TargetEncoder#
- класс sklearn.preprocessing.TargetEncoder(категории='auto', target_type='auto', сглаживать='auto', cv=5, перемешивание=True, random_state=None)[источник]#
Кодировщик целевой переменной для регрессии и классификации.
Каждая категория кодируется на основе сжатой оценки средних целевых значений для наблюдений, принадлежащих категории. Схема кодирования смешивает глобальное среднее целевое значение со средним целевым значением, обусловленным значением категории (см. [MIC]).
Когда целевой тип является "многоклассовым", кодировки основаны на оценке условной вероятности для каждого класса. Цель сначала бинаризуется с использованием схемы "один против всех" через
LabelBinarizer, затем среднее целевое значение для каждого класса и каждой категории используется для кодирования, что приводит кn_features*n_classesзакодированные выходные признаки.TargetEncoderучитывает пропущенные значения, такие какnp.nanилиNone, как другую категорию и кодирует их как любую другую категорию. Категории, которые не были замечены во времяfitкодируются средним значением целевой переменной, т.е.target_mean_.Для демонстрации важности
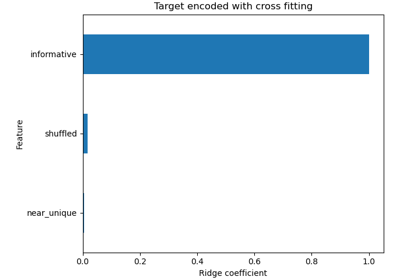
TargetEncoderвнутренней перекрёстной подгонки, см. Внутренняя перекрестная подгонка Target Encoder. Для сравнения различных кодировщиков обратитесь к Сравнение Target Encoder с другими кодировщиками. Подробнее в Руководство пользователя.Примечание
fit(X, y).transform(X). Наличие образцаfit_transform(X, y)потому что кросс-фиттинг схема используется вfit_transformдля кодирования. См. Руководство пользователя подробности.Добавлено в версии 1.3.
- Параметры:
- категории“auto” или список формы (n_features,) из array-like, по умолчанию=”auto”
Категории (уникальные значения) для каждого признака:
"auto": Автоматическое определение категорий на основе обучающих данных.list :
categories[i]содержит категории, ожидаемые в i-м столбце. Переданные категории не должны смешивать строки и числовые значения в одном признаке и должны быть отсортированы в случае числовых значений.
Используемые категории хранятся в
categories_атрибут fitted.- target_type{“auto”, “continuous”, “binary”, “multiclass”}, по умолчанию=”auto”
Тип цели.
"auto": Тип цели выводится с помощьюtype_of_target."continuous": Непрерывная целевая переменная"binary": Бинарная цель"multiclass": Многоклассовая целевая переменная
Примечание
Тип цели, выведенный с помощью
"auto"может не быть желаемым целевым типом, используемым для моделирования. Например, если цель состояла из целых чисел от 0 до 100, тоtype_of_targetбудет определять цель как"multiclass". В этом случае установкаtarget_type="continuous"укажет цель как задачу регрессии. Параметрtarget_type_атрибут указывает тип целевой переменной, используемый кодировщиком.Изменено в версии 1.4: Добавлена опция 'multiclass'.
- сглаживать“auto” или float, по умолчанию=”auto”
Степень смешивания среднего значения целевой переменной, обусловленного значением категории, с глобальным средним значением целевой переменной. Большее
smoothзначение будет придавать больший вес глобальному среднему целевой переменной. Если"auto", затемsmoothустановлен в эмпирическую байесовскую оценку.- cvint, по умолчанию=5
Определяет количество фолдов в кросс-фиттинг стратегия, используемая в
fit_transform. Для целевых переменных классификации,StratifiedKFoldиспользуется и для непрерывных целевых переменных,KFoldиспользуется.- перемешиваниеbool, по умолчанию=True
Перемешивать ли данные в
fit_transformперед разделением на фолды. Обратите внимание, что выборки внутри каждого фолда не будут перемешаны.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Когда
shuffleравно True,random_stateвлияет на порядок индексов, что контролирует случайность каждого сгиба. В противном случае этот параметр не оказывает эффекта. Передайте целое число для воспроизводимого вывода при множественных вызовах функции. См. Глоссарий.
- Атрибуты:
- encodings_, который аналогиченсписок формы (n_features,) или (n_features * n_classes) из ndarray
Кодировки, изученные на всех
X. Для признакаi,encodings_[i]являются кодировками, соответствующими категориям, перечисленным вcategories_[i]. Когдаtarget_type_является "multiclass", кодирование для признакаiи классjхранится вencodings_[j + (i * len(classes_))]. Например, для 2 признаков (f) и 3 классов (c), кодировки упорядочены: f0_c0, f0_c1, f0_c2, f1_c0, f1_c1, f1_c2,- categories_список формы (n_features,) из ndarray
Категории каждого входного признака, определенные во время обучения или указанные в
categories(в порядке признаков вXи соответствует выходным даннымtransform).- target_type_str
Тип цели.
- target_mean_float
Общее среднее целевой переменной. Это значение используется только в
transformдля кодирования категорий.- n_features_in_int
Количество признаков, замеченных во время fit.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.- classes_ndarray или None
Если
target_type_является 'binary' или 'multiclass', содержит метку для каждого класса, в противном случаеNone.
Смотрите также
OrdinalEncoderВыполняет порядковое (целочисленное) кодирование категориальных признаков. В отличие от TargetEncoder, это кодирование не является контролируемым. Обработка полученного кодирования как числовых признаков приводит к произвольно упорядоченным значениям и, как правило, к более низкой прогностической производительности при использовании в качестве предобработки для классификатора или регрессора.
OneHotEncoderВыполняет one-hot кодирование категориальных признаков. Это неконтролируемое кодирование лучше подходит для категориальных переменных с низкой кардинальностью, так как создает один новый признак для каждой уникальной категории.
Ссылки
Примеры
С
smooth="auto", параметр сглаживания устанавливается в эмпирическую байесовскую оценку:>>> import numpy as np >>> from sklearn.preprocessing import TargetEncoder >>> X = np.array([["dog"] * 20 + ["cat"] * 30 + ["snake"] * 38], dtype=object).T >>> y = [90.3] * 5 + [80.1] * 15 + [20.4] * 5 + [20.1] * 25 + [21.2] * 8 + [49] * 30 >>> enc_auto = TargetEncoder(smooth="auto") >>> X_trans = enc_auto.fit_transform(X, y)
>>> # A high `smooth` parameter puts more weight on global mean on the categorical >>> # encodings: >>> enc_high_smooth = TargetEncoder(smooth=5000.0).fit(X, y) >>> enc_high_smooth.target_mean_ np.float64(44.3) >>> enc_high_smooth.encodings_ [array([44.1, 44.4, 44.3])]
>>> # On the other hand, a low `smooth` parameter puts more weight on target >>> # conditioned on the value of the categorical: >>> enc_low_smooth = TargetEncoder(smooth=1.0).fit(X, y) >>> enc_low_smooth.encodings_ [array([21, 80.8, 43.2])]
- fit(X, y)[источник]#
Обучить
TargetEncoderк X и y.Не рекомендуется использовать этот метод, так как он может привести к утечке данных. Используйте
fit_transformна обучающих данных вместо.Примечание
fit(X, y).transform(X). Наличие образцаfit_transform(X, y)потому что кросс-фиттинг схема используется вfit_transformдля кодирования. См. Руководство пользователя подробности.- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для определения категорий каждого признака.
- yarray-like формы (n_samples,)
Целевые данные, используемые для кодирования категорий.
- Возвращает:
- selfobject
Обученный энкодер.
- fit_transform(X, y)[источник]#
Обучить
TargetEncoderи преобразоватьXс целевым кодированием.Этот метод использует кросс-фиттинг схема для предотвращения утечки целевой переменной и переобучения в последующих предикторах. Это рекомендуемый метод для кодирования обучающих данных.
Примечание
fit(X, y).transform(X). Наличие образцаfit_transform(X, y)потому что кросс-фиттинг схема используется вfit_transformдля кодирования. См. Руководство пользователя подробности.- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для определения категорий каждого признака.
- yarray-like формы (n_samples,)
Целевые данные, используемые для кодирования категорий.
- Возвращает:
- X_transndarray формы (n_samples, n_features) или (n_samples, (n_features * n_classes))
Преобразованный вход.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
feature_names_in_используется, если он не определен, в этом случае генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"]. Когдаtype_of_target_является «многоклассовым», имена имеют формат ‘<имя_признака>_<имя_класса>’.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать X с помощью таргет-энкодинга.
Этот метод внутренне использует
encodings_атрибут, изученный во времяTargetEncoder.fit_transformдля преобразования тестовых данных.Примечание
fit(X, y).transform(X). Наличие образцаfit_transform(X, y)потому что кросс-фиттинг схема используется вfit_transformдля кодирования. См. Руководство пользователя подробности.- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные для определения категорий каждого признака.
- Возвращает:
- X_transndarray формы (n_samples, n_features) или (n_samples, (n_features * n_classes))
Преобразованный вход.
Примеры галереи#
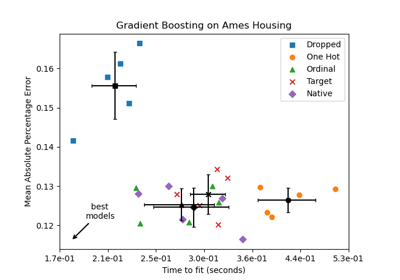
Поддержка категориальных признаков в градиентном бустинге