict(X)[источник]#
Предсказать целевую переменную для предоставленных данных.
- Параметры:
- X{array-like, sparse matrix} формы (n_queries, n_features), или (n_queries, n_indexed) если metric == ‘precomputed’, или None
Тестовые образцы. Если
None, предсказания для всех индексированных точек возвращаются; в этом случае точки не считаются своими собственными соседями.
- Возвращает:
- yndarray формы (n_queries,) или (n_queries, n_outputs), dtype=int
Целевые значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KNeighborsRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
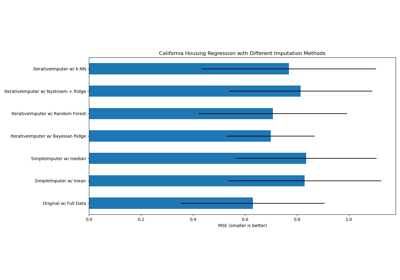
Заполнение пропущенных значений с вариантами IterativeImputer

Завершение лица с помощью многоканальных оценщиков