NMF#
- класс sklearn.decomposition.NMF(n_components='auto', *, init=None, solver='cd', beta_loss='frobenius', tol=0.0001, max_iter=200, random_state=None, alpha_W=0.0, alpha_H='same', l1_ratio=0.0, verbose=0, перемешивание=False)[источник]#
Неотрицательная матричная факторизация (NMF).
Найти две неотрицательные матрицы, т.е. матрицы со всеми неотрицательными элементами, (W, H), произведение которых аппроксимирует неотрицательную матрицу X. Эта факторизация может использоваться, например, для уменьшения размерности, разделения источников или извлечения тем.
Целевая функция:
\[ \begin{align}\begin{aligned}L(W, H) &= 0.5 * ||X - WH||_{loss}^2\\ &+ alpha\_W * l1\_ratio * n\_features * ||vec(W)||_1\\ &+ alpha\_H * l1\_ratio * n\_samples * ||vec(H)||_1\\ &+ 0.5 * alpha\_W * (1 - l1\_ratio) * n\_features * ||W||_{Fro}^2\\ &+ 0.5 * alpha\_H * (1 - l1\_ratio) * n\_samples * ||H||_{Fro}^2,\end{aligned}\end{align} \]где \(||A||_{Fro}^2 = \sum_{i,j} A_{ij}^2\) (норма Фробениуса) и \(||vec(A)||_1 = \sum_{i,j} abs(A_{ij})\) (Поэлементная L1 норма).
Общая норма \(||X - WH||_{loss}\) может представлять норму Фробениуса или другую поддерживаемую бета-дивергенцию. Выбор между вариантами контролируется параметром
beta_lossпараметр.Регуляризационные члены масштабируются на
n_featuresдляWи с помощьюn_samplesдляHчтобы сбалансировать их влияние друг относительно друга и относительно члена соответствия данным как можно более независимо от размераn_samplesобучающей выборки.Целевая функция минимизируется с помощью чередующейся минимизации W и H.
Обратите внимание, что преобразованные данные называются W, а матрица компонентов называется H. В литературе по NMF соглашение об именовании обычно обратное, поскольку матрица данных X транспонирована.
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint или {‘auto’} или None, по умолчанию=’auto’
менее 30 или около того),
None, все признаки сохраняются. Еслиn_components='auto', количество компонентов автоматически выводится из форм W или H.Изменено в версии 1.4: Добавлен
'auto'значение.Изменено в версии 1.6: Значение по умолчанию изменено с
Noneto'auto'.- init{‘random’, ‘nndsvd’, ‘nndsvda’, ‘nndsvdar’, ‘custom’}, по умолчанию=None
Метод, используемый для инициализации процедуры. Допустимые варианты:
None: 'nndsvda', если n_components <= min(n_samples, n_features), иначе случайная инициализация.'random': неотрицательные случайные матрицы, масштабированные с:sqrt(X.mean() / n_components)'nndsvd': Инициализация неотрицательного двойного сингулярного разложения (NNDSVD) (лучше для разреженности)'nndsvda': NNDSVD с нулями, заполненными средним значением X (лучше, когда разреженность нежелательна)'nndsvdar'NNDSVD с нулями, заполненными малыми случайными значениями (обычно более быстрая, менее точная альтернатива NNDSVDa для случаев, когда разреженность нежелательна)'custom': Использовать пользовательские матрицыWиHкоторые должны быть предоставлены оба.
Изменено в версии 1.1: Когда
init=Noneи n_components меньше n_samples и n_features по умолчанию равноnndsvdaвместоnndsvd.- solver{'cd', 'mu'}, по умолчанию='cd'
Численный решатель для использования:
'cd' — это решатель координатного спуска.
‘mu’ — решатель мультипликативного обновления.
Добавлено в версии 0.17: Решатель Coordinate Descent.
Добавлено в версии 0.19: решатель Multiplicative Update.
- beta_lossfloat или {'frobenius', 'kullback-leibler', 'itakura-saito'}, по умолчанию='frobenius'
Бета-дивергенция для минимизации, измеряющая расстояние между X и произведением WH. Заметим, что значения, отличные от 'frobenius' (или 2) и 'kullback-leibler' (или 1), приводят к значительно более медленной подгонке. Заметим, что при beta_loss <= 0 (или 'itakura-saito') входная матрица X не может содержать нули. Используется только в решателе 'mu'.
Добавлено в версии 0.19.
- tolfloat, по умолчанию=1e-4
Допуск условия остановки.
- max_iterint, default=200
Максимальное количество итераций до таймаута.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Используется для инициализации (когда
init== 'nndsvdar' или 'random'), и в методе координатного спуска. Передайте целое число для воспроизводимых результатов при многократных вызовах функции. См. Глоссарий.- alpha_Wfloat, по умолчанию=0.0
Константа, умножающая члены регуляризации
W. Установите значение ноль (по умолчанию), чтобы не было регуляризации наW.Добавлено в версии 1.0.
- alpha_Hfloat или "same", по умолчанию="same"
Константа, умножающая члены регуляризации
H. Установите его в ноль, чтобы не иметь регуляризации наH. Если "same" (по умолчанию), принимает то же значение, что иalpha_W.Добавлено в версии 1.0.
- l1_ratiofloat, по умолчанию=0.0
Параметр смешивания регуляризации, где 0 <= l1_ratio <= 1. Для l1_ratio = 0 штраф является поэлементным L2-штрафом (также известным как норма Фробениуса). Для l1_ratio = 1 это поэлементный L1-штраф. Для 0 < l1_ratio < 1 штраф представляет собой комбинацию L1 и L2.
Добавлено в версии 0.17: Параметр регуляризации l1_ratio используется в решателе Coordinate Descent.
- verboseint, по умолчанию=0
Быть ли подробным.
- перемешиваниеbool, по умолчанию=False
Если истинно, рандомизировать порядок координат в решателе CD.
Добавлено в версии 0.17: перемешивание параметр, используемый в решателе Coordinate Descent.
- Атрибуты:
- components_ndarray формы (n_components, n_features)
Матрица факторизации, иногда называемая 'словарем'.
- n_components_int
Количество компонентов. Оно совпадает с
n_componentsпараметр если он был задан. В противном случае он будет таким же, как количество признаков.- reconstruction_err_float
Норма Фробениуса разности матриц или бета-дивергенция между обучающими данными
Xи восстановленные данныеWHиз обученной модели.- n_iter_int
Фактическое количество итераций.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
DictionaryLearningНайти словарь, который разреженно кодирует данные.
MiniBatchSparsePCAМини-пакетный разреженный анализ главных компонент.
PCAМетод главных компонент.
SparseCoderНайти разреженное представление данных из фиксированного, предварительно вычисленного словаря.
SparsePCAРазреженный анализ главных компонент.
TruncatedSVDУменьшение размерности с использованием усеченного SVD.
Ссылки
[1]“Fast local algorithms for large scale nonnegative matrix and tensor factorizations” Cichocki, Andrzej, and P. H. A. N. Anh-Huy. IEICE transactions on fundamentals of electronics, communications and computer sciences 92.3: 708-721, 2009.
[2]“Алгоритмы для неотрицательного матричного разложения с бета-дивергенцией” Fevotte, C., & Idier, J. (2011). Neural Computation, 23(9).
Примеры
>>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]]) >>> from sklearn.decomposition import NMF >>> model = NMF(n_components=2, init='random', random_state=0) >>> W = model.fit_transform(X) >>> H = model.components_
- fit(X, y=None, **params)[источник]#
Изучите модель NMF для данных X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **paramskwargs
Параметры (именованные аргументы) и значения, передаваемые экземпляру fit_transform.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None, W=None, H=None)[источник]#
Обучить модель NMF для данных X и вернуть преобразованные данные.
Это более эффективно, чем вызов fit с последующим transform.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Warray-like формы (n_samples, n_components), default=None
Если
init='custom', он используется как начальное предположение для решения. ЕслиNone, использует метод инициализации, указанный вinit.- Harray-like формы (n_components, n_features), по умолчанию=None
Если
init='custom', он используется как начальное предположение для решения. ЕслиNone, использует метод инициализации, указанный вinit.
- Возвращает:
- Wndarray формы (n_samples, n_components)
Преобразованные данные.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Преобразование данных обратно в исходное пространство.
Добавлено в версии 0.18.
- Параметры:
- X{ndarray, sparse matrix} формы (n_samples, n_components)
Преобразованная матрица данных.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Возвращает матрицу данных исходной формы.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразует данные X в соответствии с обученной моделью NMF.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.
- Возвращает:
- Wndarray формы (n_samples, n_components)
Преобразованные данные.
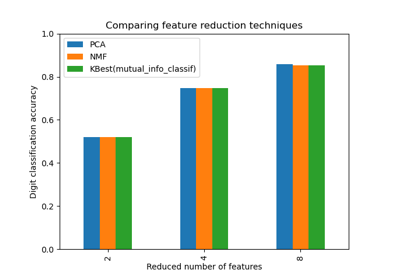
Примеры галереи#
Выбор уменьшения размерности с помощью Pipeline и GridSearchCV
