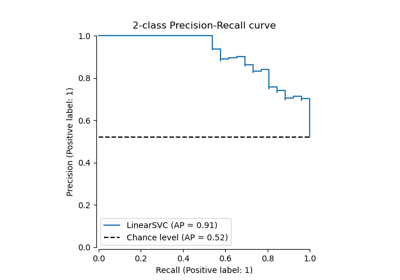
recall_score#
- sklearn.metrics.recall_score(y_true, y_pred, *, метки=None, pos_label=1, среднее='binary', sample_weight=None, zero_division='warn')[источник]#
Вычислить полноту (recall).
Полнота (recall) — это отношение
tp / (tp + fn)гдеtpэто количество истинно положительных иfnколичество ложноотрицательных результатов. Полнота (recall) интуитивно представляет собой способность классификатора найти все положительные образцы.Лучшее значение — 1, худшее — 0.
Поддержка за пределами бинарный целей достигается путем обработки многоклассовый и многометочный данные как набор бинарных задач, по одной для каждой метки. Для бинарный случае, установка
average='binary'будет возвращать полноту дляpos_label. Еслиaverageне является'binary',pos_labelигнорируется, и полнота для обоих классов вычисляется, затем усредняется или возвращается обе (когдаaverage=None). Аналогично, для многоклассовый и многометочный цели, полнота для всехlabelsлибо возвращаются, либо усредняются в зависимости отaverageпараметр. Используйтеlabelsуказать набор меток для расчета полноты.Подробнее в Руководство пользователя.
- Параметры:
- y_true1d array-like, или массив индикаторов меток / разреженная матрица
Истинные (правильные) целевые значения. Разреженная матрица поддерживается только когда цели имеют многометочный тип.
- y_pred1d array-like, или массив индикаторов меток / разреженная матрица
Оцененные цели, возвращаемые классификатором. Разреженная матрица поддерживается только когда цели имеют многометочный тип.
- меткиarray-like, default=None
Набор меток для включения, когда
average != 'binary', и их порядок, еслиaverage is None. Метки, присутствующие в данных, могут быть исключены, например, в многоклассовой классификации для исключения "отрицательного класса". Метки, отсутствующие в данных, могут быть включены и им будет "назначено" 0 образцов. Для многометочных целей метки являются индексами столбцов. По умолчанию все метки вy_trueиy_predиспользуются в отсортированном порядке.Изменено в версии 0.17: Параметр
labelsулучшена для многоклассовой задачи.- pos_labelint, float, bool или str, по умолчанию=1
Класс для отчета, если
average='binary'и данные являются бинарными, в противном случае этот параметр игнорируется. Для многоклассовых или многометочных целей, установитеlabels=[pos_label]иaverage != 'binary'для отчета метрик только для одной метки.- среднее{‘micro’, ‘macro’, ‘samples’, ‘weighted’, ‘binary’} или None, по умолчанию=’binary’
Этот параметр обязателен для многоклассовых/многометочных целей. Если
None, метрики для каждого класса возвращаются. В противном случае это определяет тип усреднения, выполняемого над данными:'binary':Отчитываться только о результатах для класса, указанного
pos_label. Это применимо только если цели (y_{true,pred}) являются бинарными.'micro':Рассчитать метрики глобально, подсчитывая общее количество истинно положительных, ложно отрицательных и ложноположительных.
'macro':Вычислить метрики для каждой метки и найти их невзвешенное среднее. Это не учитывает дисбаланс меток.
'weighted':Вычислите метрики для каждой метки и найдите их среднее значение, взвешенное по поддержке (количеству истинных экземпляров для каждой метки). Это изменяет 'макро' для учета дисбаланса меток; это может привести к F-оценке, которая не находится между точностью и полнотой. Взвешенная полнота равна точности.
'samples':Вычислить метрики для каждого экземпляра и найти их среднее (имеет смысл только для многоклассовой классификации, где это отличается от
accuracy_score).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- zero_division{"warn", 0.0, 1.0, np.nan}, по умолчанию="warn"
Устанавливает значение, возвращаемое при делении на ноль.
Примечания:
Если установлено в 'warn', это действует как 0, но также выдается предупреждение.
Если установлено в
np.nan, такие значения будут исключены из среднего.
Добавлено в версии 1.3:
np.nanопция была добавлена.
- Возвращает:
- полнотаfloat (если average не None) или массив float формы (n_unique_labels,)
Полнота положительного класса в бинарной классификации или взвешенное среднее полноты каждого класса для многоклассовой задачи.
Смотрите также
precision_recall_fscore_supportВычислить точность, полноту, F-меру и поддержку для каждого класса.
precision_scoreВычислить соотношение
tp / (tp + fp)гдеtpэто количество истинно положительных результатов иfpколичество ложных срабатываний.balanced_accuracy_scoreВычислить сбалансированную точность для работы с несбалансированными наборами данных.
multilabel_confusion_matrixВычислить матрицу ошибок для каждого класса или образца.
PrecisionRecallDisplay.from_estimatorПостроить кривую точности-полноты для данного оценщика и некоторых данных.
PrecisionRecallDisplay.from_predictionsПостроение кривой precision-recall для бинарных предсказаний классов.
Примечания
Когда
true positive + false negative == 0, recall возвращает 0 и вызываетUndefinedMetricWarning. Это поведение можно изменить с помощьюzero_division.Примеры
>>> import numpy as np >>> from sklearn.metrics import recall_score >>> y_true = [0, 1, 2, 0, 1, 2] >>> y_pred = [0, 2, 1, 0, 0, 1] >>> recall_score(y_true, y_pred, average='macro') 0.33 >>> recall_score(y_true, y_pred, average='micro') 0.33 >>> recall_score(y_true, y_pred, average='weighted') 0.33 >>> recall_score(y_true, y_pred, average=None) array([1., 0., 0.]) >>> y_true = [0, 0, 0, 0, 0, 0] >>> recall_score(y_true, y_pred, average=None) array([0.5, 0. , 0. ]) >>> recall_score(y_true, y_pred, average=None, zero_division=1) array([0.5, 1. , 1. ]) >>> recall_score(y_true, y_pred, average=None, zero_division=np.nan) array([0.5, nan, nan])
>>> # multilabel classification >>> y_true = [[0, 0, 0], [1, 1, 1], [0, 1, 1]] >>> y_pred = [[0, 0, 0], [1, 1, 1], [1, 1, 0]] >>> recall_score(y_true, y_pred, average=None) array([1. , 1. , 0.5])
Примеры галереи#
Последующая настройка порога принятия решений для обучения с учетом стоимости