FeatureAgglomeration#
-
класс sklearn.cluster.FeatureAgglomeration(n_clusters=2, *, metric='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', pooling_func=
Агломерировать признаки.
Рекурсивно объединяет пары кластеров признаков.
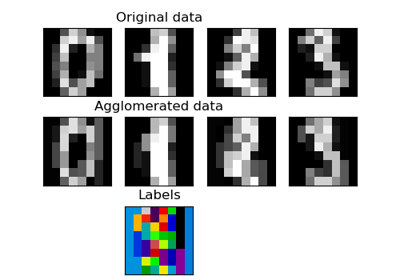
См. Агломерация признаков против одномерного отбора для примера сравнения
FeatureAgglomerationстратегия с одномерной стратегией выбора признаков (на основе ANOVA).Подробнее в Руководство пользователя.
- Параметры:
- n_clustersint или None, по умолчанию=2
Количество кластеров для поиска. Оно должно быть
Noneifdistance_thresholdне являетсяNone.- метрикаstr или callable, по умолчанию="euclidean"
Метрика, используемая для вычисления связи. Может быть "euclidean", "l1", "l2", "manhattan", "cosine" или "precomputed". Если связь "ward", принимается только "euclidean". Если "precomputed", требуется матрица расстояний в качестве входных данных для метода fit.
Добавлено в версии 1.2.
- памятьstr или объект с интерфейсом joblib.Memory, по умолчанию=None
Используется для кэширования результатов вычисления дерева. По умолчанию кэширование не выполняется. Если указана строка, это путь к директории кэширования.
- связностьarray-like, sparse matrix, или callable, по умолчанию=None
Матрица связности. Определяет для каждого признака соседние признаки в соответствии с заданной структурой данных. Это может быть сама матрица связности или вызываемый объект, который преобразует данные в матрицу связности, например, полученную из
kneighbors_graph. По умолчаниюNone, т.е., алгоритм иерархической кластеризации неструктурирован.- compute_full_tree‘auto’ или bool, по умолчанию=’auto’
Остановить раннее построение дерева на
n_clusters. Это полезно для уменьшения времени вычислений, если количество кластеров не мало по сравнению с количеством признаков. Эта опция полезна только при указании матрицы связности. Также обратите внимание, что при изменении количества кластеров и использовании кэширования может быть выгодно вычислить полное дерево. Оно должно бытьTrueifdistance_thresholdне являетсяNone. По умолчаниюcompute_full_treeравно “auto”, что эквивалентноTrueкогдаdistance_thresholdне являетсяNoneили чтоn_clustersхуже максимума между 100 или0.02 * n_samples. В противном случае, “auto” эквивалентноFalse.- linkage{“ward”, “complete”, “average”, “single”}, по умолчанию=”ward”
Какой критерий связи использовать. Критерий связи определяет, какое расстояние использовать между наборами признаков. Алгоритм будет объединять пары кластеров, которые минимизируют этот критерий.
"ward" минимизирует дисперсию объединяемых кластеров.
“complete” или максимальная связь использует максимальные расстояния между всеми признаками двух наборов.
“average” использует среднее расстояний каждого признака двух наборов.
“single” использует минимум расстояний между всеми признаками двух наборов.
- pooling_funcвызываемый объект, по умолчанию=np.mean
Это объединяет значения объединенных признаков в одно значение и должно принимать массив формы [M, N] и ключевой аргумент
axis=1и сводит его к массиву размера [M].- distance_thresholdfloat, по умолчанию=None
Пороговое значение расстояния связи, при котором или выше которого кластеры не будут объединяться. Если не
None,n_clustersдолжен бытьNoneиcompute_full_treeдолжен бытьTrue.Добавлено в версии 0.21.
- compute_distancesbool, по умолчанию=False
Вычисляет расстояния между кластерами, даже если
distance_thresholdне используется. Это может быть использовано для визуализации дендрограммы, но влечет за собой вычислительные и ресурсные затраты.Добавлено в версии 0.24.
- Атрибуты:
- n_clusters_int
Количество кластеров, найденных алгоритмом. Если
distance_threshold=None, он будет равен заданномуn_clusters.- labels_array-like формы (n_features,)
Метки кластеров для каждого признака.
- n_leaves_int
Количество листьев в иерархическом дереве.
- n_connected_components_int
Оценочное количество связных компонент в графе.
Добавлено в версии 0.21:
n_connected_components_был добавлен для заменыn_components_.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- children_array-like формы (n_nodes-1, 2)
Дочерние элементы каждого нелистового узла. Значения меньше
n_featuresсоответствуют листьям дерева, которые являются исходными образцами. Узелiбольше или равноn_featuresявляется нелистовым узлом и имеет дочерние узлыchildren_[i - n_features]. Альтернативно, на i-й итерации children[i][0] и children[i][1] объединяются, чтобы сформировать узелn_features + i.- distances_массивоподобный формы (n_nodes-1,)
Расстояния между узлами в соответствующем месте в
children_. Вычисляется только еслиdistance_thresholdиспользуется илиcompute_distancesустановлено вTrue.
Смотрите также
AgglomerativeClusteringАгломеративная кластеризация образцов вместо признаков.
ward_treeИерархическая кластеризация с методом связывания Уорда.
Примеры
>>> import numpy as np >>> from sklearn import datasets, cluster >>> digits = datasets.load_digits() >>> images = digits.images >>> X = np.reshape(images, (len(images), -1)) >>> agglo = cluster.FeatureAgglomeration(n_clusters=32) >>> agglo.fit(X) FeatureAgglomeration(n_clusters=32) >>> X_reduced = agglo.transform(X) >>> X_reduced.shape (1797, 32)
- fit(X, y=None)[источник]#
Обучить иерархическую кластеризацию на данных.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает преобразователь.
- свойство fit_predict#
Обучить и вернуть результат кластеризации для каждого образца.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Инвертировать преобразование и вернуть вектор размера
n_features.- Параметры:
- Xarray-like формы (n_samples, n_clusters) или (n_clusters,)
Значения, которые будут присвоены каждому кластеру образцов.
- Возвращает:
- X_originalndarray формы (n_samples, n_features) или (n_features,)
Вектор размера
n_samplesсо значениямиXназначен каждому кластеру образцов.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать новую матрицу с использованием построенной кластеризации.
- Параметры:
- Xмассивоподобный объект формы (n_samples, n_features) или (n_samples, n_samples)
Массив размером M на N, содержащий M наблюдений в N измерениях, или массив длины M, содержащий M одномерных наблюдений.
- Возвращает:
- Yndarray формы (n_samples, n_clusters) или (n_clusters,)
Объединенные значения для каждого кластера признаков.