IterativeImputer#
- класс sklearn.impute.IterativeImputer(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', fill_value=None, imputation_order='ascending', skip_complete=False, min_value=-inf, max_value=inf, verbose=0, random_state=None, add_indicator=False, keep_empty_features=False)[источник]#
Многомерный импутер, который оценивает каждый признак по всем остальным.
Стратегия заполнения пропущенных значений путем моделирования каждого признака с пропусками как функции других признаков в циклическом порядке.
Подробнее в Руководство пользователя.
Добавлено в версии 0.21.
Примечание
Этот оценщик все еще экспериментальный на данный момент: предсказания и API могут измениться без какого-либо цикла устаревания. Чтобы использовать его, вам нужно явно импортировать
enable_iterative_imputer:>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_iterative_imputer # noqa >>> # now you can import normally from sklearn.impute >>> from sklearn.impute import IterativeImputer
- Параметры:
- estimatorобъект оценщика, по умолчанию=BayesianRidge()
Оценщик, используемый на каждом шаге циклического импутирования. Если
sample_posterior=True, оценщик должен поддерживатьreturn_stdв егоpredictметод.- missing_valuesint или np.nan, по умолчанию=np.nan
Заполнитель для пропущенных значений. Все вхождения
missing_valuesбудут импутированы. Для датафреймов pandas с нуллабельными целочисленными типами данных с пропущенными значениями,missing_valuesдолжно быть установлено вnp.nan, посколькуpd.NAбудет преобразовано вnp.nan.- sample_posteriorbool, по умолчанию=False
Следует ли выполнять выборку из (гауссовского) прогностического апостериорного распределения обученного оценщика для каждой импутации. Оценщик должен поддерживать
return_stdв егоpredictметод, если установлен вTrue. Установите вTrueесли используетсяIterativeImputerдля множественных импутаций.- max_iterint, по умолчанию=10
Максимальное количество раундов импутации для выполнения перед возвратом импутаций, вычисленных в последнем раунде. Раунд — это единичная импутация каждого признака с пропущенными значениями. Критерий остановки достигается, когда
max(abs(X_t - X_{t-1}))/max(abs(X[known_vals])) < tol, гдеX_tявляетсяXна итерацииt. Обратите внимание, что ранняя остановка применяется только еслиsample_posterior=False.- tolfloat, по умолчанию=1e-3
Допуск условия остановки.
- n_nearest_featuresint, default=None
Количество других признаков, используемых для оценки пропущенных значений каждого столбца признаков. Близость между признаками измеряется с использованием абсолютного коэффициента корреляции между каждой парой признаков (после начального заполнения). Чтобы обеспечить охват признаков в процессе заполнения, соседние признаки не обязательно являются ближайшими, а выбираются с вероятностью, пропорциональной корреляции для каждого целевого заполняемого признака. Может обеспечить значительное ускорение, когда количество признаков огромно. Если
None, будут использоваться все признаки.- initial_strategy{‘mean’, ‘median’, ‘most_frequent’, ‘constant’}, по умолчанию=’mean’
Какую стратегию использовать для инициализации пропущенных значений. То же, что и
strategyпараметр вSimpleImputer.- fill_valuestr или числовое значение, по умолчанию=None
Когда
strategy="constant",fill_valueиспользуется для замены всех вхождений missing_values. Для строковых или объектных типов данных,fill_valueдолжен быть строкой. ЕслиNone,fill_valueбудет 0 при импутации числовых данных и «missing_value» для строковых или объектных типов данных.Добавлено в версии 1.3.
- imputation_order{‘ascending’, ‘descending’, ‘roman’, ‘arabic’, ‘random’}, по умолчанию=’ascending’
Порядок, в котором признаки будут импутированы. Возможные значения:
'ascending': От признаков с наименьшим количеством пропущенных значений к наибольшему.'descending': От признаков с наибольшим количеством пропущенных значений к наименьшему.'roman': Слева направо.'arabic': Справа налево.'random': Случайный порядок для каждого раунда.
- skip_completebool, по умолчанию=False
Если
Trueтогда признаки с пропущенными значениями во времяtransformкоторые не имели пропущенных значений во времяfitбудут заполнены только начальным методом импутации. Установите вTrueесли у вас много признаков без пропущенных значений в обоихfitиtransformвремя для экономии вычислений.- min_valuefloat или array-like формы (n_features,), по умолчанию=-np.inf
Минимально возможное импутированное значение. Транслируется к форме
(n_features,)если скаляр. Если array-like, ожидается форма(n_features,), одно минимальное значение для каждого признака. По умолчанию-np.inf.Изменено в версии 0.23: Добавлена поддержка массивоподобных объектов.
- max_valuefloat или array-like формы (n_features,), по умолчанию=np.inf
Максимально возможное импутированное значение. Транслируется в форму
(n_features,)если скаляр. Если array-like, ожидается форма(n_features,), одно максимальное значение для каждого признака. По умолчаниюnp.inf.Изменено в версии 0.23: Добавлена поддержка массивоподобных объектов.
- verboseint, по умолчанию=0
Флаг подробности вывода, управляет отладочными сообщениями, которые выдаются при вычислении функций. Чем выше, тем подробнее. Может быть 0, 1, или 2.
- random_stateint, экземпляр RandomState или None, по умолчанию=None
Сид псевдослучайного генератора чисел для использования. Рандомизирует выбор признаков оценщика, если
n_nearest_featuresне являетсяNone,imputation_orderifrandom, и выборку из апостериорного распределения, еслиsample_posterior=True. Используйте целое число для детерминированности. См. Глоссарий.- add_indicatorbool, по умолчанию=False
Если
True, aMissingIndicatortransform будет добавляться к выходу transform импутера. Это позволяет прогнозному оценщику учитывать пропуски, несмотря на импутацию. Если признак не имеет пропущенных значений во время обучения, признак не появится в индикаторе пропусков, даже если есть пропущенные значения во время transform/тестирования.- keep_empty_featuresbool, по умолчанию=False
Если True, признаки, которые состоят исключительно из пропущенных значений, когда
fitвызывается, возвращаются в результатах, когдаtransformвызывается. Импутированное значение всегда0кроме случаев, когдаinitial_strategy="constant"в этом случаеfill_valueбудет использоваться вместо.Добавлено в версии 1.2.
- Атрибуты:
- initial_imputer_объект типа
SimpleImputer Imputer, используемый для инициализации пропущенных значений.
- imputation_sequence_список кортежей
Каждый кортеж имеет
(feat_idx, neighbor_feat_idx, estimator), гдеfeat_idxявляется текущим признаком для заполнения,neighbor_feat_idxэто массив других признаков, используемых для импутации текущего признака, иestimatorэто обученный оценщик, используемый для заполнения пропусков. Длина равнаself.n_features_with_missing_ * self.n_iter_.- n_iter_int
Количество итерационных раундов, которые произошли. Будет меньше, чем
self.max_iterесли критерий ранней остановки был достигнут.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_features_with_missing_int
Количество признаков с пропущенными значениями.
- indicator_
MissingIndicator Индикатор, используемый для добавления бинарных индикаторов пропущенных значений.
Noneifadd_indicator=False.- random_state_экземпляр RandomState
экземпляр RandomState, который генерируется либо из сида, генератора случайных чисел, либо с помощью
np.random.
- initial_imputer_объект типа
Смотрите также
SimpleImputerОдномерный импутер для заполнения пропущенных значений простыми стратегиями.
KNNImputerМногомерный импутер, который оценивает отсутствующие признаки с использованием ближайших образцов.
Примечания
Для поддержки импутации в индуктивном режиме мы сохраняем оценщик каждого признака во время
fitфаза, и предсказывать без повторного обучения (по порядку) во времяtransformфаза.Признаки, которые содержат все пропущенные значения в
fitотбрасываются приtransform.Используя значения по умолчанию, импутер масштабируется в \(\mathcal{O}(knp^3\min(n,p))\) где \(k\) =
max_iter, \(n\) количество образцов и \(p\) количество признаков. Это становится непомерно дорогим, когда количество признаков увеличивается. Установкаn_nearest_features << n_features,skip_complete=Trueили увеличиваяtolможет помочь снизить его вычислительную стоимость.В зависимости от природы пропущенных значений, простые импутеры могут быть предпочтительнее в контексте прогнозирования.
Ссылки
Примеры
>>> import numpy as np >>> from sklearn.experimental import enable_iterative_imputer >>> from sklearn.impute import IterativeImputer >>> imp_mean = IterativeImputer(random_state=0) >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) IterativeImputer(random_state=0) >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> imp_mean.transform(X) array([[ 6.9584, 2. , 3. ], [ 4. , 2.6000, 6. ], [10. , 4.9999, 9. ]])
Более подробный пример см. в Заполнение пропущенных значений перед построением оценщика или Заполнение пропущенных значений с вариантами IterativeImputer.
- fit(X, y=None, **fit_params)[источник]#
Обучить импутер на
Xи возвращает self.- Параметры:
- Xarray-like, shape (n_samples, n_features)
Входные данные, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **fit_paramsdict
Параметры, перенаправленные в
fitметод суб-оценщика через API маршрутизации метаданных.Добавлено в версии 1.5: Доступно только если
sklearn.set_config(enable_metadata_routing=True)установлено. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_transform(X, y=None, **params)[источник]#
Обучить импутер на
Xи возвращает преобразованныеX.- Параметры:
- Xarray-like, shape (n_samples, n_features)
Входные данные, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **paramsdict
Параметры, перенаправленные в
fitметод суб-оценщика через API маршрутизации метаданных.Добавлено в версии 1.5: Доступно только если
sklearn.set_config(enable_metadata_routing=True)установлено. См. Руководство по маршрутизации метаданных для получения дополнительной информации.
- Возвращает:
- Xtarray-like, shape (n_samples, n_features)
Импутированные входные данные.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
Добавлено в версии 1.5.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Заполнить все пропущенные значения в
X.Обратите внимание, что это стохастично, и что если
random_stateне фиксирован, повторные вызовы или перестановка входных данных приведут к различным результатам.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные данные для завершения.
- Возвращает:
- Xtarray-like, shape (n_samples, n_features)
Импутированные входные данные.
Примеры галереи#
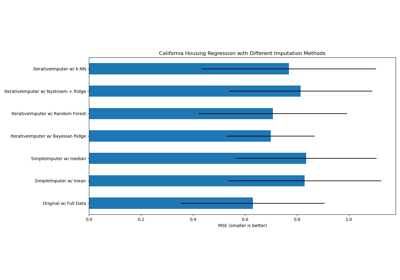
Заполнение пропущенных значений с вариантами IterativeImputer
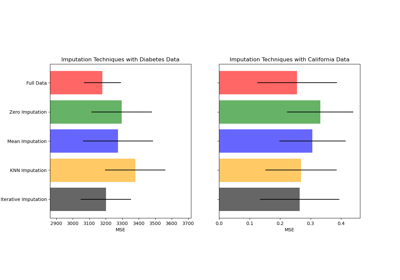
Заполнение пропущенных значений перед построением оценщика