AffinityPropagation#
- класс sklearn.cluster.AffinityPropagation(*, damping=0.5, max_iter=200, convergence_iter=15, copy=True, предпочтение=None, affinity='euclidean', verbose=False, random_state=None)[источник]#
Выполнить кластеризацию данных методом распространения близости.
Подробнее в Руководство пользователя.
- Параметры:
- dampingfloat, по умолчанию=0.5
Коэффициент демпфирования в диапазоне
[0.5, 1.0)это степень, в которой текущее значение сохраняется относительно входящих значений (взвешенных 1 - damping). Это необходимо для избежания числовых колебаний при обновлении этих значений (сообщений).- max_iterint, default=200
Максимальное количество итераций.
- convergence_iterint, default=15
Количество итераций без изменения числа оцененных кластеров, которое останавливает сходимость.
- copybool, по умолчанию=True
Создать копию входных данных.
- предпочтениеarray-like формы (n_samples,) или float, по умолчанию=None
Предпочтения для каждой точки - точки с большими значениями предпочтений с большей вероятностью будут выбраны в качестве примеров. Количество примеров, т.е. кластеров, зависит от значения входных предпочтений. Если предпочтения не переданы в качестве аргументов, они будут установлены в медиану входных сходств.
- affinity{‘euclidean’, ‘precomputed’}, по умолчанию ‘euclidean’
Какую близость использовать. В настоящее время 'precomputed' и
euclideanподдерживаются. 'euclidean' использует отрицательное квадратичное евклидово расстояние между точками.- verbosebool, по умолчанию=False
Быть ли подробным.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Псевдослучайный генератор чисел для управления начальным состоянием. Используйте целое число для воспроизводимых результатов между вызовами функций. См. Глоссарий.
Добавлено в версии 0.23: этот параметр ранее был жестко задан как 0.
- Атрибуты:
- cluster_centers_indices_ndarray формы (n_clusters,)
Индексы центров кластеров.
- cluster_centers_ndarray формы (n_clusters, n_features)
Центры кластеров (если affinity !=
precomputed).- labels_ndarray формы (n_samples,)
Метки каждой точки.
- affinity_matrix_ndarray формы (n_samples, n_samples)
Хранит матрицу сходства, используемую в
fit.- n_iter_int
Количество итераций, затраченных на сходимость.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
AgglomerativeClusteringРекурсивно объединяет пару кластеров, которая минимально увеличивает заданное расстояние связи.
FeatureAgglomerationПохоже на AgglomerativeClustering, но рекурсивно объединяет признаки вместо образцов.
KMeansКластеризация K-Means.
MiniBatchKMeansКластеризация Mini-Batch K-Means.
MeanShiftКластеризация методом сдвига среднего с использованием плоского ядра.
SpectralClusteringПрименить кластеризацию к проекции нормализованного лапласиана.
Примечания
Алгоритмическая сложность распространения аффинности квадратична относительно количества точек.
Когда алгоритм не сходится, он все равно возвращает массив
cluster_center_indicesи метки, если есть какие-либо экземпляры/кластеры, однако они могут быть вырожденными и должны использоваться с осторожностью.Когда
fitне сходится,cluster_centers_все еще заполнен, однако он может быть вырожденным. В таком случае действуйте с осторожностью. Еслиfitне сходится и не производит никакихcluster_centers_затемpredictпомечает каждую выборку как-1.Когда все обучающие образцы имеют одинаковые сходства и одинаковые предпочтения, назначение центров кластеров и меток зависит от предпочтения. Если предпочтение меньше, чем сходства,
fitприведет к одному центру кластера и метке0для каждого образца. В противном случае каждый обучающий образец становится своим собственным центром кластера и получает уникальную метку.Ссылки
Brendan J. Frey и Delbert Dueck, “Clustering by Passing Messages Between Data Points”, Science Feb. 2007
Примеры
>>> from sklearn.cluster import AffinityPropagation >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [4, 2], [4, 4], [4, 0]]) >>> clustering = AffinityPropagation(random_state=5).fit(X) >>> clustering AffinityPropagation(random_state=5) >>> clustering.labels_ array([0, 0, 0, 1, 1, 1]) >>> clustering.predict([[0, 0], [4, 4]]) array([0, 1]) >>> clustering.cluster_centers_ array([[1, 2], [4, 2]])
Пример использования см. в Демонстрация алгоритма кластеризации с распространением аффинности.
For a comparison of Affinity Propagation with other clustering algorithms, see Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
- fit(X, y=None)[источник]#
Обучите кластеризацию на основе признаков или матрицы сходства.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features), или array-like формы (n_samples, n_samples)
Обучающие экземпляры для кластеризации, или сходства/аффинности между экземплярами, если
affinity='precomputed'. Если предоставлена разреженная матрица признаков, она будет преобразована в разреженнуюcsr_matrix.- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- self
Возвращает сам экземпляр.
- fit_predict(X, y=None)[источник]#
Обучить кластеризацию на основе матрицы признаков/сходства; вернуть метки кластеров.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features), или array-like формы (n_samples, n_samples)
Обучающие экземпляры для кластеризации, или сходства/аффинности между экземплярами, если
affinity='precomputed'. Если предоставлена разреженная матрица признаков, она будет преобразована в разреженнуюcsr_matrix.- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- меткиndarray формы (n_samples,)
Метки кластеров.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказывает ближайший кластер, к которому принадлежит каждый образец в X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные для предсказания. Если предоставлена разреженная матрица, она будет преобразована в разреженную
csr_matrix.
- Возвращает:
- меткиndarray формы (n_samples,)
Метки кластеров.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
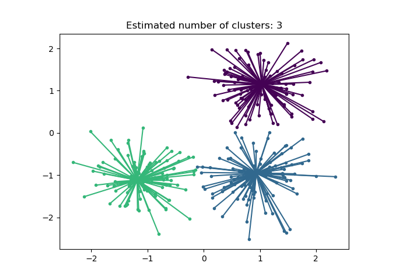
Демонстрация алгоритма кластеризации с распространением аффинности
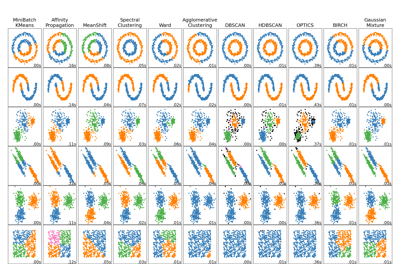
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных