OAS#
- класс sklearn.covariance.OAS(*, store_precision=True, assume_centered=False)[источник]#
Oracle Approximating Shrinkage Estimator.
Подробнее в Руководство пользователя.
- Параметры:
- store_precisionbool, по умолчанию=True
Указать, хранится ли оцененная точность.
- assume_centeredbool, по умолчанию=False
Если True, данные не будут центрироваться перед вычислением. Полезно при работе с данными, среднее значение которых почти, но не совсем равно нулю. Если False (по умолчанию), данные будут центрироваться перед вычислением.
- Атрибуты:
- covariance_ndarray формы (n_features, n_features)
Оценочная ковариационная матрица.
- location_ndarray формы (n_features,)
Оцененное местоположение, т.е. оцененное среднее.
- precision_ndarray формы (n_features, n_features)
Оцененная псевдообратная матрица. (сохраняется только если store_precision равен True)
- shrinkage_float
коэффициент в выпуклой комбинации, используемой для вычисления сжатой оценки. Диапазон [0, 1].
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
EllipticEnvelopeОбъект для обнаружения выбросов в наборе данных с гауссовым распределением.
EmpiricalCovarianceОценка ковариации методом максимального правдоподобия.
GraphicalLassoОценка разреженной обратной ковариации с оценщиком, использующим штраф L1.
GraphicalLassoCVРазреженная обратная ковариация с кросс-валидационным выбором штрафа l1.
LedoitWolfОценщик LedoitWolf.
MinCovDetМинимальный определитель ковариации (робастная оценка ковариации).
ShrunkCovarianceОценщик ковариации с сжатием.
Примечания
Регуляризованная ковариация:
(1 - shrinkage) * cov + shrinkage * mu * np.identity(n_features),
где mu = trace(cov) / n_features, а сжатие задается формулой OAS (см. [1]).
Формулировка сжатия, реализованная здесь, отличается от уравнения 23 в [1]В исходной статье формула (23) утверждает, что 2/p (где p — количество признаков) умножается на Trace(cov*cov) как в числителе, так и в знаменателе, но эта операция опущена, потому что для большого p значение 2/p настолько мало, что не влияет на значение оценщика.
Ссылки
Примеры
>>> import numpy as np >>> from sklearn.covariance import OAS >>> from sklearn.datasets import make_gaussian_quantiles >>> real_cov = np.array([[.8, .3], ... [.3, .4]]) >>> rng = np.random.RandomState(0) >>> X = rng.multivariate_normal(mean=[0, 0], ... cov=real_cov, ... size=500) >>> oas = OAS().fit(X) >>> oas.covariance_ array([[0.7533, 0.2763], [0.2763, 0.3964]]) >>> oas.precision_ array([[ 1.7833, -1.2431 ], [-1.2431, 3.3889]]) >>> oas.shrinkage_ np.float64(0.0195)
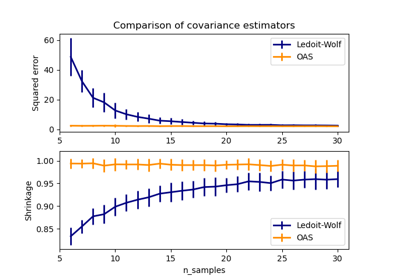
Смотрите также Оценка ковариации сжатием: LedoitWolf vs OAS и максимальное правдоподобие и Оценка Ледойта-Вольфа против OAS оценки для более подробных примеров.
- отличается от(comp_cov, norm='frobenius', масштабирование=True, квадрат=True)[источник]#
Вычислить среднеквадратичную ошибку между двумя оценщиками ковариации.
- Параметры:
- comp_covarray-like формы (n_features, n_features)
Ковариация для сравнения.
- norm{“frobenius”, “spectral”}, по умолчанию=”frobenius”
Тип нормы, используемой для вычисления ошибки. Доступные типы ошибок: - 'frobenius' (по умолчанию): sqrt(tr(A^t.A)) - 'spectral': sqrt(max(eigenvalues(A^t.A)) где A - ошибка
(comp_cov - self.covariance_).- масштабированиеbool, по умолчанию=True
Если True (по умолчанию), норма квадрата ошибки делится на n_features. Если False, норма квадрата ошибки не масштабируется.
- квадратbool, по умолчанию=True
Вычислять ли квадрат нормы ошибки или норму ошибки. Если True (по умолчанию), возвращается квадрат нормы ошибки. Если False, возвращается норма ошибки.
- Возвращает:
- результатfloat
Среднеквадратичная ошибка (в смысле нормы Фробениуса) между
selfиcomp_covоценки ковариации.
- fit(X, y=None)[источник]#
Подогнать модель ковариации Oracle Approximating Shrinkage к X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- get_precision()[источник]#
Геттер для матрицы точности.
- Возвращает:
- precision_array-like формы (n_features, n_features)
Матрица точности, связанная с текущим объектом ковариации.
- mahalanobis(X)[источник]#
Вычислить квадратные расстояния Махаланобиса для заданных наблюдений.
Для подробного примера того, как выбросы влияют на расстояние Махаланобиса, см. Робастная оценка ковариации и релевантность расстояний Махаланобиса.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Наблюдения, для которых мы вычисляем расстояния Махаланобиса. Предполагается, что наблюдения взяты из того же распределения, что и данные, использованные при обучении.
- Возвращает:
- distndarray формы (n_samples,)
Квадраты расстояний Махаланобиса наблюдений.
- score(X_test, y=None)[источник]#
Вычислить логарифмическое правдоподобие
X_testв рамках предполагаемой гауссовой модели.Гауссова модель определяется её средним значением и ковариационной матрицей, которые представлены соответственно
self.location_иself.covariance_.- Параметры:
- X_testarray-like формы (n_samples, n_features)
Тестовые данные, для которых вычисляется правдоподобие, где
n_samplesэто количество образцов иn_featuresэто количество признаков.X_testпредполагается, что он взят из того же распределения, что и данные, использованные при обучении (включая центрирование).- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- resfloat
Логарифм правдоподобия
X_testсself.location_иself.covariance_как оценщики среднего значения и ковариационной матрицы гауссовой модели соответственно.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
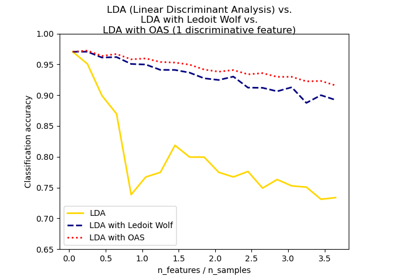
Нормальный, Ledoit-Wolf и OAS линейный дискриминантный анализ для классификации
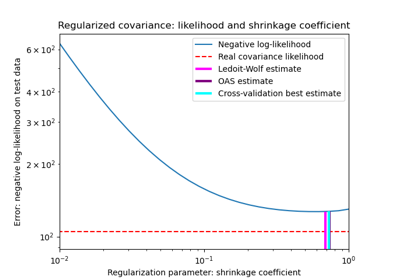
Оценка ковариации сжатием: LedoitWolf vs OAS и максимальное правдоподобие