MeanShift#
- класс sklearn.cluster.MeanShift(*, bandwidth=None, семена=None, bin_seeding=False, min_bin_freq=1, cluster_all=True, n_jobs=None, max_iter=300)[источник]#
Кластеризация методом сдвига среднего с использованием плоского ядра.
Кластеризация Mean Shift стремится обнаружить "сгустки" в плавной плотности образцов. Это алгоритм на основе центроидов, который работает путем обновления кандидатов в центроиды как среднее значение точек в заданной области. Затем эти кандидаты фильтруются на этапе постобработки для устранения почти дубликатов и формирования окончательного набора центроидов.
Инициализация выполняется с использованием техники бининга для масштабируемости.
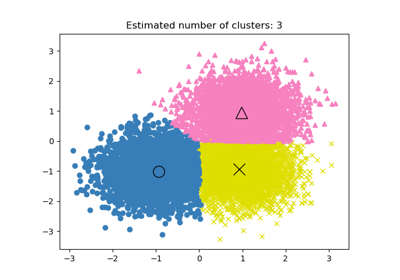
Пример использования кластеризации MeanShift см. в: Демонстрация алгоритма кластеризации mean-shift.
Подробнее в Руководство пользователя.
- Параметры:
- bandwidthfloat, по умолчанию=None
Ширина полосы, используемая в плоском ядре.
Если не задано, ширина полосы оценивается с помощью sklearn.cluster.estimate_bandwidth; см. документацию этой функции для подсказок по масштабируемости (см. также примечания ниже).
- семенамассивоподобный объект формы (n_samples, n_features), по умолчанию=None
Семена, используемые для инициализации ядер. Если не заданы, семена вычисляются с помощью clustering.get_bin_seeds с bandwidth в качестве размера сетки и значениями по умолчанию для других параметров.
- bin_seedingbool, по умолчанию=False
Если True, начальные положения ядер — это не положения всех точек, а скорее положения дискретизированной версии точек, где точки группируются в сетку, чья грубость соответствует ширине полосы. Установка этой опции в True ускорит алгоритм, потому что будет инициализировано меньше начальных точек. Значение по умолчанию — False. Игнорируется, если аргумент seeds не None.
- min_bin_freqint, по умолчанию=1
Чтобы ускорить алгоритм, принимайте только те бины с как минимум min_bin_freq точек в качестве семян.
- cluster_allbool, по умолчанию=True
Если True, то все точки кластеризуются, включая сиротские точки, которые не находятся внутри какого-либо ядра. Сиротские точки назначаются ближайшему ядру. Если False, то сиротским точкам присваивается метка кластера -1.
- n_jobsint, default=None
Количество заданий для вычислений. Следующие задачи выигрывают от распараллеливания:
Поиск ближайших соседей для оценки ширины полосы и назначения меток. См. подробности в строке документации
NearestNeighborsкласс.Оптимизация методом восхождения на холм для всех начальных значений.
См. Глоссарий для получения дополнительной информации.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- max_iterint, по умолчанию=300
Максимальное количество итераций на точку начального приближения до завершения операции кластеризации (для этой точки), если она еще не сошлась.
Добавлено в версии 0.22.
- Атрибуты:
- cluster_centers_ndarray формы (n_clusters, n_features)
Координаты центров кластеров.
- labels_ndarray формы (n_samples,)
Метки каждой точки.
- n_iter_int
Максимальное количество итераций, выполняемых для каждого начального значения.
Добавлено в версии 0.22.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
KMeansКластеризация K-Means.
Примечания
Масштабируемость:
Поскольку эта реализация использует плоское ядро и Ball Tree для поиска членов каждого ядра, сложность будет стремиться к O(T*n*log(n)) в низких размерностях, где n — количество образцов, а T — количество точек. В высоких размерностях сложность будет стремиться к O(T*n^2).
Масштабируемость может быть повышена за счет использования меньшего количества семян, например, путем использования большего значения min_bin_freq в функции get_bin_seeds.
Обратите внимание, что функция estimate_bandwidth гораздо менее масштабируема, чем алгоритм mean shift, и станет узким местом, если используется.
Ссылки
Dorin Comaniciu and Peter Meer, “Mean Shift: A robust approach toward feature space analysis”. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. pp. 603-619.
Примеры
>>> from sklearn.cluster import MeanShift >>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [1, 0], ... [4, 7], [3, 5], [3, 6]]) >>> clustering = MeanShift(bandwidth=2).fit(X) >>> clustering.labels_ array([1, 1, 1, 0, 0, 0]) >>> clustering.predict([[0, 0], [5, 5]]) array([1, 0]) >>> clustering MeanShift(bandwidth=2)
Для сравнения кластеризации Mean Shift с другими алгоритмами кластеризации, см. Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
- fit(X, y=None)[источник]#
Выполнить кластеризацию.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Образцы для кластеризации.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Обученный экземпляр.
- fit_predict(X, y=None, **kwargs)[источник]#
Выполнить кластеризацию на
Xи возвращает метки кластеров.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные данные.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- **kwargsdict
Аргументы, передаваемые в
fit.Добавлено в версии 1.4.
- Возвращает:
- меткиndarray формы (n_samples,), dtype=np.int64
Метки кластеров.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказывает ближайший кластер, к которому принадлежит каждый образец в X.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Новые данные для предсказания.
- Возвращает:
- меткиndarray формы (n_samples,)
Индекс кластера, к которому принадлежит каждый образец.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
Примеры галереи#
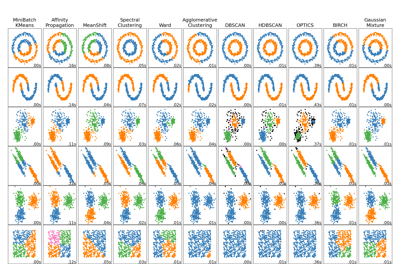
Сравнение различных алгоритмов кластеризации на игрушечных наборах данных