PLSRegression#
- класс sklearn.cross_decomposition.PLSRegression(n_components=2, *, scale=True, max_iter=500, tol=1e-06, copy=True)[источник]#
PLS регрессия.
PLSRegression также известен как PLS2 или PLS1, в зависимости от количества целевых переменных.
Для сравнения с другими алгоритмами перекрестного разложения см. Сравнить методы перекрёстного разложения.
Подробнее в Руководство пользователя.
Добавлено в версии 0.8.
- Параметры:
- n_componentsint, по умолчанию=2
Количество компонентов для сохранения. Должно быть в
[1, n_features].- scalebool, по умолчанию=True
Масштабировать ли
Xиy.- max_iterint, по умолчанию=500
Максимальное количество итераций степенного метода, когда
algorithm='nipals'. Игнорируется в противном случае.- tolfloat, default=1e-06
Допуск, используемый как критерий сходимости в степенном методе: алгоритм останавливается, когда квадрат нормы
u_i - u_{i-1}меньше, чемtol, гдеuсоответствует левому сингулярному вектору.- copybool, по умолчанию=True
Копировать ли
Xиyв fit перед применением центрирования и потенциального масштабирования. ЕслиFalse, эти операции будут выполнены на месте, изменяя оба массива.
- Атрибуты:
- x_weights_ndarray формы (n_features, n_components)
Левые сингулярные векторы кросс-ковариационных матриц каждой итерации.
- y_weights_ndarray формы (n_targets, n_components)
Правые сингулярные векторы ковариационных матриц каждой итерации.
- x_loadings_ndarray формы (n_features, n_components)
. Successive Halving — это итеративный процесс отбора, проиллюстрированный на рисунке ниже. Первая итерация выполняется с небольшим количеством ресурсов, где ресурс обычно соответствует количеству обучающих выборок, но также может быть произвольным целочисленным параметром, таким как
X.- y_loadings_ndarray формы (n_targets, n_components)
. Successive Halving — это итеративный процесс отбора, проиллюстрированный на рисунке ниже. Первая итерация выполняется с небольшим количеством ресурсов, где ресурс обычно соответствует количеству обучающих выборок, но также может быть произвольным целочисленным параметром, таким как
y.- x_scores_ndarray формы (n_samples, n_components)
Преобразованные обучающие образцы.
- y_scores_ndarray формы (n_samples, n_components)
Преобразованные целевые значения обучения.
- x_rotations_ndarray формы (n_features, n_components)
Матрица проекции, используемая для преобразования
X.- y_rotations_ndarray формы (n_targets, n_components)
Матрица проекции, используемая для преобразования
y.- coef_ndarray формы (n_target, n_features)
Коэффициенты линейной модели такие, что
yаппроксимируется какy = X @ coef_.T + intercept_.- intercept_ndarray формы (n_targets,)
Свободные члены линейной модели такие, что
yаппроксимируется какy = X @ coef_.T + intercept_.Добавлено в версии 1.1.
- n_iter_список формы (n_components,)
Количество итераций степенного метода для каждого компонента.
- n_features_in_int
Количество признаков, замеченных во время fit.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
PLSCanonicalПреобразователь и регрессор частичных наименьших квадратов.
Примеры
>>> from sklearn.cross_decomposition import PLSRegression >>> X = [[0., 0., 1.], [1.,0.,0.], [2.,2.,2.], [2.,5.,4.]] >>> y = [[0.1, -0.2], [0.9, 1.1], [6.2, 5.9], [11.9, 12.3]] >>> pls2 = PLSRegression(n_components=2) >>> pls2.fit(X, y) PLSRegression() >>> y_pred = pls2.predict(X)
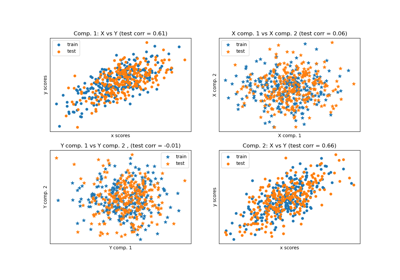
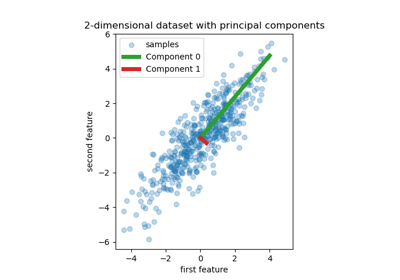
Для сравнения между PLS регрессией и
PCA, см. Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов.- fit(X, y)[источник]#
Обучить модель на данных.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество предикторов.- yмассивоподобный формы (n_samples,) или (n_samples, n_targets)
Целевые векторы, где
n_samples— это количество образцов иn_targets— это количество переменных отклика.
- Возвращает:
- selfobject
Обученная модель.
- fit_transform(X, y=None)[источник]#
Обучиться и применить уменьшение размерности к обучающим данным.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество предикторов.- yarray-like формы (n_samples, n_targets), по умолчанию=None
Целевые векторы, где
n_samples— это количество образцов иn_targets— это количество переменных отклика.
- Возвращает:
- selfndarray формы (n_samples, n_components)
Возвращает
x_scoresifyне задан,(x_scores, y_scores)в противном случае.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X, y=None)[источник]#
Преобразование данных обратно в исходное пространство.
- Параметры:
- Xarray-like формы (n_samples, n_components)
Новые данные, где
n_samplesэто количество образцов иn_components— это число компонентов pls.- yarray-like формы (n_samples,) или (n_samples, n_components)
Новая цель, где
n_samplesэто количество образцов иn_components— это число компонентов pls.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Возвращает реконструированный
Xdata.- y_originalndarray формы (n_samples, n_targets)
Возвращает реконструированный
X#32077yзадано.
Примечания
Это преобразование будет точным только если
n_components=n_features.
- predict(X, copy=True)[источник]#
Предсказать целевые значения для заданных образцов.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Образцы.
- copybool, по умолчанию=True
Копировать ли
Xили выполнить нормализацию на месте.
- Возвращает:
- y_predndarray формы (n_samples,) или (n_samples, n_targets)
Возвращает предсказанные значения.
Примечания
Этот вызов требует оценки матрицы формы
(n_features, n_targets)что может быть проблемой в пространстве высокой размерности.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_predict_request(*, copy: bool | None | str = '$UNCHANGED$') PLSRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
predictметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpredictесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpredict.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вpredict.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') PLSRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') PLSRegression[источник]#
Настроить, следует ли запрашивать передачу метаданных в
transformметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяtransformесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вtransform.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вtransform.
- Возвращает:
- selfobject
Обновленный объект.
- преобразовать(X, y=None, copy=True)[источник]#
Применить уменьшение размерности.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Образцы для преобразования.
- yarray-like формы (n_samples, n_targets), по умолчанию=None
Целевые векторы.
- copybool, по умолчанию=True
Копировать ли
Xиyили выполнять нормализацию на месте.
- Возвращает:
- x_scores, y_scoresarray-like или кортеж из array-like
Возвращает
x_scoresifyне задан,(x_scores, y_scores)в противном случае.
Примеры галереи#
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов