cross_validate#
- sklearn.model_selection.cross_validate(estimator, X, y=None, *, группы=None, оценка=None, cv=None, n_jobs=None, verbose=0, params=None, pre_dispatch='2*n_jobs', return_train_score=False, return_estimator=False, return_indices=False, error_score=nan)[источник]#
Оценить метрику(и) с помощью перекрестной проверки и также записать время обучения/оценки.
Подробнее в Руководство пользователя.
- Параметры:
- estimatorобъект оценщика, реализующий 'fit'
Объект, используемый для обучения данных.
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные для обучения. Могут быть, например, списком или массивом.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), по умолчанию=None
Целевая переменная, которую пытаются предсказать в случае обучения с учителем.
- группыarray-like формы (n_samples,), по умолчанию=None
Метки групп для образцов, используемых при разделении набора данных на обучающую/тестовую выборки. Используется только в сочетании с "Group" cv экземпляр (например,
GroupKFold).Изменено в версии 1.4:
groupsможет быть передан только если маршрутизация метаданных не включена черезsklearn.set_config(enable_metadata_routing=True). Когда маршрутизация включена, передайтеgroupsнаряду с другими метаданными черезparamsаргумента вместо этого. Например:cross_validate(..., params={'groups': groups}).- оценкаstr, callable, list, tuple или dict, по умолчанию=None
Стратегия для оценки производительности
estimatorпо разбиениям кросс-валидации.Если
scoringпредставляет собой единичную оценку, можно использовать:одна строка (см. Строковые имена скореров);
вызываемый объект (см. Вызываемые скореры), который возвращает одно значение.
None,estimator’s критерий оценки по умолчанию используется.
Если
scoringпредставляет несколько оценок, можно использовать:список или кортеж уникальных строк;
вызываемый объект, возвращающий словарь, где ключи — это имена метрик, а значения — оценки метрик;
словарь с именами метрик в качестве ключей и вызываемыми объектами в качестве значений.
См. Указание нескольких метрик для оценки для примера.
- cvint, генератор кросс-валидации или итерируемый объект, по умолчанию=None
Определяет стратегию разделения для перекрестной проверки. Возможные значения для cv:
None, чтобы использовать стандартную 5-кратную перекрестную проверку,
int, чтобы указать количество фолдов в
(Stratified)KFold,Итерируемый объект, возвращающий (обучающие, тестовые) разбиения в виде массивов индексов.
Для целочисленных/None входов, если оценщик является классификатором и
yявляется либо бинарным, либо многоклассовым,StratifiedKFoldиспользуется. Во всех остальных случаяхKFoldиспользуется. Эти сплиттеры создаются сshuffle=Falseтак что разбиения будут одинаковыми при всех вызовах.Обратитесь Руководство пользователя для различных стратегий перекрестной проверки, которые можно использовать здесь.
Изменено в версии 0.22:
cvзначение по умолчанию, если None изменено с 3-кратного на 5-кратное.- n_jobsint, default=None
Количество параллельных задач. Обучение оценщика и вычисление оценки параллелизуются по разбиениям перекрестной проверки.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- verboseint, по умолчанию=0
Уровень подробности вывода.
- paramsdict, по умолчанию=None
Параметры для передачи в базовый оценщик
fit, метрика, и разделитель кросс-валидации.Добавлено в версии 1.4.
- pre_dispatchint или str, по умолчанию=’2*n_jobs’
Управляет количеством задач, отправляемых во время параллельного выполнения. Уменьшение этого числа может быть полезно для избежания взрыва потребления памяти, когда отправляется больше задач, чем процессоров может обработать. Этот параметр может быть:
Целое число, указывающее точное количество создаваемых заданий
Строка, дающая выражение как функцию от n_jobs, например, '2*n_jobs'
- return_train_scorebool, по умолчанию=False
Включать ли оценки обучения. Вычисление оценок обучения используется для понимания того, как различные настройки параметров влияют на компромисс между переобучением и недообучением. Однако вычисление оценок на обучающем наборе может быть вычислительно затратным и не является строго необходимым для выбора параметров, обеспечивающих наилучшую обобщающую способность.
Добавлено в версии 0.19.
Изменено в версии 0.21: Значение по умолчанию было изменено с
TruetoFalse- return_estimatorbool, по умолчанию=False
Возвращать ли оценщики, обученные на каждом разделении.
Добавлено в версии 0.20.
- return_indicesbool, по умолчанию=False
Возвращать ли индексы train-test, выбранные для каждого разбиения.
Добавлено в версии 1.3.
- error_score'raise' или числовое, по умолчанию=np.nan
Значение, присваиваемое оценке, если возникает ошибка при обучении оценщика. Если установлено 'raise', ошибка вызывается. Если задано числовое значение, вызывается FitFailedWarning.
Добавлено в версии 0.20.
- Возвращает:
- scoresсловарь массивов float формы (n_splits,)
Массив оценок оценщика для каждого запуска перекрестной проверки.
Возвращается словарь массивов, содержащих массивы оценок/времени для каждого скорера. Возможные ключи для этого
dictявляются:test_scoreМассив оценок для тестовых оценок на каждом фолде cv. Суффикс
_scoreвtest_scoreизменения в конкретной метрике, такой какtest_r2илиtest_aucесли в параметре scoring указано несколько метрик оценки.train_scoreМассив оценок для обучающих выборок на каждом разбиении кросс-валидации. Суффикс
_scoreвtrain_scoreизменения в конкретной метрике, такой какtrain_r2илиtrain_aucесли есть несколько метрик оценки в параметре scoring. Доступно только еслиreturn_train_scoreпараметр являетсяTrue.fit_timeВремя обучения оценщика на тренировочном наборе для каждого разделения кросс-валидации.
score_timeВремя для оценки классификатора на тестовом наборе для каждого разделения cv. (Примечание: время для оценки на обучающем наборе не включается, даже если
return_train_scoreустановлено вTrue).estimatorОбъекты оценщиков для каждого разделения cv. Доступно только если
return_estimatorпараметр установлен вTrue.indicesПозиционные индексы обучающей/тестовой выборки для каждого разбиения кросс-валидации. Возвращается словарь, где ключами являются либо
"train"или"test"и связанные значения представляют собой список целочисленных массивов NumPy с индексами. Доступно только еслиreturn_indices=True.
Смотрите также
cross_val_scoreЗапустить кросс-валидацию для оценки по одному метрике.
cross_val_predictПолучить предсказания из каждого разбиения перекрестной проверки для диагностических целей.
sklearn.metrics.make_scorerСоздать оценщик из метрики производительности или функции потерь.
Примеры
>>> from sklearn import datasets, linear_model >>> from sklearn.model_selection import cross_validate >>> diabetes = datasets.load_diabetes() >>> X = diabetes.data[:150] >>> y = diabetes.target[:150] >>> lasso = linear_model.Lasso()
Оценка с использованием одной метрики
cross_validate>>> cv_results = cross_validate(lasso, X, y, cv=3) >>> sorted(cv_results.keys()) ['fit_time', 'score_time', 'test_score'] >>> cv_results['test_score'] array([0.3315057 , 0.08022103, 0.03531816])
Оценка по нескольким метрикам с использованием
cross_validate(см.scoringдокументация параметра для получения дополнительной информации)>>> scores = cross_validate(lasso, X, y, cv=3, ... scoring=('r2', 'neg_mean_squared_error'), ... return_train_score=True) >>> print(scores['test_neg_mean_squared_error']) [-3635.5 -3573.3 -6114.7] >>> print(scores['train_r2']) [0.28009951 0.3908844 0.22784907]
Примеры галереи#

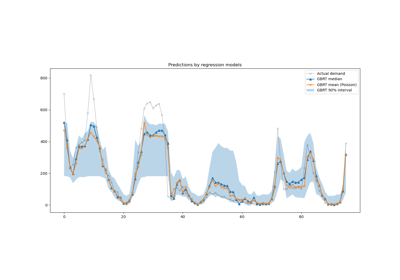
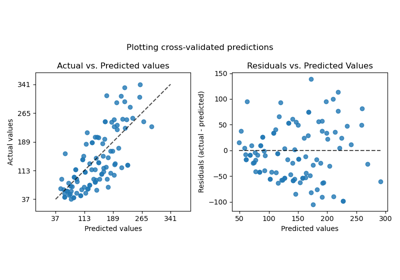
Лаггированные признаки для прогнозирования временных рядов
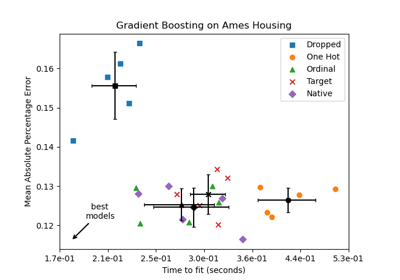
Поддержка категориальных признаков в градиентном бустинге
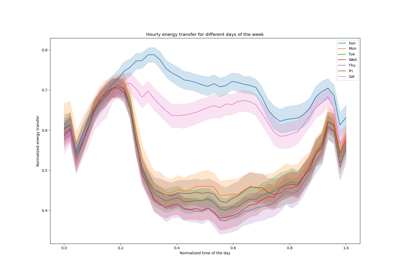
Признаки в деревьях с градиентным бустингом на гистограммах


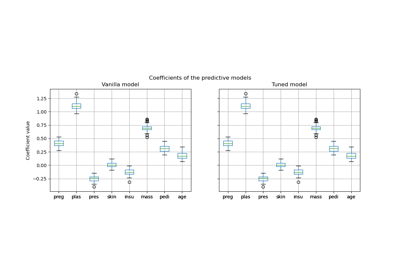
Распространённые ошибки в интерпретации коэффициентов линейных моделей
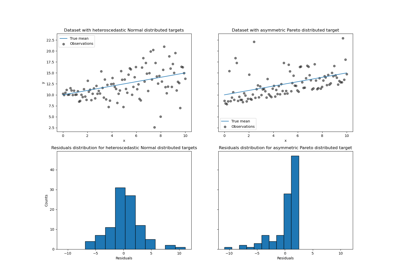

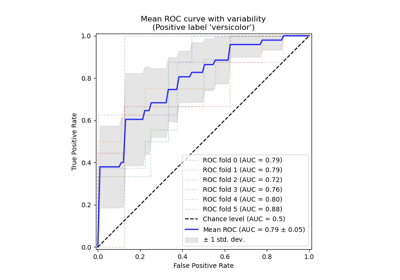
Рабочая характеристика приёмника (ROC) с перекрёстной проверкой
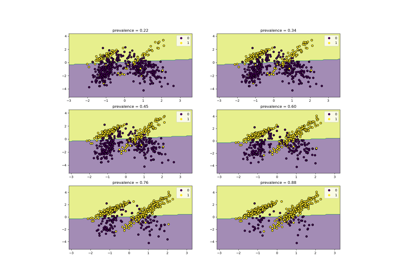
Пост-фактумная настройка точки отсечения функции принятия решений