fetch_20newsgroups_vectorized#
- sklearn.datasets.fetch_20newsgroups_vectorized(*, subset='train', удалить=(), data_home=None, download_if_missing=True, return_X_y=False, нормализовать=True, as_frame=False, n_retries=3, задержка=1.0)[источник]#
Загрузить и векторизовать набор данных 20 newsgroups (классификация).
Загружает его, если необходимо.
Это удобная функция; преобразование выполняется с использованием настроек по умолчанию для
CountVectorizer. Для более продвинутого использования (фильтрация стоп-слов, извлечение n-грамм и т.д.) объедините fetch_20newsgroups с пользовательскимCountVectorizer,HashingVectorizer,TfidfTransformerилиTfidfVectorizer.Полученные количества нормализуются с использованием
sklearn.preprocessing.normalizeесли normalize не установлено в False.Классы
20
Всего образцов
18846
Снижение размерности
130107
Признаки
вещественный
Подробнее в Руководство пользователя.
- Параметры:
- subset{‘train’, ‘test’, ‘all’}, по умолчанию=’train’
Выберите набор данных для загрузки: 'train' для обучающего набора, 'test' для тестового набора, 'all' для обоих, с перемешанным порядком.
- удалитьtuple, default=()
Может содержать любое подмножество ('headers', 'footers', 'quotes'). Каждый из них представляет собой вид текста, который будет обнаружен и удален из сообщений новостной группы, предотвращая переобучение классификаторов на метаданных.
‘headers’ удаляет заголовки групп новостей, ‘footers’ удаляет блоки в конце сообщений, которые выглядят как подписи, и ‘quotes’ удаляет строки, которые, по-видимому, цитируют другое сообщение.
- data_homestr или path-like, по умолчанию=None
Укажите папку для загрузки и кэширования наборов данных. Если None, все данные scikit-learn хранятся в подпапках ‘~/scikit_learn_data’.
- download_if_missingbool, по умолчанию=True
Если False, вызывает OSError, если данные недоступны локально, вместо попытки загрузить их с исходного сайта.
- return_X_ybool, по умолчанию=False
Если True, возвращает
(data.data, data.target)вместо объекта Bunch.Добавлено в версии 0.20.
- нормализоватьbool, по умолчанию=True
Если True, нормализует вектор признаков каждого документа до единичной нормы с использованием
sklearn.preprocessing.normalize.Добавлено в версии 0.22.
- as_framebool, по умолчанию=False
Если True, данные - это pandas DataFrame, включающий столбцы с соответствующими типами данных (числовые, строковые или категориальные). Целевая переменная - это pandas DataFrame или Series в зависимости от количества
target_columns.Добавлено в версии 0.24.
- n_retriesint, по умолчанию=3
Количество повторных попыток при возникновении HTTP-ошибок.
Добавлено в версии 1.5.
- задержкаfloat, по умолчанию=1.0
Количество секунд между повторными попытками.
Добавлено в версии 1.5.
- Возвращает:
- Нагрузки
Bunch Объект, подобный словарю, со следующими атрибутами.
- данные: {разреженная матрица, датафрейм} формы (n_samples, n_features)
Входная матрица данных. Если
as_frameявляетсяTrue,dataявляется pandas DataFrame с разреженными столбцами.- целевая переменная: {ndarray, series} формы (n_samples,)
Целевые метки. Если
as_frameявляетсяTrue,targetявляется pandas Series.- target_names: список формы (n_classes,)
Имена целевых классов.
- DESCR: str
Полное описание набора данных.
- frame: dataframe формы (n_samples, n_features + 1)
Только присутствует, когда
as_frame=True. Pandas DataFrame сdataиtarget.Добавлено в версии 0.24.
- (data, target)кортеж если
return_X_yравно True dataиtargetбудет иметь формат, определенный вBunchописание выше.Добавлено в версии 0.20.
- Нагрузки
Примеры
>>> from sklearn.datasets import fetch_20newsgroups_vectorized >>> newsgroups_vectorized = fetch_20newsgroups_vectorized(subset='test') >>> newsgroups_vectorized.data.shape (7532, 130107) >>> newsgroups_vectorized.target.shape (7532,)
Примеры галереи#

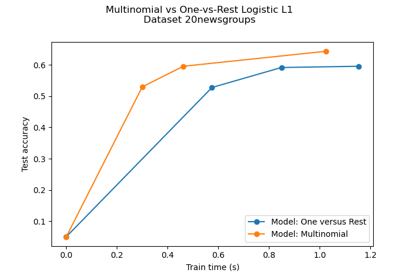
Многоклассовая разреженная логистическая регрессия на 20newsgroups
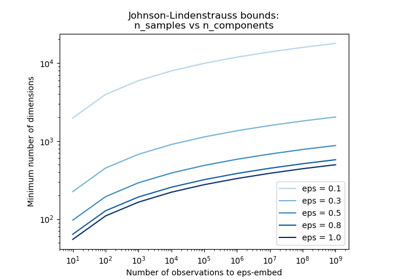
Граница Джонсона-Линденштрауса для вложения с помощью случайных проекций