LabelSpreading#
- класс sklearn.semi_supervised.LabelSpreading(ядро='rbf', *, gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001, n_jobs=None)[источник]#
Модель LabelSpreading для полуконтролируемого обучения.
Эта модель похожа на базовый алгоритм распространения меток, но использует матрицу сходства, основанную на нормализованном графовом лапласиане, и мягкое закрепление по меткам.
Подробнее в Руководство пользователя.
- Параметры:
- ядро{'knn', 'rbf'} или вызываемый объект, по умолчанию='rbf'
Строковый идентификатор функции ядра для использования или сама функция ядра. Допустимыми входными строками являются только 'rbf' и 'knn'. Передаваемая функция должна принимать два входа, каждый формы (n_samples, n_features), и возвращать весовую матрицу формы (n_samples, n_samples).
- gammafloat, по умолчанию=20
Параметр для ядра rbf.
- n_neighborsint, default=7
Параметр для ядра knn, который является строго положительным целым числом.
- alphafloat, по умолчанию=0.2
Коэффициент зажима. Значение в (0, 1), которое указывает относительное количество информации, которое экземпляр должен принять от своих соседей, в отличие от начальной метки. alpha=0 означает сохранение начальной информации метки; alpha=1 означает замену всей начальной информации.
- max_iterint, по умолчанию=30
Максимальное количество итераций, разрешенное.
- tolfloat, по умолчанию=1e-3
Допуск сходимости: порог для рассмотрения системы в установившемся состоянии.
- n_jobsint, default=None
Количество параллельных задач для выполнения.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.
- Атрибуты:
- X_ndarray формы (n_samples, n_features)
Входной массив.
- classes_ndarray формы (n_classes,)
Различные метки, используемые при классификации экземпляров.
- label_distributions_ndarray формы (n_samples, n_classes)
Категориальное распределение для каждого элемента.
- transduction_ndarray формы (n_samples,)
Метка, присвоенная каждому элементу во время fit.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество выполненных итераций.
Смотрите также
LabelPropagationНерегуляризованное обучение с частичным привлечением учителя на основе графов.
Ссылки
Примеры
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import LabelSpreading >>> label_prop_model = LabelSpreading() >>> iris = datasets.load_iris() >>> rng = np.random.RandomState(42) >>> random_unlabeled_points = rng.rand(len(iris.target)) < 0.3 >>> labels = np.copy(iris.target) >>> labels[random_unlabeled_points] = -1 >>> label_prop_model.fit(iris.data, labels) LabelSpreading(...)
- fit(X, y)[источник]#
Обучение полуконтролируемой модели распространения меток на X.
Входные выборки (размеченные и неразмеченные) предоставляются матрицей X, а целевые метки — матрицей y. Мы обычно применяем метку -1 к неразмеченным выборкам в матрице y при полуконтролируемой классификации.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yarray-like формы (n_samples,)
Целевые значения классов с неразмеченными точками, отмеченными как -1. Все неразмеченные образцы будут транзитивно назначены метки внутри, которые хранятся в
transduction_.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Выполните индуктивный вывод по модели.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Матрица данных.
- Возвращает:
- yndarray формы (n_samples,)
Предсказания для входных данных.
- predict_proba(X)[источник]#
Предсказать вероятность для каждого возможного исхода.
Вычисляет оценки вероятностей для каждого отдельного образца в X и каждого возможного исхода, наблюдаемого во время обучения (категориальное распределение).
- Параметры:
- Xarray-like формы (n_samples, n_features)
Матрица данных.
- Возвращает:
- вероятностиndarray формы (n_samples, n_classes)
Нормализованные распределения вероятностей по меткам классов.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LabelSpreading[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
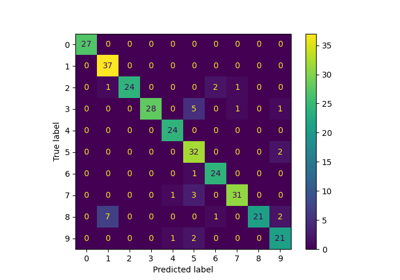
Распространение меток на цифрах: Демонстрация производительности

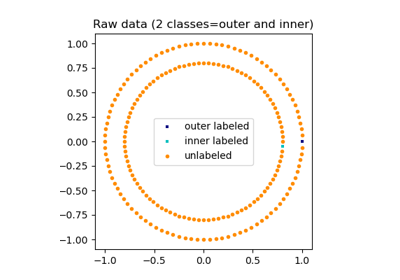
Распространение меток по кругам: Обучение сложной структуре
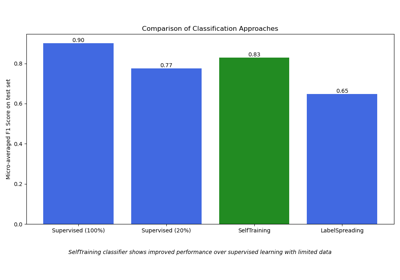
Полу-контролируемая классификация на текстовом наборе данных
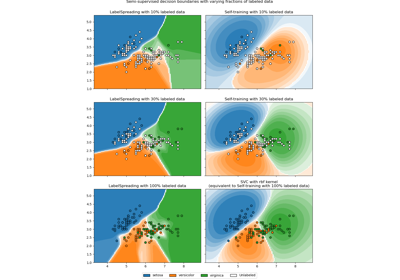
Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris