GaussianProcessClassifier#
- класс sklearn.gaussian_process.GaussianProcessClassifier(ядро=None, *, оптимизатор='fmin_l_bfgs_b', n_restarts_optimizer=0, max_iter_predict=100, warm_start=False, copy_X_train=True, random_state=None, multi_class='one_vs_rest', n_jobs=None)[источник]#
Гауссовский процесс классификации (GPC) на основе аппроксимации Лапласа.
Реализация основана на алгоритмах 3.1, 3.2 и 5.1 из [RW2006].
Внутренне используется аппроксимация Лапласа для приближения негауссовского апостериорного распределения гауссовским.
В настоящее время реализация ограничена использованием логистической функции связи. Для многоклассовой классификации обучается несколько бинарных классификаторов 'один против всех'. Обратите внимание, что этот класс, таким образом, не реализует истинное многоклассовое приближение Лапласа.
Подробнее в Руководство пользователя.
Добавлено в версии 0.18.
- Параметры:
- ядроэкземпляр ядра, по умолчанию=None
Ядро, определяющее ковариационную функцию GP. Если передано None, используется ядро "1.0 * RBF(1.0)" по умолчанию. Обратите внимание, что гиперпараметры ядра оптимизируются во время обучения. Также ядро не может быть
CompoundKernel.- оптимизатор'fmin_l_bfgs_b', callable или None, по умолчанию='fmin_l_bfgs_b'
Может быть одним из внутренне поддерживаемых оптимизаторов для оптимизации параметров ядра, указанных строкой, или внешне определенным оптимизатором, переданным как вызываемый объект. Если передан вызываемый объект, он должен иметь сигнатуру:
def optimizer(obj_func, initial_theta, bounds): # * 'obj_func' is the objective function to be maximized, which # takes the hyperparameters theta as parameter and an # optional flag eval_gradient, which determines if the # gradient is returned additionally to the function value # * 'initial_theta': the initial value for theta, which can be # used by local optimizers # * 'bounds': the bounds on the values of theta .... # Returned are the best found hyperparameters theta and # the corresponding value of the target function. return theta_opt, func_min
По умолчанию используется алгоритм 'L-BFGS-B' из scipy.optimize.minimize. Если передано None, параметры ядра остаются фиксированными. Доступные внутренние оптимизаторы:
'fmin_l_bfgs_b'- n_restarts_optimizerint, по умолчанию=0
Количество перезапусков оптимизатора для поиска параметров ядра, которые максимизируют логарифмическую маргинальную вероятность. Первый запуск оптимизатора выполняется из начальных параметров ядра, остальные (если есть) — из тета, выбранных лог-равномерно случайным образом из пространства допустимых значений тета. Если больше 0, все границы должны быть конечными. Заметим, что n_restarts_optimizer=0 означает, что выполняется один запуск.
- max_iter_predictint, по умолчанию=100
Максимальное количество итераций в методе Ньютона для аппроксимации апостериорного распределения во время предсказания. Меньшие значения уменьшат время вычислений за счёт ухудшения результатов.
- warm_startbool, по умолчанию=False
Если включены теплые старты, решение последней итерации Ньютона на аппроксимации Лапласа апостериорной моды используется как инициализация для следующего вызова _posterior_mode(). Это может ускорить сходимость, когда _posterior_mode вызывается несколько раз на схожих задачах, как при оптимизации гиперпараметров. См. Глоссарий.
- copy_X_trainbool, по умолчанию=True
Если True, постоянная копия обучающих данных хранится в объекте. В противном случае хранится только ссылка на обучающие данные, что может вызвать изменение прогнозов, если данные изменены извне.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел, используемую для инициализации центров. Передайте целое число для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.
- multi_class{‘one_vs_rest’, ‘one_vs_one’}, по умолчанию=’one_vs_rest’
Определяет, как обрабатываются задачи многоклассовой классификации. Поддерживаются 'one_vs_rest' и 'one_vs_one'. В 'one_vs_rest' для каждого класса подгоняется один бинарный классификатор Гауссовского процесса, который обучается отделять этот класс от остальных. В 'one_vs_one' для каждой пары классов подгоняется один бинарный классификатор Гауссовского процесса, который обучается отделять эти два класса. Предсказания этих бинарных предикторов объединяются в многоклассовые предсказания. Обратите внимание, что 'one_vs_one' не поддерживает предсказание вероятностных оценок.
- n_jobsint, default=None
Количество заданий для вычисления: указанные многоклассовые задачи вычисляются параллельно.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.
- Атрибуты:
- base_estimator_
Estimatorэкземпляр Экземпляр оценщика, который определяет функцию правдоподобия с использованием наблюдаемых данных.
kernel_экземпляр ядраВозвращает ядро базового оценщика.
- log_marginal_likelihood_value_float
Логарифмическая маргинальная вероятность
self.kernel_.theta- classes_array-like формы (n_classes,)
Уникальные метки классов.
- n_classes_int
Количество классов в обучающих данных
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- base_estimator_
Смотрите также
GaussianProcessRegressorГауссовский процесс регрессии (GPR).
Ссылки
Примеры
>>> from sklearn.datasets import load_iris >>> from sklearn.gaussian_process import GaussianProcessClassifier >>> from sklearn.gaussian_process.kernels import RBF >>> X, y = load_iris(return_X_y=True) >>> kernel = 1.0 * RBF(1.0) >>> gpc = GaussianProcessClassifier(kernel=kernel, ... random_state=0).fit(X, y) >>> gpc.score(X, y) 0.9866... >>> gpc.predict_proba(X[:2,:]) array([[0.83548752, 0.03228706, 0.13222543], [0.79064206, 0.06525643, 0.14410151]])
Для сравнения GaussianProcessClassifier с другими классификаторами см.: Построить график вероятности классификации.
- fit(X, y)[источник]#
Обучить модель гауссовского процесса классификации.
- Параметры:
- Xarray-like формы (n_samples, n_features) или список объектов
Векторы признаков или другие представления обучающих данных.
- yarray-like формы (n_samples,)
Целевые значения должны быть бинарными.
- Возвращает:
- selfobject
Возвращает экземпляр self.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- latent_mean_and_variance(X)[источник]#
Вычислите среднее значение и дисперсию латентной функции.
На основе алгоритма 3.2 из [RW2006], эта функция возвращает скрытое среднее (строка 4) и дисперсию (строка 6) модели классификации гауссовского процесса.
Обратите внимание, что эта функция поддерживается только для бинарной классификации.
Добавлено в версии 1.7.
- Параметры:
- Xarray-like формы (n_samples, n_features) или список объектов
Точки запроса, где GP оценивается для классификации.
- Возвращает:
- latent_meanarray-like формы (n_samples,)
Среднее значение латентной функции в точках запроса.
- latent_vararray-like формы (n_samples,)
Дисперсия значений латентной функции в точках запроса.
- log_marginal_likelihood(theta=None, eval_gradient=False, clone_kernel=True)[источник]#
Вернуть логарифм маргинального правдоподобия тета для обучающих данных.
В случае многоклассовой классификации возвращается среднее логарифмическое маргинальное правдоподобие классификаторов один-против-всех.
- Параметры:
- thetaarray-like формы (n_kernel_params,), по умолчанию=None
Гиперпараметры ядра, для которых вычисляется логарифмическая маргинальная вероятность. В случае многоклассовой классификации theta может быть гиперпараметрами составного ядра или отдельного ядра. В последнем случае всем отдельным ядрам присваиваются одинаковые значения theta. Если None, используется предвычисленная log_marginal_likelihood
self.kernel_.thetaвозвращается.- eval_gradientbool, по умолчанию=False
Если True, дополнительно возвращается градиент логарифма маргинального правдоподобия по гиперпараметрам ядра в позиции theta. Обратите внимание, что вычисление градиента не поддерживается для небинарной классификации. Если True, theta не должен быть None.
- clone_kernelbool, по умолчанию=True
Если True, атрибут kernel копируется. Если False, атрибут kernel изменяется, но это может привести к повышению производительности.
- Возвращает:
- логарифмическое правдоподобиеfloat
Логарифмическая маргинальная вероятность тета для обучающих данных.
- градиент логарифмического правдоподобияndarray формы (n_kernel_params,), опционально
Градиент логарифмической маргинальной вероятности по гиперпараметрам ядра в позиции theta. Возвращается только, когда
eval_gradientравно True.
- predict(X)[источник]#
Выполнить классификацию на массиве тестовых векторов X.
- Параметры:
- Xarray-like формы (n_samples, n_features) или список объектов
Точки запроса, где GP оценивается для классификации.
- Возвращает:
- Cndarray формы (n_samples,)
Предсказанные целевые значения для X, значения из
classes_.
- predict_proba(X)[источник]#
Возвращает оценки вероятности для тестового вектора X.
- Параметры:
- Xarray-like формы (n_samples, n_features) или список объектов
Точки запроса, где GP оценивается для классификации.
- Возвращает:
- Carray-like формы (n_samples, n_classes)
Возвращает вероятность выборок для каждого класса в модели. Столбцы соответствуют классам в отсортированном порядке, как они появляются в атрибуте classes_.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianProcessClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#

Вероятностные предсказания с гауссовским процессом классификации (GPC)
Гауссовский процесс классификации (GPC) на наборе данных iris
Изолинии равной вероятности для классификации гауссовских процессов (GPC)
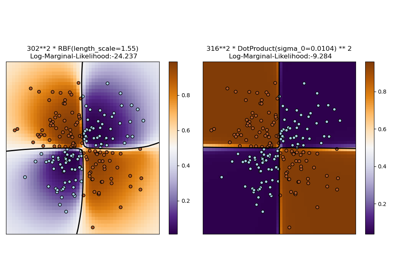
Иллюстрация классификации гауссовским процессом (GPC) на наборе данных XOR
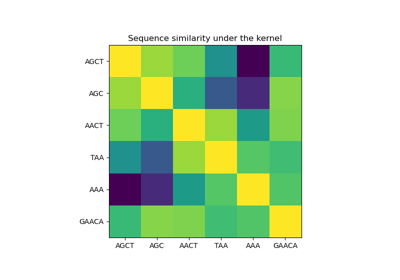
Гауссовские процессы на дискретных структурах данных