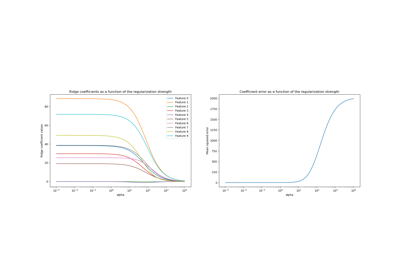
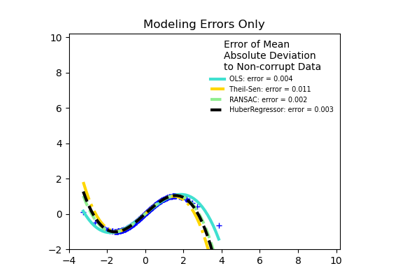
HuberRegressor#
- класс sklearn.linear_model.HuberRegressor(*, эпсилон=1.35, max_iter=100, alpha=0.0001, warm_start=False, fit_intercept=True, tol=1e-05)[источник]#
L2-регуляризованная линейная регрессионная модель, устойчивая к выбросам.
Регрессор Хубера оптимизирует квадратичную потерю для выборок, где
|(y - Xw - c) / sigma| < epsilonи абсолютная потеря для выборок, где|(y - Xw - c) / sigma| > epsilon, где коэффициенты моделиw, свободный членcи масштабsigmaявляются параметрами для оптимизации. Параметрsigmaгарантирует, что еслиyмасштабируется вверх или вниз на определенный коэффициент, не требуется перемасштабироватьepsilonдля достижения той же устойчивости. Обратите внимание, что это не учитывает факт, что различные признакиXмогут иметь разные масштабы.Функция потерь Хубера имеет преимущество в том, что на нее не сильно влияют выбросы, но при этом она не полностью игнорирует их эффект.
Подробнее в Руководство пользователя
Добавлено в версии 0.18.
- Параметры:
- эпсилонfloat, по умолчанию=1.35
Параметр эпсилон контролирует количество образцов, которые должны быть классифицированы как выбросы. Чем меньше эпсилон, тем более устойчив он к выбросам. Эпсилон должен находиться в диапазоне
[1, inf).- max_iterint, по умолчанию=100
Максимальное количество итераций, которое
scipy.optimize.minimize(method="L-BFGS-B")должен выполняться.- alphafloat, по умолчанию=0.0001
Сила квадратичной L2-регуляризации. Обратите внимание, что штраф равен
alpha * ||w||^2. Должно быть в диапазоне[0, inf).- warm_startbool, по умолчанию=False
Это полезно, если сохраненные атрибуты ранее использованной модели должны быть повторно использованы. Если установлено значение False, то коэффициенты будут перезаписаны при каждом вызове fit. См. Глоссарий.
- fit_interceptbool, по умолчанию=True
Обучиться ли свободному члену. Это может быть установлено в False, если данные уже центрированы относительно начала координат.
- tolfloat, по умолчанию=1e-05
Итерация остановится, когда
max{|proj g_i | i = 1, ..., n}<=tolгде pg_i — это i-я компонента проекции градиента.
- Атрибуты:
- coef_массив, форма (n_features,)
Признаки, полученные путем оптимизации L2-регуляризованной потери Хубера.
- intercept_float
Смещение.
- scale_float
Значение, на которое
|y - Xw - c|масштабируется вниз.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_iter_int
Количество итераций, которые
scipy.optimize.minimize(method="L-BFGS-B")выполнялся.Изменено в версии 0.20: В SciPy <= 1.0.0 количество итераций lbfgs может превышать
max_iter.n_iter_теперь будет сообщать не болееmax_iter.- выбросы_массив, формы (n_samples,)
Булева маска, которая устанавливается в True там, где образцы идентифицированы как выбросы.
Смотрите также
RANSACRegressorАлгоритм RANSAC (RANdom SAmple Consensus).
TheilSenRegressorМногомерная регрессионная модель Theil-Sen Estimator, устойчивая к выбросам.
SGDRegressorПодгоняется путем минимизации регуляризованной эмпирической потери с помощью SGD.
Ссылки
[1]Peter J. Huber, Elvezio M. Ronchetti, Robust Statistics Concomitant scale estimates, p. 172
[2]Art B. Owen (2006), Устойчивый гибрид лассо и гребневой регрессии.
Примеры
>>> import numpy as np >>> from sklearn.linear_model import HuberRegressor, LinearRegression >>> from sklearn.datasets import make_regression >>> rng = np.random.RandomState(0) >>> X, y, coef = make_regression( ... n_samples=200, n_features=2, noise=4.0, coef=True, random_state=0) >>> X[:4] = rng.uniform(10, 20, (4, 2)) >>> y[:4] = rng.uniform(10, 20, 4) >>> huber = HuberRegressor().fit(X, y) >>> huber.score(X, y) -7.284 >>> huber.predict(X[:1,]) array([806.7200]) >>> linear = LinearRegression().fit(X, y) >>> print("True coefficients:", coef) True coefficients: [20.4923... 34.1698...] >>> print("Huber coefficients:", huber.coef_) Huber coefficients: [17.7906... 31.0106...] >>> print("Linear Regression coefficients:", linear.coef_) Linear Regression coefficients: [-1.9221... 7.0226...]
- fit(X, y, sample_weight=None)[источник]#
Обучает модель на основе предоставленных обучающих данных.
- Параметры:
- Xarray-like, shape (n_samples, n_features)
Вектор обучения, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yarray-like, shape (n_samples,)
Целевой вектор относительно X.
- sample_weightarray-like, shape (n_samples,)
Вес, присвоенный каждому образцу.
- Возвращает:
- selfobject
Обученная
HuberRegressorоценщик.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Прогнозирование с использованием линейной модели.
- Параметры:
- Xмассивоподобный или разреженная матрица, форма (n_samples, n_features)
Образцы.
- Возвращает:
- Cмассив, формы (n_samples,)
Возвращает предсказанные значения.
- score(X, y, sample_weight=None)[источник]#
Возвращает коэффициент детерминации на тестовых данных.
Коэффициент детерминации, \(R^2\), определяется как \((1 - \frac{u}{v})\), где \(u\) является остаточной суммой квадратов
((y_true - y_pred)** 2).sum()и \(v\) является общей суммой квадратов((y_true - y_true.mean()) ** 2).sum()Лучший возможный результат - 1.0, и он может быть отрицательным (потому что модель может быть сколь угодно хуже). Постоянная модель, которая всегда предсказывает ожидаемое значениеy, игнорируя входные признаки, получит \(R^2\) оценка 0.0.- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки. Для некоторых оценщиков это может быть предварительно вычисленная матрица ядра или список общих объектов вместо этого с формой
(n_samples, n_samples_fitted), гдеn_samples_fitted— это количество образцов, использованных при обучении оценщика.- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные значения для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
\(R^2\) of
self.predict(X)относительноy.
Примечания
The \(R^2\) оценка, используемая при вызове
scoreна регрессоре используетmultioutput='uniform_average'с версии 0.23 для сохранения согласованности со значением по умолчаниюr2_score. Это влияет наscoreметод всех многомерных регрессоров (кромеMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') HuberRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') HuberRegressor[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
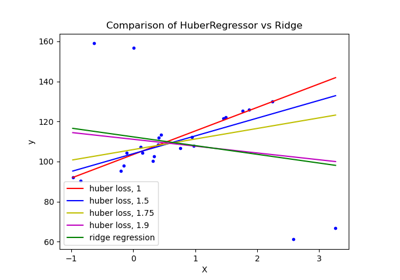
HuberRegressor против Ridge на наборе данных с сильными выбросами