fetch_20newsgroups#
- sklearn.datasets.fetch_20newsgroups(*, data_home=None, subset='train', категории=None, перемешивание=True, random_state=42, удалить=(), download_if_missing=True, return_X_y=False, n_retries=3, задержка=1.0)[источник]#
Загрузка имён файлов и данных из набора данных 20 новостных групп (классификация).
Загружает его, если необходимо.
Классы
20
Всего образцов
18846
Снижение размерности
1
Признаки
текст
Подробнее в Руководство пользователя.
- Параметры:
- data_homestr или path-like, по умолчанию=None
Укажите папку для загрузки и кэширования наборов данных. Если None, все данные scikit-learn хранятся в подпапках ‘~/scikit_learn_data’.
- subset{‘train’, ‘test’, ‘all’}, по умолчанию=’train’
Выберите набор данных для загрузки: 'train' для обучающего набора, 'test' для тестового набора, 'all' для обоих, с перемешанным порядком.
- категорииarray-like, dtype=str, default=None
Если None (по умолчанию), загрузить все категории. Если не None, список имен категорий для загрузки (остальные категории игнорируются).
- перемешиваниеbool, по умолчанию=True
Перемешивать ли данные: может быть важно для моделей, которые предполагают, что образцы независимы и одинаково распределены (i.i.d.), например, стохастический градиентный спуск.
- random_stateint, экземпляр RandomState или None, по умолчанию=42
Определяет генерацию случайных чисел для перемешивания набора данных. Передайте целое число для воспроизводимого вывода при нескольких вызовах функции. См. Глоссарий.
- удалитьtuple, default=()
Может содержать любое подмножество ('headers', 'footers', 'quotes'). Каждый из них представляет собой вид текста, который будет обнаружен и удален из сообщений новостной группы, предотвращая переобучение классификаторов на метаданных.
‘headers’ удаляет заголовки групп новостей, ‘footers’ удаляет блоки в конце сообщений, которые выглядят как подписи, и ‘quotes’ удаляет строки, которые, по-видимому, цитируют другое сообщение.
Здесь мы обучаем две модели с разной максимальной глубиной
- download_if_missingbool, по умолчанию=True
Если False, вызывает OSError, если данные недоступны локально, вместо попытки загрузить их с исходного сайта.
- return_X_ybool, по умолчанию=False
Если True, возвращает
(data.data, data.target)вместо объекта Bunch.Добавлено в версии 0.22.
- n_retriesint, по умолчанию=3
Количество повторных попыток при возникновении HTTP-ошибок.
Добавлено в версии 1.5.
- задержкаfloat, по умолчанию=1.0
Количество секунд между повторными попытками.
Добавлено в версии 1.5.
- Возвращает:
- Нагрузки
Bunch Объект, подобный словарю, со следующими атрибутами.
- данныеlist of shape (n_samples,)
Список данных для обучения.
- target: ndarray формы (n_samples,)
Целевые метки.
- filenames: список формы (n_samples,)
Путь к местоположению данных.
- DESCR: str
Полное описание набора данных.
- target_names: список формы (n_classes,)
Имена целевых классов.
- (data, target)кортеж если
return_X_y=True Кортеж из двух ndarrays. Первый содержит двумерный массив формы (n_samples, n_classes), где каждая строка представляет один образец, а каждый столбец представляет признаки. Второй массив формы (n_samples,) содержит целевые образцы.
Добавлено в версии 0.22.
- Нагрузки
Примеры
>>> from sklearn.datasets import fetch_20newsgroups >>> cats = ['alt.atheism', 'sci.space'] >>> newsgroups_train = fetch_20newsgroups(subset='train', categories=cats) >>> list(newsgroups_train.target_names) ['alt.atheism', 'sci.space'] >>> newsgroups_train.filenames.shape (1073,) >>> newsgroups_train.target.shape (1073,) >>> newsgroups_train.target[:10] array([0, 1, 1, 1, 0, 1, 1, 0, 0, 0])
Примеры галереи#
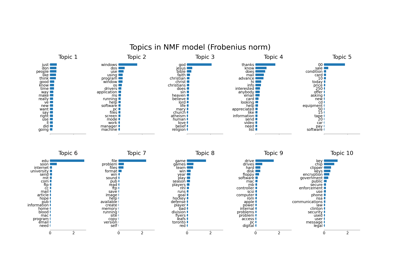

Бикластеризация документов с помощью алгоритма спектральной совместной кластеризации
Трансформер столбцов с разнородными источниками данных

Примерный пайплайн для извлечения и оценки текстовых признаков
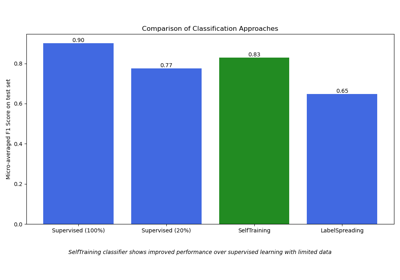
Полу-контролируемая классификация на текстовом наборе данных

Классификация текстовых документов с использованием разреженных признаков
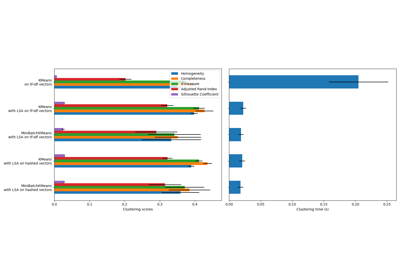
Кластеризация текстовых документов с использованием k-means
