TfidfTransformer#
- класс sklearn.feature_extraction.text.TfidfTransformer(*, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)[источник]#
Преобразовать матрицу частот в нормализованное представление tf или tf-idf.
Tf означает частоту термина, а tf-idf означает частоту термина, умноженную на обратную частоту документа. Это распространенная схема взвешивания терминов в информационном поиске, которая также хорошо зарекомендовала себя в классификации документов.
Цель использования tf-idf вместо сырых частот встречаемости токена в данном документе — уменьшить влияние токенов, которые встречаются очень часто в данном корпусе и, следовательно, эмпирически менее информативны, чем признаки, встречающиеся в небольшой части обучающего корпуса.
Формула, используемая для вычисления tf-idf для термина t документа d в наборе документов: tf-idf(t, d) = tf(t, d) * idf(t), где idf вычисляется как idf(t) = log [ n / df(t) ] + 1 (если
smooth_idf=False), где n - общее количество документов в наборе документов, а df(t) - частота документа t; частота документа - это количество документов в наборе, содержащих термин t. Эффект добавления "1" к idf в уравнении выше заключается в том, что термины с нулевым idf, т.е. термины, которые встречаются во всех документах обучающего набора, не будут полностью игнорироваться. (Обратите внимание, что формула idf выше отличается от стандартной учебной записи, которая определяет idf как idf(t) = log [ n / (df(t) + 1) ]).Если
smooth_idf=True(по умолчанию), константа "1" добавляется к числителю и знаменателю idf, как если бы был увиден дополнительный документ, содержащий каждый термин в коллекции ровно один раз, что предотвращает деление на ноль: idf(t) = log [ (1 + n) / (1 + df(t)) ] + 1.Кроме того, формулы, используемые для вычисления tf и idf, зависят от настроек параметров, которые соответствуют обозначению SMART, используемому в информационном поиске, следующим образом:
Tf по умолчанию "n" (натуральный), "l" (логарифмический), когда
sublinear_tf=True. Idf имеет значение "t", когда задан use_idf, и "n" (none) в противном случае. Нормализация имеет значение "c" (cosine), когдаnorm='l2', “n” (нет) когдаnorm=None.Подробнее в Руководство пользователя.
- Параметры:
- norm{‘l1’, ‘l2’} или None, по умолчанию=’l2’
Каждая строка вывода будет иметь единичную норму, либо:
'l2': Сумма квадратов элементов вектора равна 1. Косинусное сходство между двумя векторами — это их скалярное произведение, когда применена норма l2.
‘l1’: Сумма абсолютных значений элементов вектора равна 1. См.
normalize.None: Без нормализации.
- use_idfbool, по умолчанию=True
Включить перевзвешивание по обратной частоте документа. Если False, idf(t) = 1.
- smooth_idfbool, по умолчанию=True
Сглаживание idf-весов путём добавления единицы к частотам документов, как если бы дополнительный документ был просмотрен, содержащий каждый термин в коллекции ровно один раз. Предотвращает деление на ноль.
- sublinear_tfbool, по умолчанию=False
Применить сублинейное масштабирование tf, т.е. заменить tf на 1 + log(tf).
- Атрибуты:
- idf_массив формы (n_features)
Вектор обратной частоты документа (IDF); определен только если
use_idfравно True.Добавлено в версии 0.20.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 1.0.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
CountVectorizerПреобразует текст в разреженную матрицу подсчётов n-грамм.
TfidfVectorizerПреобразовать коллекцию необработанных документов в матрицу признаков TF-IDF.
HashingVectorizerПреобразовать коллекцию текстовых документов в матрицу встречаемости токенов.
Ссылки
[Yates2011]R. Baeza-Yates и B. Ribeiro-Neto (2011). Современный поиск информации. Addison Wesley, стр. 68-74.
[MRS2008]C.D. Manning, P. Raghavan и H. Schütze (2008). Введение в информационный поиск. Cambridge University Press, стр. 118-120.
Примеры
>>> from sklearn.feature_extraction.text import TfidfTransformer >>> from sklearn.feature_extraction.text import CountVectorizer >>> from sklearn.pipeline import Pipeline >>> corpus = ['this is the first document', ... 'this document is the second document', ... 'and this is the third one', ... 'is this the first document'] >>> vocabulary = ['this', 'document', 'first', 'is', 'second', 'the', ... 'and', 'one'] >>> pipe = Pipeline([('count', CountVectorizer(vocabulary=vocabulary)), ... ('tfid', TfidfTransformer())]).fit(corpus) >>> pipe['count'].transform(corpus).toarray() array([[1, 1, 1, 1, 0, 1, 0, 0], [1, 2, 0, 1, 1, 1, 0, 0], [1, 0, 0, 1, 0, 1, 1, 1], [1, 1, 1, 1, 0, 1, 0, 0]]) >>> pipe['tfid'].idf_ array([1. , 1.22314355, 1.51082562, 1. , 1.91629073, 1. , 1.91629073, 1.91629073]) >>> pipe.transform(corpus).shape (4, 8)
- fit(X, y=None)[источник]#
Изучить вектор idf (глобальные веса терминов).
- Параметры:
- Xразреженная матрица формы (n_samples, n_features)
Матрица подсчётов терминов/токенов.
- yNone
Этот параметр не нужен для вычисления tf-idf.
- Возвращает:
- selfobject
Обученный преобразователь.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
То же, что и входные признаки.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') TfidfTransformer[источник]#
Настроить, следует ли запрашивать передачу метаданных в
transformметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяtransformесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вtransform.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вtransform.
- Возвращает:
- selfobject
Обновленный объект.
- преобразовать(X, copy=True)[источник]#
Преобразовать матрицу частот в представление tf или tf-idf.
- Параметры:
- Xразреженная матрица (n_samples, n_features)
Матрица подсчётов терминов/токенов.
- copybool, по умолчанию=True
Копировать ли X и работать с копией или выполнять операции на месте.
copy=Falseбудет эффективен только с разреженной матрицей CSR.
- Возвращает:
- векторыразреженная матрица формы (n_samples, n_features)
Tf-idf-взвешенная матрица документ-термин.
Примеры галереи#
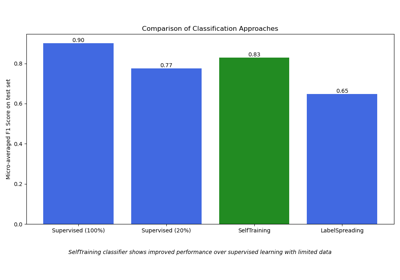
Полу-контролируемая классификация на текстовом наборе данных
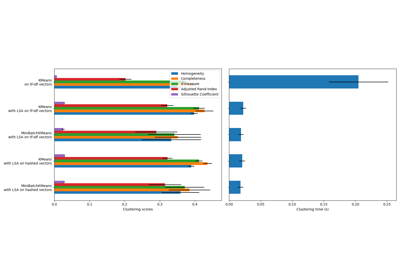
Кластеризация текстовых документов с использованием k-means
