MLPClassifier#
- класс sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100,), активация='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, перемешивание=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, эпсилон=1e-08, n_iter_no_change=10, max_fun=15000)[источник]#
Многослойный перцептрон-классификатор.
Эта модель оптимизирует функцию логарифмической потери, используя LBFGS или стохастический градиентный спуск.
Добавлено в версии 0.18.
- Параметры:
- hidden_layer_sizesarray-like формы (n_layers - 2,), по умолчанию=(100,)
i-й элемент представляет количество нейронов в i-м скрытом слое.
- активация{'identity', 'logistic', 'tanh', 'relu'}, default='relu'
Функция активации для скрытого слоя.
‘identity’, активация без операции, полезна для реализации линейного узкого места, возвращает f(x) = x
‘logistic’, логистическая сигмоидная функция, возвращает f(x) = 1 / (1 + exp(-x)).
'tanh', гиперболическая функция тангенса, возвращает f(x) = tanh(x).
‘relu’, функция выпрямленного линейного блока, возвращает f(x) = max(0, x)
- solver{‘lbfgs’, ‘sgd’, ‘adam’}, по умолчанию=’adam’
Решатель для оптимизации весов.
'lbfgs' — это оптимизатор из семейства квазиньютоновских методов.
'sgd' относится к стохастическому градиентному спуску.
'adam' относится к стохастическому оптимизатору на основе градиента, предложенному Kingma, Diederik и Jimmy Ba
Для сравнения оптимизатора Adam и SGD см. Сравнение стохастических стратегий обучения для MLPClassifier.
Примечание: Решатель по умолчанию 'adam' хорошо работает на относительно больших наборах данных (с тысячами обучающих выборок или более) как по времени обучения, так и по валидационной оценке. Однако для небольших наборов данных 'lbfgs' может сходиться быстрее и работать лучше.
- alphafloat, по умолчанию=0.0001
Сила члена регуляризации L2. Член регуляризации L2 делится на размер выборки при добавлении к функции потерь.
Пример использования и визуализации изменения регуляризации см. в Изменение регуляризации в многослойном перцептроне.
- batch_sizeint, по умолчанию='auto'
Размер мини-пакетов для стохастических оптимизаторов. Если решатель 'lbfgs', классификатор не будет использовать мини-пакеты. При установке в "auto",
batch_size=min(200, n_samples).- learning_rate{'constant', 'invscaling', 'adaptive'}, по умолчанию='constant'
Расписание скорости обучения для обновления весов.
'constant' — постоянная скорость обучения, заданная 'learning_rate_init'.
'invscaling' постепенно уменьшает скорость обучения на каждом временном шаге 't', используя обратный масштабирующий показатель 'power_t'. эффективная_скорость_обучения = learning_rate_init / pow(t, power_t)
‘adaptive’ сохраняет скорость обучения постоянной на уровне ‘learning_rate_init’, пока ошибка обучения продолжает уменьшаться. Каждый раз, когда две последовательные эпохи не уменьшают ошибку обучения как минимум на tol, или не увеличивают оценку валидации как минимум на tol, если включен ‘early_stopping’, текущая скорость обучения делится на 5.
Используется только когда
solver='sgd'.- learning_rate_initfloat, по умолчанию=0.001
Начальная скорость обучения. Она контролирует размер шага при обновлении весов. Используется только при solver='sgd' или 'adam'.
- power_tfloat, по умолчанию=0.5
Показатель степени для обратного масштабирования скорости обучения. Используется при обновлении эффективной скорости обучения, когда learning_rate установлен в 'invscaling'. Используется только при solver='sgd'.
- max_iterint, default=200
Максимальное количество итераций. Решатель итерирует до сходимости (определяемой 'tol') или этого количества итераций. Для стохастических решателей ('sgd', 'adam') обратите внимание, что это определяет количество эпох (сколько раз каждая точка данных будет использована), а не количество шагов градиента.
- перемешиваниеbool, по умолчанию=True
Перемешивать ли выборки на каждой итерации. Используется только при solver='sgd' или 'adam'.
- random_stateint, экземпляр RandomState, по умолчанию=None
Определяет генерацию случайных чисел для инициализации весов и смещения, разделения на обучающую и тестовую выборки, если используется ранняя остановка, и пакетной выборки, когда решатель='sgd' или 'adam'. Передайте int для воспроизводимых результатов при множественных вызовах функций. См. Глоссарий.
- tolfloat, по умолчанию=1e-4
Допуск для оптимизации. Когда потери или оценка не улучшаются как минимум на
tolдляn_iter_no_changeпоследовательных итераций, если толькоlearning_rateустановлен в 'adaptive', считается, что сходимость достигнута и обучение останавливается.- verbosebool, по умолчанию=False
Выводить ли сообщения о прогрессе в stdout.
- warm_startbool, по умолчанию=False
При установке значения True повторно используется решение предыдущего вызова fit в качестве инициализации, в противном случае предыдущее решение просто удаляется. См. Глоссарий.
- momentumfloat, default=0.9
Импульс для обновления градиентного спуска. Должен быть между 0 и 1. Используется только при solver='sgd'.
- nesterovs_momentumbool, по умолчанию=True
Использовать ли импульс Нестерова. Используется только при solver='sgd' и momentum > 0.
- early_stoppingbool, по умолчанию=False
Использовать ли раннюю остановку для завершения обучения, когда оценка валидации не улучшается. Если установлено в True, автоматически будет выделено
validation_fractionобучающих данных в качестве валидации и прекратить обучение, когда оценка валидации не улучшается как минимум наtolдляn_iter_no_changeпоследовательных эпох. Разделение стратифицировано, за исключением многометочной настройки. Если ранний останов ложен, то обучение останавливается, когда потери обучения не улучшаются более чем наtolдляn_iter_no_changeпоследовательные проходы по обучающему набору. Эффективно только при solver='sgd' или 'adam'.- validation_fractionfloat, по умолчанию=0.1
Доля обучающих данных, которую следует отложить в качестве проверочного набора для ранней остановки. Должна быть между 0 и 1. Используется только если early_stopping равно True.
- beta_1float, default=0.9
Скорость экспоненциального затухания для оценок вектора первого момента в adam, должна быть в [0, 1). Используется только при solver='adam'.
- beta_2float, по умолчанию=0.999
Скорость экспоненциального затухания для оценок вектора второго момента в adam, должна быть в [0, 1). Используется только при solver='adam'.
- эпсилонfloat, по умолчанию=1e-8
Значение для численной стабильности в Adam. Используется только при solver='adam'.
- n_iter_no_changeint, по умолчанию=10
Максимальное количество эпох, в течение которых не выполняется
tolулучшение. Эффективно только при solver='sgd' или 'adam'.Добавлено в версии 0.20.
- max_funint, по умолчанию=15000
Используется только при solver='lbfgs'. Максимальное количество вызовов функции потерь. Солвер итерирует до сходимости (определяемой 'tol'), пока количество итераций не достигнет max_iter или этого количества вызовов функции потерь. Обратите внимание, что количество вызовов функции потерь будет больше или равно количеству итераций для
MLPClassifier.Добавлено в версии 0.22.
- Атрибуты:
- classes_ndarray или список ndarray формы (n_classes,)
Метки классов для каждого выхода.
- loss_float
Текущая потеря, вычисленная с помощью функции потерь.
- best_loss_float или None
Минимальная потеря, достигнутая решателем в процессе обучения. Если
early_stopping=True, этот атрибут установлен вNone. См.best_validation_score_обученный атрибут вместо.- loss_curve_4. Маршрутизация метаданных
n_iter_,) i-й элемент в списке представляет потерю на i-й итерации.
- validation_scores_4. Маршрутизация метаданных
n_iter_,) или None Оценка на каждой итерации на отложенном валидационном наборе. Сообщаемая оценка — это точность. Доступно только если
early_stopping=True, в противном случае атрибут устанавливается вNone.- best_validation_score_float или None
Наилучший результат валидации (т.е. показатель точности), который вызвал раннюю остановку. Доступно только если
early_stopping=True, иначе атрибут устанавливается вNone.- t_int
Количество обучающих выборок, обработанных решателем во время обучения.
- coefs_список формы (n_layers - 1,)
i-й элемент в списке представляет матрицу весов, соответствующую слою i.
- intercepts_список формы (n_layers - 1,)
i-й элемент в списке представляет вектор смещения, соответствующий слою i + 1.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество итераций, выполненных решателем.
- n_layers_int
Количество слоёв.
- n_outputs_int
Количество выходов.
- out_activation_str
Название выходной функции активации.
Смотрите также
MLPRegressorМногослойный перцептрон-регрессор.
BernoulliRBMБернуллиевская ограниченная машина Больцмана (RBM).
Примечания
MLPClassifier обучается итеративно, поскольку на каждом шаге вычисляются частные производные функции потерь по параметрам модели для обновления параметров.
Он также может иметь регуляризационный член, добавленный к функции потерь, который сжимает параметры модели для предотвращения переобучения.
Эта реализация работает с данными, представленными в виде плотных массивов numpy или разреженных массивов scipy значений с плавающей точкой.
Ссылки
Hinton, Geoffrey E. “Connectionist learning procedures.” Artificial intelligence 40.1 (1989): 185-234.
Glorot, Xavier, and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks.” International Conference on Artificial Intelligence and Statistics. 2010.
Kingma, Diederik, и Jimmy Ba (2014) «Adam: метод стохастической оптимизации.»
Примеры
>>> from sklearn.neural_network import MLPClassifier >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> X, y = make_classification(n_samples=100, random_state=1) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, ... random_state=1) >>> clf = MLPClassifier(random_state=1, max_iter=300).fit(X_train, y_train) >>> clf.predict_proba(X_test[:1]) array([[0.0383, 0.961]]) >>> clf.predict(X_test[:5, :]) array([1, 0, 1, 0, 1]) >>> clf.score(X_test, y_test) 0.8...
- fit(X, y, sample_weight=None)[источник]#
Обучает модель на матрице данных X и целевых значениях y.
- Параметры:
- Xndarray или разреженная матрица формы (n_samples, n_features)
Входные данные.
- yndarray формы (n_samples,) или (n_samples, n_outputs)
Целевые значения (метки классов в классификации, вещественные числа в регрессии).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
Добавлено в версии 1.7.
- Возвращает:
- selfobject
Возвращает обученную модель MLP.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- partial_fit(X, y, sample_weight=None, классы=None)[источник]#
Обновление модели с одной итерацией по предоставленным данным.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- yarray-like формы (n_samples,)
Целевые значения.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
Добавлено в версии 1.7.
- классымассив формы (n_classes,), default=None
Классы во всех вызовах partial_fit. Можно получить через
np.unique(y_all), где y_all — целевой вектор всего набора данных. Этот аргумент требуется для первого вызова partial_fit и может быть опущен в последующих вызовах. Обратите внимание, что y не обязательно должен содержать все метки вclasses.
- Возвращает:
- selfobject
Обученная модель MLP.
- predict(X)[источник]#
Предсказание с использованием классификатора многослойного перцептрона.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- Возвращает:
- yndarray, форма (n_samples,) или (n_samples, n_classes)
Предсказанные классы.
- predict_log_proba(X)[источник]#
Возвращает логарифм оценок вероятности.
- Параметры:
- Xndarray формы (n_samples, n_features)
Входные данные.
- Возвращает:
- log_y_probndarray формы (n_samples, n_classes)
Предсказанная логарифмическая вероятность выборки для каждого класса в модели, где классы упорядочены так, как они находятся в
self.classes_. Эквивалентноlog(predict_proba(X)).
- predict_proba(X)[источник]#
Оценки вероятностей.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Входные данные.
- Возвращает:
- y_probndarray формы (n_samples, n_classes)
Предсказанная вероятность выборки для каждого класса в модели, где классы упорядочены так, как они находятся в
self.classes_.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MLPClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, классы: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') MLPClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- классыstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
classesпараметр вpartial_fit.- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') MLPClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#

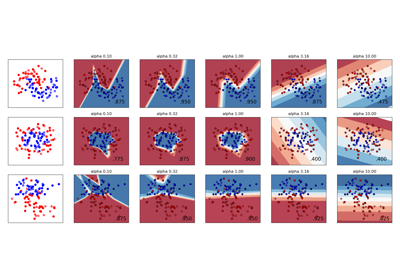
Изменение регуляризации в многослойном перцептроне
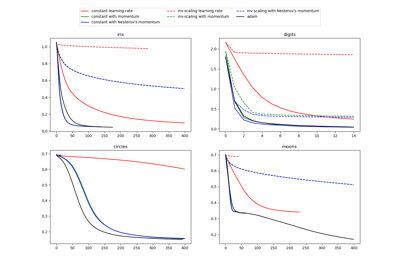
Сравнение стохастических стратегий обучения для MLPClassifier
