SelfTrainingClassifier#
- класс sklearn.semi_supervised.SelfTrainingClassifier(estimator=None, порог=0.75, критерий='threshold', k_best=10, max_iter=10, verbose=False)[источник]#
Классификатор с самообучением.
Это метаоценщик позволяет заданному контролируемому классификатору функционировать как полуконтролируемый классификатор, позволяя ему обучаться на немаркированных данных. Это достигается путем итеративного предсказания псевдометок для немаркированных данных и добавления их в обучающий набор.
Классификатор будет продолжать итерации до тех пор, пока не будет достигнут max_iter, или псевдометки не добавлялись в обучающую выборку на предыдущей итерации.
Подробнее в Руководство пользователя.
- Параметры:
- estimatorобъект оценщика
Объект оценщика, реализующий
fitиpredict_proba. Вызовfitметод обучит клон переданного оценщика, который будет сохранен вestimator_атрибут.Добавлено в версии 1.6:
estimatorбыл добавлен для заменыbase_estimator.- порогfloat, default=0.75
Порог принятия решения для использования с
criterion='threshold'. Должно быть в [0, 1). При использовании'threshold'criterion, a хорошо откалиброванный классификатор должен использоваться.- критерий{'threshold', 'k_best'}, по умолчанию='threshold'
Критерий выбора, используемый для определения, какие метки добавлять в обучающий набор. Если
'threshold', псевдо-метки с вероятностями предсказания вышеthresholdдобавляются в набор данных. Если'k_best',k_bestпсевдо-метки с наивысшими вероятностями предсказания добавляются в набор данных. При использовании критерия 'threshold', хорошо откалиброванный классификатор должен использоваться.- k_bestint, по умолчанию=10
Количество образцов для добавления на каждой итерации. Используется только при
criterion='k_best'.- max_iterint или None, по умолчанию=10
Максимальное количество итераций, разрешенное. Должно быть больше или равно 0. Если оно
None, классификатор будет продолжать предсказывать метки, пока не будут добавлены новые псевдометки или пока все неразмеченные образцы не будут размечены.- verbosebool, по умолчанию=False
Включить подробный вывод.
- Атрибуты:
- estimator_объект оценщика
Обученный оценщик.
- classes_ndarray или список ndarray формы (n_classes,)
Метки классов для каждого выхода. (Взяты из обученного
estimator_).- transduction_ndarray формы (n_samples,)
Метки, используемые для окончательной подгонки классификатора, включая псевдометки, добавленные во время подгонки.
- labeled_iter_ndarray формы (n_samples,)
Итерация, в которой была помечена каждая выборка. Если у выборки итерация 0, то выборка уже была помечена в исходном наборе данных. Если у выборки итерация -1, то выборка не была помечена ни в одной итерации.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество раундов самообучения, то есть количество раз, когда базовый оценщик обучается на перемаркированных вариантах обучающей выборки.
- termination_condition_{'max_iter', 'no_change', 'all_labeled'}
Причина, по которой обучение было остановлено.
'max_iter':n_iter_достигнутоmax_iter.'no_change': новые метки не были предсказаны.'all_labeled': все непомеченные образцы были помечены доmax_iterбыл достигнут.
Смотрите также
LabelPropagationКлассификатор распространения меток.
LabelSpreadingМодель распространения меток для полуконтролируемого обучения.
Ссылки
Примеры
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import SelfTrainingClassifier >>> from sklearn.svm import SVC >>> rng = np.random.RandomState(42) >>> iris = datasets.load_iris() >>> random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3 >>> iris.target[random_unlabeled_points] = -1 >>> svc = SVC(probability=True, gamma="auto") >>> self_training_model = SelfTrainingClassifier(svc) >>> self_training_model.fit(iris.data, iris.target) SelfTrainingClassifier(...)
- decision_function(X, **params)[источник]#
Вызов функции принятия решений для
estimator.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Массив, представляющий данные.
- **paramsdict of str -> object
Параметры для передачи в базовый оценщик
decision_functionметод.Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- yndarray формы (n_samples, n_features)
Результат функции принятия решения
estimator.
- fit(X, y, **params)[источник]#
Обучить классификатор самообучения с использованием
X,yв качестве обучающих данных.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Массив, представляющий данные.
- y{array-like, sparse matrix} формы (n_samples,)
Массив, представляющий метки. Неразмеченные образцы должны иметь метку -1.
- **paramsdict
Параметры для передачи базовым оценщикам.
Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- selfobject
Обученный оценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.6.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X, **params)[источник]#
Предсказать классы
X.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Массив, представляющий данные.
- **paramsdict of str -> object
Параметры для передачи в базовый оценщик
predictметод.Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- yndarray формы (n_samples,)
Массив с предсказанными метками.
- predict_log_proba(X, **params)[источник]#
Предсказать логарифмическую вероятность для каждого возможного исхода.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Массив, представляющий данные.
- **paramsdict of str -> object
Параметры для передачи в базовый оценщик
predict_log_probaметод.Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- yndarray формы (n_samples, n_features)
Массив с логарифмическими вероятностями предсказания.
- predict_proba(X, **params)[источник]#
Предсказать вероятность для каждого возможного исхода.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Массив, представляющий данные.
- **paramsdict of str -> object
Параметры для передачи в базовый оценщик
predict_probaметод.Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- yndarray формы (n_samples, n_features)
Массив с вероятностями предсказаний.
- score(X, y, **params)[источник]#
Вызовите score на
estimator.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Массив, представляющий данные.
- yarray-like формы (n_samples,)
Массив, представляющий метки.
- **paramsdict of str -> object
Параметры для передачи в базовый оценщик
scoreметод.Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- scorefloat
Результат вызова score на
estimator.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
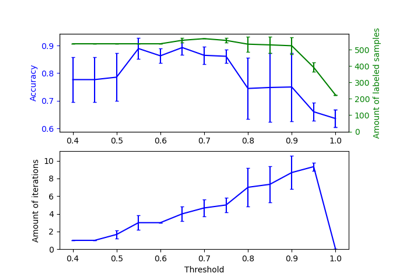
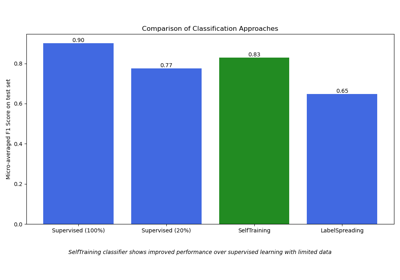
Полу-контролируемая классификация на текстовом наборе данных
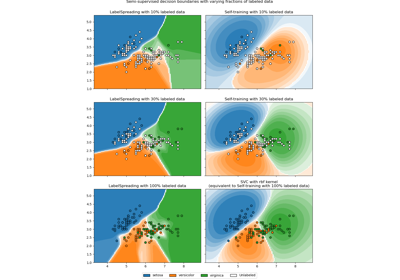
Граница решения полуконтролируемых классификаторов против SVM на наборе данных Iris