OneVsRestClassifier#
- класс sklearn.multiclass.OneVsRestClassifier(estimator, *, n_jobs=None, verbose=0)[источник]#
Стратегия многоклассовой классификации "один против всех" (OvR).
Также известная как "один против всех", эта стратегия заключается в обучении одного классификатора на каждый класс. Для каждого классификатора класс обучается против всех остальных классов. В дополнение к своей вычислительной эффективности (только
n_classesклассификаторы необходимы), одним из преимуществ этого подхода является его интерпретируемость. Поскольку каждый класс представлен одним и только одним классификатором, можно получить знания о классе, исследуя соответствующий ему классификатор. Это наиболее часто используемая стратегия для многоклассовой классификации и является разумным выбором по умолчанию.OneVsRestClassifier также может использоваться для многометочной классификации. Чтобы использовать эту функцию, предоставьте индикаторную матрицу для целевой переменной
yпри вызове.fit. Другими словами, целевые метки должны быть отформатированы как 2D бинарная (0/1) матрица, где [i, j] == 1 указывает на наличие метки j в образце i. Этот оценщик использует метод бинарной релевантности для выполнения многометочной классификации, который включает обучение одного бинарного классификатора независимо для каждой метки.Подробнее в Руководство пользователя.
- Параметры:
- estimatorобъект оценщика
Регрессор или классификатор, реализующий fit. Когда передаётся классификатор, decision_function будет использоваться в приоритете, и он вернется к predict_proba если он не доступен. Когда регрессор передан, predict используется.
- n_jobsint, default=None
Количество заданий для вычисления:
n_classesзадачи one-vs-rest вычисляются параллельно.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.Изменено в версии 0.20:
n_jobsзначение по умолчанию изменено с 1 на None- verboseint, по умолчанию=0
Уровень детализации, если не ноль, печатаются сообщения о прогрессе. Ниже 50 вывод отправляется в stderr. В противном случае вывод отправляется в stdout. Частота сообщений увеличивается с уровнем детализации, отчитываясь обо всех итерациях на уровне 10. См.
joblib.Parallelдля более подробной информации.Добавлено в версии 1.1.
- Атрибуты:
- estimators_список
n_classesоценщики Оценщики, используемые для предсказаний.
- classes_массив, форма = [
n_classes] Метки классов.
n_classes_intКоличество классов.
- label_binarizer_Объект LabelBinarizer
Объект, используемый для преобразования мультиклассовых меток в бинарные метки и наоборот.
multilabel_логическийЯвляется ли это многометочным классификатором.
- n_features_in_int
Количество признаков, замеченных во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Добавлено в версии 1.0.
- estimators_список
Смотрите также
OneVsOneClassifierМногоклассовая стратегия "один против одного".
OutputCodeClassifier(Error-Correcting) Output-Code стратегия многоклассовой классификации.
sklearn.multioutput.MultiOutputClassifierАльтернативный способ расширения оценщика для многоклассовой классификации.
sklearn.preprocessing.MultiLabelBinarizerПреобразование итерируемого объекта из итерируемых объектов в бинарную индикаторную матрицу.
Примеры
>>> import numpy as np >>> from sklearn.multiclass import OneVsRestClassifier >>> from sklearn.svm import SVC >>> X = np.array([ ... [10, 10], ... [8, 10], ... [-5, 5.5], ... [-5.4, 5.5], ... [-20, -20], ... [-15, -20] ... ]) >>> y = np.array([0, 0, 1, 1, 2, 2]) >>> clf = OneVsRestClassifier(SVC()).fit(X, y) >>> clf.predict([[-19, -20], [9, 9], [-5, 5]]) array([2, 0, 1])
- decision_function(X)[источник]#
Решающая функция для OneVsRestClassifier.
Возвращает расстояние каждого образца от границы принятия решений для каждого класса. Это можно использовать только с оценщиками, которые реализуют
decision_functionметод.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные данные.
- Возвращает:
- Tмассивоподобный формы (n_samples, n_classes) или (n_samples,) для бинарной классификации.
Результат вызова
decision_functionна финальном оценщике.Изменено в версии 0.19: форма вывода изменена на
(n_samples,)чтобы соответствовать соглашениям scikit-learn для бинарной классификации.
- fit(X, y, **fit_params)[источник]#
Обучение базовых оценщиков.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные.
- y{array-like, sparse matrix} формы (n_samples,) или (n_samples, n_classes)
Многоклассовые цели. Матрица индикаторов включает многометочную классификацию.
- **fit_paramsdict
Параметры, передаваемые в
estimator.fitметод каждого подоценщика.Добавлено в версии 1.4: Доступно только если
enable_metadata_routing=True. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- selfobject
Экземпляр обученного оценщика.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.4.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X, y, классы=None, **partial_fit_params)[источник]#
Частичное обучение базовых оценщиков.
Следует использовать, когда память неэффективна для обучения всех данных. Части данных могут передаваться за несколько итераций.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные.
- y{array-like, sparse matrix} формы (n_samples,) или (n_samples, n_classes)
Многоклассовые цели. Матрица индикаторов включает многометочную классификацию.
- классымассив, форма (n_classes, )
Классы во всех вызовах partial_fit. Можно получить через
np.unique(y_all), где y_all — целевой вектор всего набора данных. Этот аргумент требуется только при первом вызове partial_fit и может быть опущен в последующих вызовах.- **partial_fit_paramsdict
Параметры, передаваемые в
estimator.partial_fitметод каждого подоценщика.Добавлено в версии 1.4: Доступно только если
enable_metadata_routing=True. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- selfobject
Экземпляр частично обученного оценщика.
- predict(X)[источник]#
Предсказать многоклассовые цели с использованием базовых оценщиков.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные.
- Возвращает:
- y{array-like, sparse matrix} формы (n_samples,) или (n_samples, n_classes)
Предсказанные многоклассовые цели.
- predict_proba(X)[источник]#
Оценки вероятностей.
Возвращаемые оценки для всех классов упорядочены по меткам классов.
Обратите внимание, что в случае многометочной классификации каждый образец может иметь любое количество меток. Это возвращает маргинальную вероятность того, что данный образец имеет рассматриваемую метку. Например, вполне возможно, что две метки обе имеют 90% вероятность применения к данному образцу.
В случае однозначной многоклассовой классификации строки возвращаемой матрицы суммируются до 1.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- Возвращает:
- Tarray-like формы (n_samples, n_classes)
Возвращает вероятность выборки для каждого класса в модели, где классы упорядочены так, как они находятся в
self.classes_.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, классы: bool | None | str = '$UNCHANGED$') OneVsRestClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- классыstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
classesпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') OneVsRestClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
Границы решений мультиномиальной и логистической регрессии One-vs-Rest
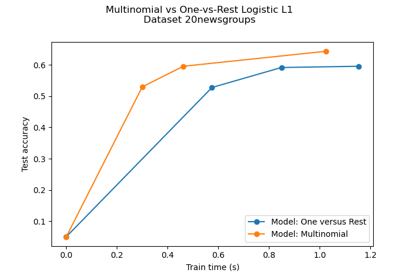
Многоклассовая разреженная логистическая регрессия на 20newsgroups
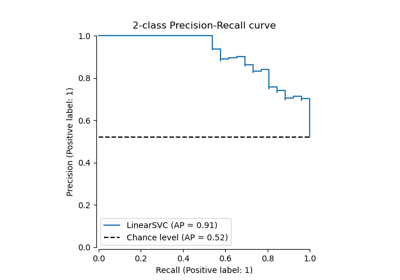
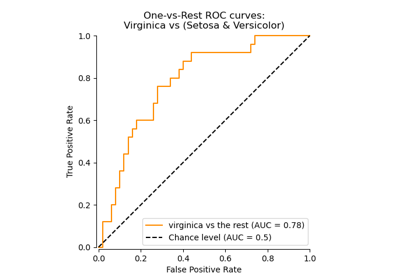
Многоклассовая рабочая характеристика приемника (ROC)
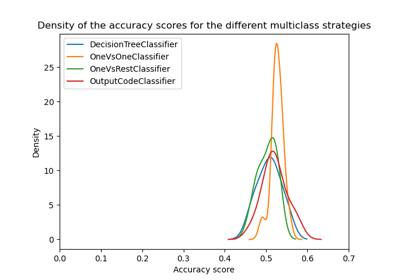
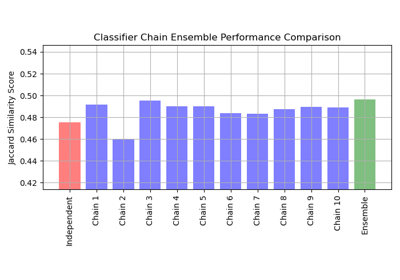
Многометочная классификация с использованием цепочки классификаторов