completeness_score#
- sklearn.metrics.completeness_score(labels_true, labels_pred)[источник]#
: Вычисляет порог для приемлемой производительности (лучший результат - 1 ст. откл.)
Результат кластеризации удовлетворяет полноте, если все точки данных, принадлежащие одному классу, являются элементами одного и того же кластера.
Эта метрика не зависит от абсолютных значений меток: перестановка значений меток классов или кластеров не изменит значение оценки никаким образом.
Эта метрика не симметрична: переключение
label_trueсlabel_predвернетhomogeneity_scoreкоторые в общем случае будут разными.Подробнее в Руководство пользователя.
- Параметры:
- labels_truearray-like формы (n_samples,)
Истинные метки классов, используемые в качестве эталона.
- labels_predarray-like формы (n_samples,)
Метки кластеров для оценки.
- Возвращает:
- полнотаfloat
Оценка от 0.0 до 1.0. 1.0 означает идеально полную маркировку.
Смотрите также
homogeneity_scoreМетрика однородности кластерной разметки.
v_measure_scoreV-мера (NMI с опцией среднего арифметического).
Ссылки
Примеры
Идеальные разметки являются полными:
>>> from sklearn.metrics.cluster import completeness_score >>> completeness_score([0, 0, 1, 1], [1, 1, 0, 0]) 1.0
Неидеальные разметки, которые относят всех членов классов к одним и тем же кластерам, все равно являются полными:
>>> print(completeness_score([0, 0, 1, 1], [0, 0, 0, 0])) 1.0 >>> print(completeness_score([0, 1, 2, 3], [0, 0, 1, 1])) 0.999
Если члены классов разделены по разным кластерам, назначение не может быть полным:
>>> print(completeness_score([0, 0, 1, 1], [0, 1, 0, 1])) 0.0 >>> print(completeness_score([0, 0, 0, 0], [0, 1, 2, 3])) 0.0
Примеры галереи#
Демонстрация алгоритма кластеризации с распространением аффинности
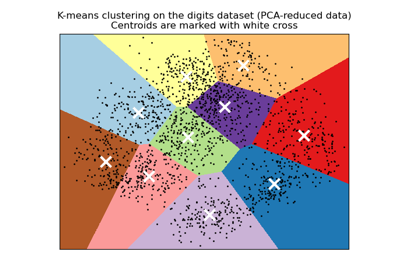
Демонстрация кластеризации K-Means на данных рукописных цифр
Кластеризация текстовых документов с использованием k-means