BaggingRegressor#
- класс sklearn.ensemble.BaggingRegressor(estimator=None, n_estimators=10, *, max_samples=None, max_features=1.0, bootstrap=True, bootstrap_features=False, oob_score=False, warm_start=False, n_jobs=None, random_state=None, verbose=0)[источник]#
Бэггинг-регрессор.
Бэггинг-регрессор — это мета-оценщик ансамбля, который обучает базовые регрессоры на случайных подмножествах исходного набора данных, а затем агрегирует их индивидуальные прогнозы (либо голосованием, либо усреднением) для формирования окончательного прогноза. Такой мета-оценщик обычно может использоваться как способ уменьшения дисперсии оценщика черного ящика (например, дерева решений), путем введения рандомизации в процедуру его построения и затем создания ансамбля из него.
Этот алгоритм включает несколько работ из литературы. Когда случайные подмножества набора данных выбираются как случайные подмножества выборок, то этот алгоритм известен как Pasting [1]. Если образцы извлекаются с возвращением, то метод известен как Bagging [2]. Когда случайные подмножества набора данных выбираются как случайные подмножества признаков, то метод известен как Random Subspaces [3]. Наконец, когда базовые оценки строятся на подмножествах как выборок, так и признаков, метод известен как Random Patches [4].
Подробнее в Руководство пользователя.
Добавлено в версии 0.15.
- Параметры:
- estimatorobject, default=None
Базовый оценщик для обучения на случайных подмножествах набора данных. Если None, то базовый оценщик — это
DecisionTreeRegressor.Добавлено в версии 1.2:
base_estimatorбыл переименован вestimator.- n_estimatorsint, по умолчанию=10
Количество базовых оценщиков в ансамбле.
- max_samplesint или float, по умолчанию=None
Количество образцов для выборки из X для обучения каждого базового оценщика (с заменой по умолчанию, см.
bootstrapдля получения дополнительных деталей).Если None, то нарисовать
X.shape[0]образцов независимо отsample_weight.Если int, то нарисовать
max_samplesвыборки.Если float, то нарисовать
max_samples * X.shape[0]невзвешенные выборки илиmax_samples * sample_weight.sum()взвешенные образцы.
- max_featuresint или float, по умолчанию=1.0
Количество признаков, извлекаемых из X для обучения каждого базового оценщика ( по умолчанию без замены, см.
bootstrap_featuresдля получения дополнительных деталей).Если int, то нарисовать
max_featuresпризнаков.Если float, то нарисовать
max(1, int(max_features * n_features_in_))признаков.
- bootstrapbool, по умолчанию=True
Выбираются ли образцы с возвращением. Если False, выполняется выборка без возвращения. Если обучение с
sample_weight, настоятельно рекомендуется выбрать True, так как только выбор с возвращением обеспечит ожидаемую частотную семантикуsample_weight.- bootstrap_featuresbool, по умолчанию=False
Признаки выбираются с возвращением.
- oob_scorebool, по умолчанию=False
Использовать ли внепакетные выборки для оценки ошибки обобщения. Доступно только если bootstrap=True.
- warm_startbool, по умолчанию=False
При установке в True повторно использует решение предыдущего вызова fit и добавляет больше оценщиков в ансамбль, в противном случае просто обучает новый ансамбль. См. Глоссарий.
- n_jobsint, default=None
Количество заданий для параллельного выполнения как для
fitиpredict.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Управляет случайным повторным выбором исходного набора данных (по образцам и по признакам). Если базовый оценщик принимает
random_stateатрибут, для каждого экземпляра в ансамбле генерируется разное начальное значение. Передайте целое число для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.- verboseint, по умолчанию=0
Управляет подробностью вывода при обучении и предсказании.
- Атрибуты:
- estimator_estimator
Базовый оценщик, из которого строится ансамбль.
Добавлено в версии 1.2:
base_estimator_был переименован вestimator_.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- estimators_список оценщиков
Коллекция обученных суб-оценщиков.
estimators_samples_список массивовПодмножество выбранных выборок для каждого базового оценщика.
- estimators_features_список массивов
Подмножество выбранных признаков для каждого базового оценщика.
- oob_score_float
Оценка обучающего набора данных, полученная с использованием out-of-bag оценки. Этот атрибут существует только когда
oob_scoreравно True.- oob_prediction_ndarray формы (n_samples,)
Предсказание, вычисленное с использованием оценки out-of-bag на обучающем наборе. Если n_estimators мало, возможно, что точка данных никогда не исключалась во время бутстрапа. В этом случае,
oob_prediction_может содержать NaN. Этот атрибут существует только когдаoob_scoreравно True.
Смотрите также
BaggingClassifierКлассификатор Bagging.
Ссылки
[1]L. Breiman, “Pasting small votes for classification in large databases and on-line”, Machine Learning, 36(1), 85-103, 1999.
[2]L. Breiman, "Bagging predictors", Machine Learning, 24(2), 123-140, 1996.
[3]T. Ho, “The random subspace method for constructing decision forests”, Pattern Analysis and Machine Intelligence, 20(8), 832-844, 1998.
[4]G. Louppe и P. Geurts, «Ансамбли на случайных патчах», Machine Learning and Knowledge Discovery in Databases, 346-361, 2012.
Примеры
>>> from sklearn.svm import SVR >>> from sklearn.ensemble import BaggingRegressor >>> from sklearn.datasets import make_regression >>> X, y = make_regression(n_samples=100, n_features=4, ... n_informative=2, n_targets=1, ... random_state=0, shuffle=False) >>> regr = BaggingRegressor(estimator=SVR(), ... n_estimators=10, random_state=0).fit(X, y) >>> regr.predict([[0, 0, 0, 0]]) array([-2.8720])
- fit(X, y, sample_weight=None, **fit_params)[источник]#
Постройте ансамбль Bagging оценщиков из обучающего набора (X, y).
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие входные выборки. Разреженные матрицы принимаются только если они поддерживаются базовым оценщиком.
- yarray-like формы (n_samples,)
Целевые значения (метки классов в классификации, вещественные числа в регрессии).
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок. Если None, то выборки взвешены одинаково. Используются как вероятности для выборки обучающего набора. Обратите внимание, что ожидаемая частотная семантика для
sample_weightпараметр выполняются только при выборке с возвращениемbootstrap=Trueи использование float или integermax_samples(вместо значения по умолчаниюmax_samples=None).- **fit_paramsdict
Параметры для передачи базовым оценщикам.
Добавлено в версии 1.5: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.5.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X, **params)[источник]#
Предсказать регрессионную цель для X.
Предсказанное целевое значение регрессии для входного образца вычисляется как среднее предсказанных целевых значений регрессии оценщиков в ансамбле.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие входные выборки. Разреженные матрицы принимаются только если они поддерживаются базовым оценщиком.
- **paramsdict
Параметры, перенаправленные в
predictметод под-оценщиков через API маршрутизации метаданных.Добавлено в версии 1.7: Доступно только если
sklearn.set_config(enable_metadata_routing=True)установлено. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- yndarray формы (n_samples,)
Предсказанные значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BaggingRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') BaggingRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
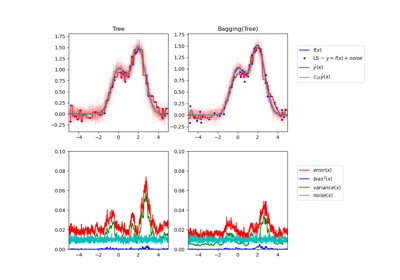
Один оценщик против бэггинга: декомпозиция смещения-дисперсии