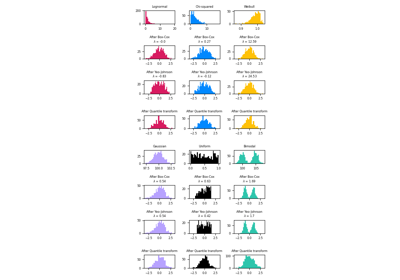
QuantileTransformer#
- класс sklearn.preprocessing.QuantileTransformer(*, n_quantiles=1000, output_distribution='uniform', ignore_implicit_zeros=False, subsample=10000, random_state=None, copy=True)[источник]#
Преобразование признаков с использованием информации о квантилях.
Этот метод преобразует признаки для следования равномерному или нормальному распределению. Поэтому для данного признака это преобразование стремится распределить наиболее частые значения. Оно также уменьшает влияние (маргинальных) выбросов: это, следовательно, устойчивая схема предобработки.
Преобразование применяется к каждому признаку независимо. Сначала оценка функции распределения признака используется для отображения исходных значений в равномерное распределение. Затем полученные значения отображаются в желаемое выходное распределение с использованием соответствующей функции квантилей. Значения признаков новых/невидимых данных, которые находятся ниже или выше подобранного диапазона, будут отображены в границы выходного распределения. Обратите внимание, что это преобразование нелинейно. Оно может искажать линейные корреляции между переменными, измеренными в одной шкале, но делает переменные, измеренные в разных шкалах, более непосредственно сравнимыми.
Примеры визуализаций см. в Сравнение QuantileTransformer с другими масштабаторами.
Подробнее в Руководство пользователя.
Добавлено в версии 0.19.
- Параметры:
- n_quantilesint, по умолчанию=1000 или n_samples
Количество квантилей для вычисления. Соответствует количеству контрольных точек, используемых для дискретизации функции кумулятивного распределения. Если n_quantiles больше количества образцов, n_quantiles устанавливается равным количеству образцов, так как большее количество квантилей не дает лучшего приближения оценки функции кумулятивного распределения.
- output_distribution{‘uniform’, ‘normal’}, по умолчанию=’uniform’
Маргинальное распределение для преобразованных данных. Варианты: 'uniform' (по умолчанию) или 'normal'.
- ignore_implicit_zerosbool, по умолчанию=False
Применяется только к разреженным матрицам. Если True, разреженные элементы матрицы отбрасываются для вычисления статистик квантилей. Если False, эти элементы обрабатываются как нули.
- subsampleint или None, по умолчанию 10_000
Максимальное количество образцов, используемых для оценки квантилей для вычислительной эффективности. Обратите внимание, что процедура подвыборки может отличаться для разреженных и плотных матриц с одинаковыми значениями. Отключите подвыборку, установив
subsample=None.Добавлено в версии 1.5: Опция
Noneдля отключения субдискретизации был добавлен.- random_stateint, экземпляр RandomState или None, по умолчанию=None
Определяет генерацию случайных чисел для субдискретизации и сглаживания шума. Пожалуйста, смотрите
subsampleдля получения дополнительных деталей. Передайте int для воспроизводимых результатов при множественных вызовах функции. См. Глоссарий.- copybool, по умолчанию=True
Установите значение False для выполнения преобразования на месте и избежания копирования (если входные данные уже являются массивом numpy).
- Атрибуты:
- n_quantiles_int
Фактическое количество квантилей, используемых для дискретизации кумулятивной функции распределения.
- quantiles_ndarray формы (n_quantiles, n_features)
Значения, соответствующие квантилям референса.
- references_ndarray формы (n_quantiles, )
Квантили референсов.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
quantile_transformкоммуникация вокруг scikit-learn
PowerTransformerВыполните отображение на нормальное распределение с использованием степенного преобразования.
StandardScalerВыполнить стандартизацию, которая быстрее, но менее устойчива к выбросам.
RobustScalerВыполните устойчивую стандартизацию, которая удаляет влияние выбросов, но не ставит выбросы и нормальные значения в один масштаб.
Примечания
NaN обрабатываются как пропущенные значения: игнорируются при обучении и сохраняются при преобразовании.
Примеры
>>> import numpy as np >>> from sklearn.preprocessing import QuantileTransformer >>> rng = np.random.RandomState(0) >>> X = np.sort(rng.normal(loc=0.5, scale=0.25, size=(25, 1)), axis=0) >>> qt = QuantileTransformer(n_quantiles=10, random_state=0) >>> qt.fit_transform(X) array([...])
- fit(X, y=None)[источник]#
Вычислить квантили, используемые для преобразования.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для масштабирования по оси признаков. Если предоставлена разреженная матрица, она будет преобразована в разреженную
csc_matrix. Кроме того, разреженная матрица должна быть неотрицательной, еслиignore_implicit_zerosравно False.- yNone
Игнорируется.
- Возвращает:
- selfobject
Обученный преобразователь.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
То же, что и входные признаки.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Обратная проекция в исходное пространство.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для масштабирования по оси признаков. Если предоставлена разреженная матрица, она будет преобразована в разреженную
csc_matrix. Кроме того, разреженная матрица должна быть неотрицательной, еслиignore_implicit_zerosравно False.
- Возвращает:
- X_original{ndarray, разреженная матрица} размерности (n_samples, n_features)
Спроецированные данные.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Поэлементное преобразование данных.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для масштабирования по оси признаков. Если предоставлена разреженная матрица, она будет преобразована в разреженную
csc_matrix. Кроме того, разреженная матрица должна быть неотрицательной, еслиignore_implicit_zerosравно False.
- Возвращает:
- Xt{ndarray, разреженная матрица} формы (n_samples, n_features)
Спроецированные данные.
Примеры галереи#
Эффект преобразования целей в регрессионной модели
Графики частичной зависимости и индивидуального условного ожидания
Сравнение влияния различных масштабировщиков на данные с выбросами