SequentialFeatureSelector#
- класс sklearn.feature_selection.SequentialFeatureSelector(estimator, *, n_features_to_select='auto', tol=None, направление='forward', оценка=None, cv=5, n_jobs=None)[источник]#
Преобразователь, выполняющий последовательный отбор признаков.
Этот последовательный селектор признаков добавляет (прямой отбор) или удаляет (обратный отбор) признаки для формирования подмножества признаков жадным образом. На каждом этапе этот оценщик выбирает лучший признак для добавления или удаления на основе кросс-валидационной оценки оценщика. В случае обучения без учителя, этот последовательный селектор признаков рассматривает только признаки (X), а не желаемые выходы (y).
Подробнее в Руководство пользователя.
Добавлено в версии 0.24.
- Параметры:
- estimatorэкземпляр estimator
Необученный оценщик.
- n_features_to_select“auto”, int или float, по умолчанию=”auto”
Если
"auto"поведение зависит отtolпараметр:if
tolне являетсяNone, затем признаки выбираются, пока изменение оценки не превыситtol.в противном случае выбирается половина признаков.
Если целое число, параметр является абсолютным количеством признаков для выбора. Если число с плавающей точкой между 0 и 1, это доля признаков для выбора.
Добавлено в версии 1.1: Опция
"auto"был добавлен в версии 1.1.Изменено в версии 1.3: Значение по умолчанию изменено с
"warn"to"auto"в 1.3.- tolfloat, по умолчанию=None
Если оценка не увеличивается как минимум на
tolмежду двумя последовательными добавлениями или удалениями признаков, прекратите добавлять или удалять.tolможет быть отрицательным при удалении признаков с помощьюdirection="backward".tolis required to be strictly positive when doing forward selection. It can be useful to reduce the number of features at the cost of a small decrease in the score.tolактивируется только тогда, когдаn_features_to_selectявляется"auto".Добавлено в версии 1.1.
- направление{'forward', 'backward'}, по умолчанию='forward'
Выполнять ли прямой выбор или обратный выбор.
- оценкаstr или callable, по умолчанию=None
Метод оценки для использования в перекрестной проверке. Варианты:
str: см. Строковые имена скореров для опций.
callable: вызываемый объект scorer (например, функция) с сигнатурой
scorer(estimator, X, y)который возвращает одно значение. См. Вызываемые скореры подробности.None:estimator’s критерий оценки по умолчанию используется.
- cvint, генератор кросс-валидации или итерируемый объект, по умолчанию=None
Определяет стратегию разделения для перекрестной проверки. Возможные значения для cv:
None, чтобы использовать стандартную 5-кратную перекрестную проверку,
целое число, чтобы указать количество фолдов в
(Stratified)KFold,Итерируемый объект, возвращающий (обучающие, тестовые) разбиения в виде массивов индексов.
Для целочисленных/None входных данных, если оценщик является классификатором и
yявляется либо бинарным, либо многоклассовым,StratifiedKFoldиспользуется. Во всех остальных случаях,KFoldиспользуется. Эти разделители создаются с помощьюshuffle=Falseтак что разделения будут одинаковыми при всех вызовах.Обратитесь Руководство пользователя для различных стратегий перекрестной проверки, которые можно использовать здесь.
- n_jobsint, default=None
Количество задач для параллельного выполнения. При оценке нового признака для добавления или удаления процедура кросс-валидации параллельна по фолдам.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.
- Атрибуты:
- n_features_in_int
Количество признаков, замеченных во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_features_to_select_int
Количество признаков, которые были выбраны.
- support_ndarray формы (n_features,), dtype=bool
Маска выбранных признаков.
Смотрите также
GenericUnivariateSelectОдномерный селектор признаков с настраиваемой стратегией.
RFEРекурсивное исключение признаков на основе весов важности.
RFECVРекурсивное исключение признаков на основе весов важности с автоматическим выбором количества признаков.
SelectFromModelОтбор признаков на основе пороговых значений весов важности.
Примеры
>>> from sklearn.feature_selection import SequentialFeatureSelector >>> from sklearn.neighbors import KNeighborsClassifier >>> from sklearn.datasets import load_iris >>> X, y = load_iris(return_X_y=True) >>> knn = KNeighborsClassifier(n_neighbors=3) >>> sfs = SequentialFeatureSelector(knn, n_features_to_select=3) >>> sfs.fit(X, y) SequentialFeatureSelector(estimator=KNeighborsClassifier(n_neighbors=3), n_features_to_select=3) >>> sfs.get_support() array([ True, False, True, True]) >>> sfs.transform(X).shape (150, 3)
- fit(X, y=None, **params)[источник]#
Изучите признаки для выбора из X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество предикторов.- yarray-like формы (n_samples,), по умолчанию=None
Целевые значения. Этот параметр может игнорироваться для обучения без учителя.
- **paramsdict, по умолчанию=None
Параметры, передаваемые в базовый
estimator,cvиscorerобъекты.Добавлено в версии 1.6: Доступно только если
enable_metadata_routing=True, который можно установить с помощьюsklearn.set_config(enable_metadata_routing=True). См. Руководство по маршрутизации метаданных для более подробной информации.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Маскировать имена признаков в соответствии с выбранными признаками.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.6.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- get_support(индексы=False)[источник]#
Получить маску или целочисленный индекс выбранных признаков.
- Параметры:
- индексыbool, по умолчанию=False
Если True, возвращаемое значение будет массивом целых чисел, а не булевой маской.
- Возвращает:
- поддержкамассив
Индекс, который выбирает сохраняемые признаки из вектора признаков. Если
indicesравно False, это булев массив формы [# входных признаков], в котором элемент равен True, если соответствующий признак выбран для сохранения. Еслиindicesесли True, это целочисленный массив формы [# выходных признаков], значения которого являются индексами входного вектора признаков.
- inverse_transform(X)[источник]#
Обратить операцию преобразования.
- Параметры:
- Xмассив формы [n_samples, n_selected_features]
Входные образцы.
- Возвращает:
- X_originalмассив формы [n_samples, n_original_features]
Xсо столбцами нулей, вставленными там, где признаки были бы удалены с помощьюtransform.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Уменьшить X до выбранных признаков.
- Параметры:
- Xмассив формы [n_samples, n_features]
Входные образцы.
- Возвращает:
- X_rмассив формы [n_samples, n_selected_features]
Входные выборки только с выбранными признаками.
Примеры галереи#
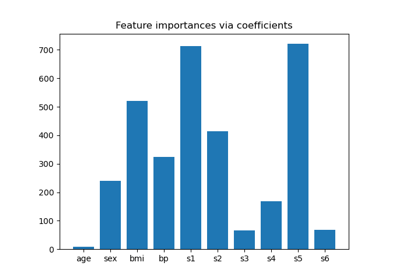
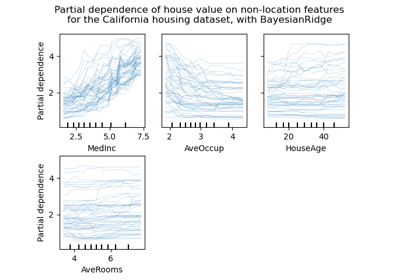
Основанный на модели и последовательный отбор признаков