PCA#
- класс sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', n_oversamples=10, power_iteration_normalizer='auto', random_state=None)[источник]#
Метод главных компонент (PCA).
Линейное снижение размерности с использованием сингулярного разложения данных для их проекции в пространство меньшей размерности. Входные данные центрируются, но не масштабируются для каждого признака перед применением SVD.
Использует реализацию LAPACK полного SVD или рандомизированного усечённого SVD методом Halko et al. 2009, в зависимости от формы входных данных и количества извлекаемых компонент.
При разреженных входных данных может использоваться реализация ARPACK усеченного SVD (т.е. через
scipy.sparse.linalg.svds). В качестве альтернативы можно рассмотретьTruncatedSVDгде данные не центрированы.Обратите внимание, что этот класс поддерживает разреженные входные данные только для некоторых решателей, таких как "arpack" и "covariance_eigh". См.
TruncatedSVDдля альтернативы с разреженными данными.Пример использования см. в Анализ главных компонент (PCA) на наборе данных Iris
Подробнее в Руководство пользователя.
- Параметры:
- n_componentsint, float или ‘mle’, по умолчанию=None
Количество компонент для сохранения. Если n_components не задано, сохраняются все компоненты:
n_components == min(n_samples, n_features)
Если
n_components == 'mle'иsvd_solver == 'full', MLE Минки используется для оценки размерности. Использованиеn_components == 'mle'будет интерпретироватьsvd_solver == 'auto'какsvd_solver == 'full'.Если
0 < n_components < 1иsvd_solver == 'full', выберите количество компонентов так, чтобы количество дисперсии, которое необходимо объяснить, было больше процента, указанного в n_components.Если
svd_solver == 'arpack', количество компонент должно быть строго меньше минимума из n_features и n_samples.Следовательно, случай None приводит к:
n_components == min(n_samples, n_features) - 1
- copybool, по умолчанию=True
Если False, данные, переданные в fit, перезаписываются, и выполнение fit(X).transform(X) не даст ожидаемых результатов, используйте вместо этого fit_transform(X).
- whitenbool, по умолчанию=False
Когда True (по умолчанию False),
components_векторы умножаются на квадратный корень из n_samples и затем делятся на сингулярные значения, чтобы обеспечить некоррелированные выходы с единичными покомпонентными дисперсиями.Отбеливание удалит некоторую информацию из преобразованного сигнала (относительные масштабы дисперсий компонентов), но иногда может улучшить точность предсказания последующих оценщиков, заставляя их данные соответствовать некоторым жёстко заданным предположениям.
- svd_solver{‘auto’, ‘full’, ‘covariance_eigh’, ‘arpack’, ‘randomized’}, по умолчанию=’auto’
- “auto” :
Решатель выбирается политикой по умолчанию 'auto', основанной на
X.shapeиn_components: если входные данные имеют менее 1000 признаков и более чем в 10 раз больше выборок, то используется решатель "covariance_eigh". В противном случае, если входные данные больше 500x500 и количество извлекаемых компонентов меньше 80% от наименьшего измерения данных, то выбирается более эффективный "randomized" метод. В противном случае вычисляется точный "full" SVD и при необходимости обрезается после.- “full” :
Запустить точное полное SVD, вызывая стандартный решатель LAPACK через
scipy.linalg.svdи выбрать компоненты постобработкой- "covariance_eigh" :
Предварительно вычислить ковариационную матрицу (по центрированным данным), выполнить классическое разложение по собственным значениям ковариационной матрицы, обычно с использованием LAPACK, и выбрать компоненты с помощью постобработки. Этот решатель очень эффективен для n_samples >> n_features и малых n_features. Однако он не применим в других случаях для больших n_features (требуется большой объем памяти для материализации ковариационной матрицы). Также обратите внимание, что по сравнению с решателем “full” этот решатель эффективно удваивает число обусловленности и поэтому менее численно устойчив (например, на входных данных с большим диапазоном сингулярных значений).
- "arpack" :
Выполнить усеченное SVD до
n_componentsвызов решателя ARPACK черезscipy.sparse.linalg.svds. Требует строго0 < n_components < min(X.shape)- “randomized” :
Запуск рандомизированного SVD методом Halko и др.
Добавлено в версии 0.18.0.
Изменено в версии 1.5: Добавлен решатель ‘covariance_eigh’.
- tolfloat, по умолчанию=0.0
Допуск для сингулярных значений, вычисленных при svd_solver == 'arpack'. Должен быть в диапазоне [0.0, бесконечность).
Добавлено в версии 0.18.0.
- iterated_powerint или 'auto', по умолчанию='auto'
Количество итераций для степенного метода, вычисляемого при svd_solver == ‘randomized’. Должно быть в диапазоне [0, бесконечность).
Добавлено в версии 0.18.0.
- n_oversamplesint, по умолчанию=10
Этот параметр актуален только тогда, когда
svd_solver="randomized". Соответствует дополнительному количеству случайных векторов для выборки диапазонаXчтобы обеспечить правильную обусловленность. См.randomized_svdдля получения дополнительной информации.Добавлено в версии 1.1.
- power_iteration_normalizer{‘auto’, ‘QR’, ‘LU’, ‘none’}, по умолчанию=’auto’
Нормализатор степенной итерации для рандомизированного решателя SVD. Не используется ARPACK. См.
randomized_svdдля получения дополнительной информации.Добавлено в версии 1.1.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Используется, когда применяются решатели 'arpack' или 'randomized'. Передайте int для воспроизводимых результатов при многократных вызовах функции. См. Глоссарий.
Добавлено в версии 0.18.0.
- Атрибуты:
- components_ndarray формы (n_components, n_features)
Главные оси в пространстве признаков, представляющие направления максимальной дисперсии в данных. Эквивалентно, правые сингулярные векторы центрированных входных данных, параллельные их собственным векторам. Компоненты отсортированы по убыванию
explained_variance_.- explained_variance_ndarray формы (n_components,)
Объясненная дисперсия каждого из выбранных компонентов. Оценка дисперсии использует
n_samples - 1степени свободы.Равно n_components наибольшим собственным значениям ковариационной матрицы X.
Добавлено в версии 0.18.
- explained_variance_ratio_ndarray формы (n_components,)
Процент дисперсии, объясняемый каждой из выбранных компонент.
Если
n_componentsне установлено, то все компоненты сохраняются, и сумма отношений равна 1.0.- singular_values_ndarray формы (n_components,)
Сингулярные значения, соответствующие каждому из выбранных компонентов. Сингулярные значения равны 2-нормам
n_componentsпеременные в пространстве меньшей размерности.Добавлено в версии 0.19.
- mean_ndarray формы (n_features,)
Эмпирическое среднее по признакам, оцененное на обучающей выборке.
Равно
X.mean(axis=0).- n_components_int
Оцененное количество компонент. Когда n_components установлено в 'mle' или число от 0 до 1 (при svd_solver == 'full'), это число оценивается на основе входных данных. В противном случае оно равно параметру n_components или меньшему значению из n_features и n_samples, если n_components равно None.
- n_samples_int
Количество выборок в обучающих данных.
- noise_variance_float
Оцененная ковариация шума в соответствии с моделью вероятностного PCA от Tipping и Bishop 1999. См. “Pattern Recognition and Machine Learning” от C. Bishop, 12.2.1 стр. 574 или http://www.miketipping.com/papers/met-mppca.pdf. Это требуется для вычисления оценённой ковариации данных и оценки выборок.
Равно среднему значению (min(n_features, n_samples) - n_components) наименьших собственных значений ковариационной матрицы X.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
KernelPCAЯдерный метод главных компонент.
SparsePCAРазреженный анализ главных компонент.
TruncatedSVDУменьшение размерности с использованием усеченного SVD.
IncrementalPCAИнкрементальный анализ главных компонент.
Ссылки
Для n_components == 'mle' этот класс использует метод из: Minka, T. P.. “Automatic choice of dimensionality for PCA”. In NIPS, pp. 598-604
Реализует вероятностную модель PCA из: Tipping, M. E., и Bishop, C. M. (1999). «Вероятностный главный компонентный анализ». Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(3), 611-622. через методы score и score_samples.
Для svd_solver == 'arpack' см.
scipy.sparse.linalg.svds.Для svd_solver == 'randomized', см.: Халко, Н., Мартинссон, П. Г., и Тропп, Дж. А. (2011). "Нахождение структуры с помощью случайности: Вероятностные алгоритмы для построения приближенных матричных разложений". SIAM review, 53(2), 217-288. а также Martinsson, P. G., Rokhlin, V., and Tygert, M. (2011). “A randomized algorithm for the decomposition of matrices”. Applied and Computational Harmonic Analysis, 30(1), 47-68.
Примеры
>>> import numpy as np >>> from sklearn.decomposition import PCA >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> pca = PCA(n_components=2) >>> pca.fit(X) PCA(n_components=2) >>> print(pca.explained_variance_ratio_) [0.9924 0.0075] >>> print(pca.singular_values_) [6.30061 0.54980]
>>> pca = PCA(n_components=2, svd_solver='full') >>> pca.fit(X) PCA(n_components=2, svd_solver='full') >>> print(pca.explained_variance_ratio_) [0.9924 0.00755] >>> print(pca.singular_values_) [6.30061 0.54980]
>>> pca = PCA(n_components=1, svd_solver='arpack') >>> pca.fit(X) PCA(n_components=1, svd_solver='arpack') >>> print(pca.explained_variance_ratio_) [0.99244] >>> print(pca.singular_values_) [6.30061]
- fit(X, y=None)[источник]#
Обучите модель с X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Игнорируется.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None)[источник]#
Обучить модель с X и применить уменьшение размерности к X.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Игнорируется.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Преобразованные значения.
Примечания
This method returns a Fortran-ordered array. To convert it to a C-ordered array, use ‘np.ascontiguousarray’.
- get_covariance()[источник]#
Вычисление ковариации данных с порождающей моделью.
cov = components_.T * S**2 * components_ + sigma2 * eye(n_features)где S**2 содержит объяснённые дисперсии, а sigma2 содержит дисперсии шума.- Возвращает:
- covмассив формы=(n_features, n_features)
Оцененная ковариация данных.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- get_precision()[источник]#
Вычислить матрицу точности данных с генеративной моделью.
Равен обратной ковариационной матрице, но вычислен с использованием леммы обращения матрицы для эффективности.
- Возвращает:
- точностьмассив, shape=(n_features, n_features)
Оцененная точность данных.
- inverse_transform(X)[источник]#
Преобразование данных обратно в исходное пространство.
Другими словами, вернуть входные данные
X_originalчей transform будет X.- Параметры:
- Xarray-like формы (n_samples, n_components)
Новые данные, где
n_samplesэто количество образцов иn_componentsэто количество компонентов.
- Возвращает:
- X_originalarray-like формы (n_samples, n_features)
Исходные данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.
Примечания
Если включено отбеливание, inverse_transform вычислит точную обратную операцию, включая отмену отбеливания.
- score(X, y=None)[источник]#
Вернуть среднее логарифмическое правдоподобие всех выборок.
См. “Pattern Recognition and Machine Learning” by C. Bishop, 12.2.1 p. 574 или http://www.miketipping.com/papers/met-mppca.pdf
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные.
- yИгнорируется
Игнорируется.
- Возвращает:
- llfloat
Средняя логарифмическая правдоподобия образцов при текущей модели.
- score_samples(X)[источник]#
Вернуть логарифмическое правдоподобие для каждой выборки.
См. “Pattern Recognition and Machine Learning” by C. Bishop, 12.2.1 p. 574 или http://www.miketipping.com/papers/met-mppca.pdf
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные.
- Возвращает:
- llndarray формы (n_samples,)
Логарифмическое правдоподобие каждого образца в текущей модели.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Применить уменьшение размерности к X.
X проецируется на первые главные компоненты, ранее извлеченные из обучающего набора.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Новые данные, где
n_samplesэто количество образцов иn_featuresэто количество признаков.
- Возвращает:
- X_newarray-like формы (n_samples, n_components)
Проекция X на первые главные компоненты, где
n_samples— это количество образцов иn_componentsявляется количеством компонентов.
Примеры галереи#

Удаление шума с изображения с использованием ядерного PCA
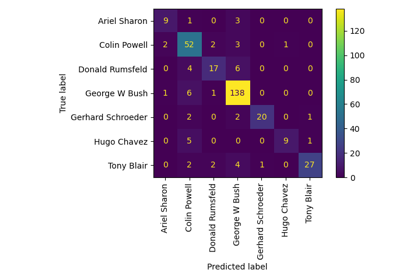
Пример распознавания лиц с использованием собственных лиц и SVM
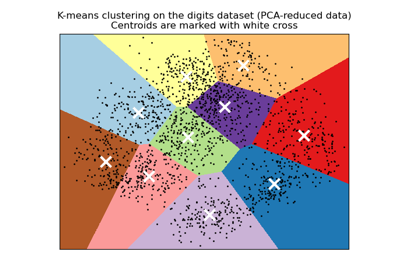
Демонстрация кластеризации K-Means на данных рукописных цифр
Трансформер столбцов с разнородными источниками данных
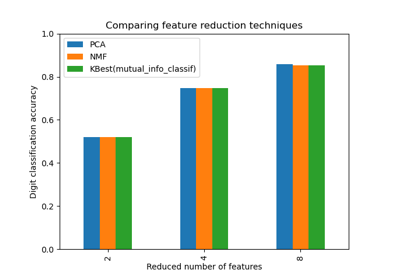
Выбор уменьшения размерности с помощью Pipeline и GridSearchCV
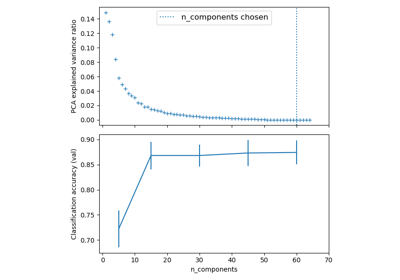
Конвейеризация: объединение PCA и логистической регрессии

Объединение нескольких методов извлечения признаков
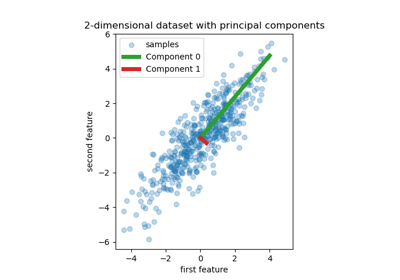
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов

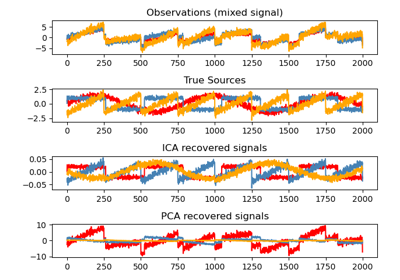
Разделение слепых источников с использованием FastICA
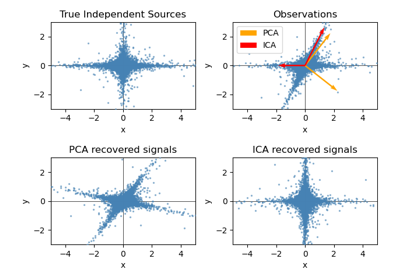
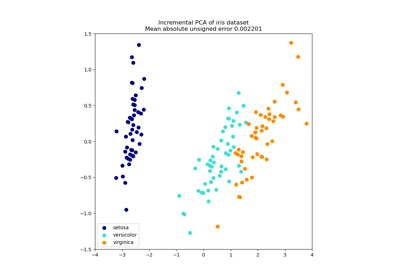
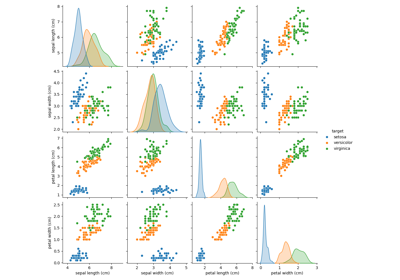
Анализ главных компонент (PCA) на наборе данных Iris

Выбор модели с вероятностным PCA и факторным анализом (FA)
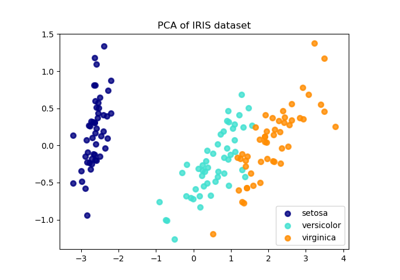
Сравнение LDA и PCA 2D проекции набора данных Iris
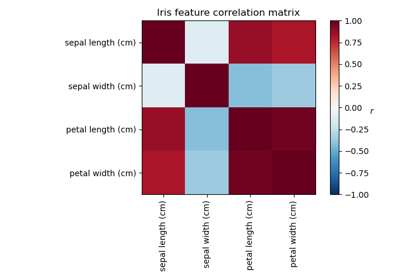
Факторный анализ (с вращением) для визуализации паттернов
Аппроксимация явного отображения признаков для RBF-ядер

Баланс сложности модели и кросс-валидационной оценки

Снижение размерности с помощью анализа компонентов соседства