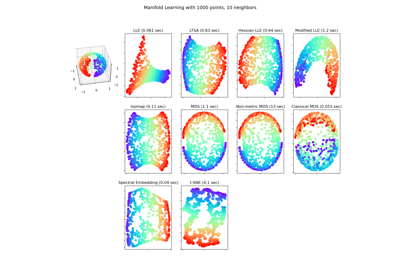
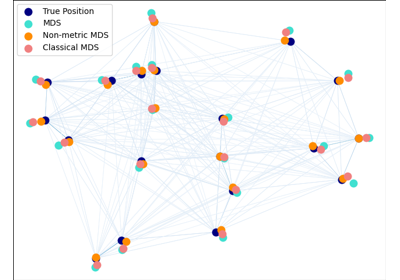
MDS#
- класс sklearn.manifold.MDS(n_components=2, *, metric_mds=True, n_init='warn', init='warn', max_iter=300, verbose=0, eps=1e-06, n_jobs=None, random_state=None, несходство='устаревший', метрика='euclidean', metric_params=None, normalized_stress='auto')[источник]#
Многомерное шкалирование.
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, по умолчанию=2
Количество измерений, в которые погружаются несходства.
- metric_mdsbool, по умолчанию=True
Если
True, выполните метрическое MDS; в противном случае выполните неметрическое MDS. КогдаFalse(т.е. неметрический MDS), несходства с 0 считаются пропущенными значениями.Изменено в версии 1.8: Параметр
metricбыло переименовано вmetric_mds.- n_initint, по умолчанию=4
Количество запусков алгоритма SMACOF с различными инициализациями. Конечные результаты будут лучшим выводом из запусков, определяемым запуском с наименьшим конечным стрессом.
Изменено в версии 1.9: Значение по умолчанию для
n_initизменится с 4 на 1 в версии 1.9.- init{‘random’, ‘classical_mds’}, по умолчанию=’random’
Подход инициализации. Если
random, используется случайная инициализация. Еслиclassical_mds, затем запускается классический MDS и используется как инициализация для MDS (в этом случае значениеn_initигнорируется).Добавлено в версии 1.8.
Изменено в версии 1.10: Значение по умолчанию для
initизменится наclassical_mds.- max_iterint, по умолчанию=300
Максимальное количество итераций алгоритма SMACOF для одного запуска.
- verboseint, по умолчанию=0
Уровень подробности вывода.
- epsfloat, по умолчанию=1e-6
Допуск относительно стресса (нормализованного суммой квадратов расстояний вложения), при котором объявляется сходимость.
Изменено в версии 1.7: Значение по умолчанию для
epsизменилось с 1e-3 на 1e-6 в результате исправления ошибки в вычислении критерия сходимости.- n_jobsint, default=None
Количество заданий для вычислений. Если используется несколько инициализаций (
n_init), каждая итерация алгоритма вычисляется параллельно.Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генератор случайных чисел, используемый для инициализации центров. Передайте целое число для воспроизводимых результатов при многократных вызовах функции. См. Глоссарий.
- несходство{‘euclidean’, ‘precomputed’}
Мера несходства для использования:
- 'euclidean':
Попарные евклидовы расстояния между точками в наборе данных.
- 'precomputed':
Предвычисленные несходства передаются непосредственно в
fitиfit_transform.
Устарело с версии 1.8:
dissimilarityбыл переименован вmetricв 1.8 и будет удален в 1.10.- метрикаstr или callable, по умолчанию='euclidean'
Метрика для вычисления несходства. По умолчанию используется "евклидова".
Если metric является строкой, она должна быть одним из вариантов, разрешённых
scipy.spatial.distance.pdistдля его параметра metric, или метрика, перечисленная вsklearn.metrics.pairwise.distance_metricsЕсли метрика "precomputed", предполагается, что X является матрицей расстояний и должна быть квадратной во время обучения.
Если metric - вызываемая функция, она принимает два массива, представляющих 1D векторы, в качестве входных данных и должна возвращать одно значение, указывающее расстояние между этими векторами. Это работает для метрик Scipy, но менее эффективно, чем передача имени метрики в виде строки.
Изменено в версии 1.8: До версии 1.8,
metric=True/Falseиспользовался для выбора метрического/неметрического MDS, что теперь является рольюmetric_mds. Поддержка дляTrueиFalseбудет удалено в версии 1.10, используйтеmetric_mdsвместо этого.- metric_paramsdict, по умолчанию=None
Дополнительные ключевые аргументы для вычисления несходства.
Добавлено в версии 1.8.
- normalized_stressbool или "auto", по умолчанию="auto"
Возвращать ли нормализованное значение стресса (Stress-1) вместо сырого стресса. По умолчанию метрический MDS возвращает сырой стресс, а неметрический MDS возвращает нормализованный стресс.
Добавлено в версии 1.2.
Изменено в версии 1.4: Значение по умолчанию изменилось с
Falseto"auto"в версии 1.4.Изменено в версии 1.7: Нормализованный стресс теперь также поддерживается для метрического MDS.
- Атрибуты:
- embedding_ndarray формы (n_samples, n_components)
Сохраняет позицию набора данных в пространстве вложений.
- stress_float
Конечное значение стресса (сумма квадратов расстояний между диспаритетами и расстояниями для всех ограниченных точек). Если
normalized_stress=True, возвращает Stress-1. Значение 0 указывает на "идеальное" соответствие, 0.025 — отличное, 0.05 — хорошее, 0.1 — удовлетворительное, а 0.2 — плохое [1].- dissimilarity_matrix_ndarray формы (n_samples, n_samples)
Попарные различия между точками. Симметричная матрица, которая:
либо использует пользовательскую матрицу несходства, устанавливая
dissimilarityв 'precomputed';или строит матрицу несходства из данных с использованием евклидовых расстояний.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество итераций, соответствующих наилучшему стрессу.
Смотрите также
sklearn.decomposition.PCAАнализ главных компонент, который является методом линейного снижения размерности.
sklearn.decomposition.KernelPCAНелинейное снижение размерности с использованием ядер и PCA.
TSNEСтохастическое вложение соседей с t-распределением.
IsomapОбучение многообразию на основе изометрического отображения.
LocallyLinearEmbeddingОбучение многообразий с использованием локально линейного вложения.
SpectralEmbeddingСпектральное вложение для нелинейного снижения размерности.
Ссылки
[1]“Неметрическое многомерное шкалирование: численный метод” Крускал, Дж. Психометрика, 29 (1964)
[2]“Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis” Kruskal, J. Psychometrika, 29, (1964)
[3]«Современное многомерное шкалирование - теория и приложения» Борг, И.; Грунен П. Серия Springer по статистике (1997)
Примеры
>>> from sklearn.datasets import load_digits >>> from sklearn.manifold import MDS >>> X, _ = load_digits(return_X_y=True) >>> X.shape (1797, 64) >>> embedding = MDS(n_components=2, n_init=1, init="random") >>> X_transformed = embedding.fit_transform(X[:100]) >>> X_transformed.shape (100, 2)
Для более подробного примера использования см. load_files.
Для сравнения методов обучения многообразий см. Сравнение методов обучения многообразий.
- fit(X, y=None, init=None)[источник]#
Вычислите положение точек в пространстве вложения.
- Параметры:
- Xмассивоподобный объект формы (n_samples, n_features) или (n_samples, n_samples)
Входные данные. Если
metric=='precomputed', вход должен быть матрицей несходства.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- initndarray формы (n_samples, n_components), по умолчанию=None
Начальная конфигурация вложения для инициализации алгоритма SMACOF. По умолчанию алгоритм инициализируется случайно выбранным массивом.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_transform(X, y=None, init=None)[источник]#
Обучить данные из
X, и возвращает встроенные координаты.- Параметры:
- Xмассивоподобный объект формы (n_samples, n_features) или (n_samples, n_samples)
Входные данные. Если
metric=='precomputed', вход должен быть матрицей несходства.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- initndarray формы (n_samples, n_components), по умолчанию=None
Начальная конфигурация вложения для инициализации алгоритма SMACOF. По умолчанию алгоритм инициализируется случайно выбранным массивом.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
X преобразован в новое пространство.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_fit_request(*, init: bool | None | str = '$UNCHANGED$') MDS[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- initstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
initпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#

Обучение многообразию на рукописных цифрах: Locally Linear Embedding, Isomap…