mutual_info_regression#
- sklearn.feature_selection.mutual_info_regression(X, y, *, discrete_features='auto', n_neighbors=3, copy=True, random_state=None, n_jobs=None)[источник]#
Оценить взаимную информацию для непрерывной целевой переменной.
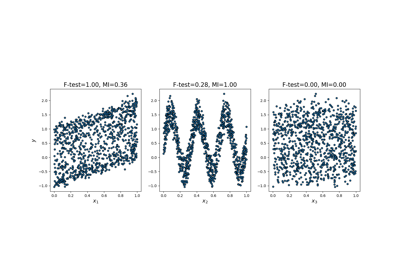
Взаимная информация (MI) [1] между двумя случайными величинами является неотрицательным значением, которое измеряет зависимость между переменными. Оно равно нулю тогда и только тогда, когда две случайные величины независимы, а более высокие значения означают большую зависимость.
Функция основана на непараметрических методах, базирующихся на оценке энтропии по расстояниям до k ближайших соседей, как описано в [2] и [3]. Оба метода основаны на идее, первоначально предложенной в [4].
Может использоваться для одномерного отбора признаков, подробнее в Руководство пользователя.
- Параметры:
- Xмассивоподобный или разреженная матрица, форма (n_samples, n_features)
Матрица признаков.
- yarray-like формы (n_samples,)
Вектор целевых значений.
- discrete_features{'auto', bool, array-like}, по умолчанию='auto'
Если bool, то определяет, считать ли все признаки дискретными или непрерывными. Если массив, то это должна быть либо булева маска формы (n_features,), либо массив с индексами дискретных признаков. Если 'auto', присваивается False для плотных
Xи в True для разреженныхX.- n_neighborsint, по умолчанию=3
Количество соседей для оценки взаимной информации для непрерывных переменных, см. [2] и [3]. Более высокие значения уменьшают дисперсию оценки, но могут внести смещение.
- copybool, по умолчанию=True
Создавать ли копию предоставленных данных. Если установлено значение False, исходные данные будут перезаписаны.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для добавления небольшого шума к непрерывным переменным с целью удаления повторяющихся значений. Передайте целое число для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.
- n_jobsint, default=None
Количество задач для вычисления взаимной информации. Параллелизация выполняется по столбцам
X.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.Добавлено в версии 1.5.
- Возвращает:
- mindarray, форма (n_features,)
Оцененная взаимная информация между каждым признаком и целью в натах.
Примечания
Термин «дискретные признаки» используется вместо названия «категориальные», потому что он точнее описывает сущность. Например, интенсивности пикселей изображения являются дискретными признаками (но едва ли категориальными), и вы получите лучшие результаты, если пометите их как таковые. Также обратите внимание, что обработка непрерывной переменной как дискретной и наоборот обычно даст некорректные результаты, поэтому будьте внимательны к этому.
Истинная взаимная информация не может быть отрицательной. Если её оценка оказывается отрицательной, она заменяется нулём.
Ссылки
[1]Mutual Information в Википедии.
[2] (1,2)А. Красков, Х. Штогбауэр и П. Грассбергер, «Оценка взаимной информации». Phys. Rev. E 69, 2004.
[3] (1,2)B. C. Ross "Mutual Information between Discrete and Continuous Data Sets". PLoS ONE 9(2), 2014.
[4]Л. Ф. Козаченко, Н. Н. Леоненко, "Выборочная оценка энтропии случайного вектора", Пробл. Передачи Инф., 23:2 (1987), 9-16
Примеры
>>> from sklearn.datasets import make_regression >>> from sklearn.feature_selection import mutual_info_regression >>> X, y = make_regression( ... n_samples=50, n_features=3, n_informative=1, noise=1e-4, random_state=42 ... ) >>> mutual_info_regression(X, y) array([0.117, 2.645, 0.0287])