fetch_california_housing#
- sklearn.datasets.fetch_california_housing(*, data_home=None, download_if_missing=True, return_X_y=False, as_frame=False, n_retries=3, задержка=1.0)[источник]#
Загрузить набор данных о жилье в Калифорнии (регрессия).
Всего образцов
20640
Снижение размерности
8
Признаки
вещественный
Целевая переменная
действительное 0.15 - 5.
Подробнее в Руководство пользователя.
- Параметры:
- data_homestr или path-like, по умолчанию=None
Укажите другую папку для загрузки и кэширования наборов данных. По умолчанию все данные scikit-learn хранятся в подпапках '~/scikit_learn_data'.
- download_if_missingbool, по умолчанию=True
Если False, вызывает OSError, если данные недоступны локально, вместо попытки загрузить их с исходного сайта.
- return_X_ybool, по умолчанию=False
Если True, возвращает
(data.data, data.target)вместо объекта Bunch.Добавлено в версии 0.20.
- as_framebool, по умолчанию=False
Если True, данные представляют собой pandas DataFrame, включающий столбцы с соответствующими типами данных (числовые, строковые или категориальные). Целевая переменная - это pandas DataFrame или Series в зависимости от количества target_columns.
Добавлено в версии 0.23.
- n_retriesint, по умолчанию=3
Количество повторных попыток при возникновении HTTP-ошибок.
Добавлено в версии 1.5.
- задержкаfloat, по умолчанию=1.0
Количество секунд между повторными попытками.
Добавлено в версии 1.5.
- Возвращает:
- набор данных
Bunch Объект, подобный словарю, со следующими атрибутами.
- данныеndarray, форма (20640, 8)
раз подряд. Улучшение оценивается с абсолютной погрешностью
as_frameравно True,dataявляется объектом pandas.- цельмассив numpy формы (20640,)
Каждое значение соответствует медианной стоимости дома в единицах 100,000. Если
as_frameравно True,targetявляется объектом pandas.- feature_namesсписок длиной 8
Массив упорядоченных названий признаков, используемых в наборе данных.
- DESCRstr
Описание набора данных о жилье в Калифорнии.
- фреймpandas DataFrame
Только присутствует, когда
as_frame=TrueМы определяем функцию для загрузки данных изdataиtarget.Добавлено в версии 0.23.
- (data, target)кортеж если
return_X_yравно True Кортеж из двух ndarray. Первый содержит двумерный массив формы (n_samples, n_features), где каждая строка представляет один образец, а каждый столбец — признаки. Второй ndarray формы (n_samples,) содержит целевые образцы.
Добавлено в версии 0.20.
- набор данных
Примечания
Этот набор данных состоит из 20 640 образцов и 9 признаков.
Примеры
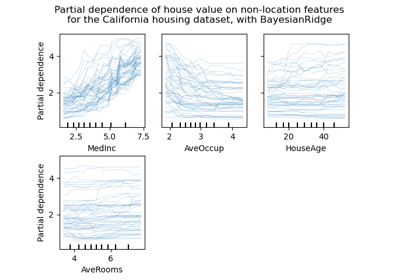
>>> from sklearn.datasets import fetch_california_housing >>> housing = fetch_california_housing() >>> print(housing.data.shape, housing.target.shape) (20640, 8) (20640,) >>> print(housing.feature_names[0:6]) ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup']
Примеры галереи#

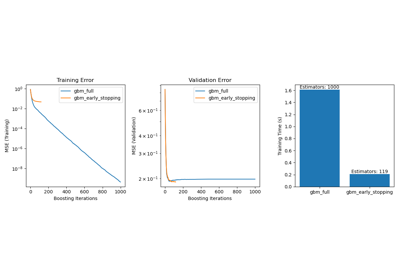
Сравнение моделей случайных лесов и градиентного бустинга на гистограммах
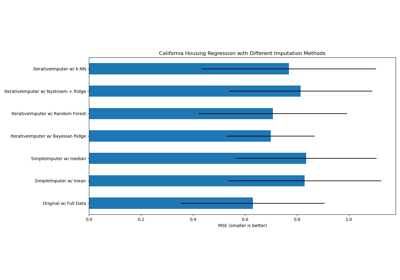
Заполнение пропущенных значений с вариантами IterativeImputer
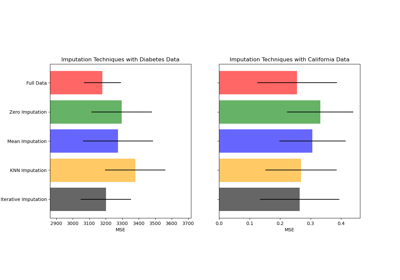
Заполнение пропущенных значений перед построением оценщика
Сравнение влияния различных масштабировщиков на данные с выбросами