PolynomialFeatures#
- класс sklearn.preprocessing.PolynomialFeatures(степень=2, *, interaction_only=False, include_bias=True, порядок='C')[источник]#
Генерирует полиномиальные и интерактивные признаки.
Создает новую матрицу признаков, состоящую из всех полиномиальных комбинаций признаков со степенью меньше или равной указанной. Например, если входной образец двумерный и имеет вид [a, b], то полиномиальные признаки степени 2 будут [1, a, b, a^2, ab, b^2].
Подробнее в Руководство пользователя.
- Параметры:
- степеньint или кортеж (min_degree, max_degree), по умолчанию=2
Если задано одно целое число, оно определяет максимальную степень полиномиальных признаков. Если задан кортеж
(min_degree, max_degree)передается, тогдаmin_degreeявляется минимальным иmax_degreeявляется максимальной степенью полинома генерируемых признаков. Обратите внимание, чтоmin_degree=0иmin_degree=1эквивалентны, так как вывод члена нулевой степени определяетсяinclude_bias.- interaction_onlybool, по умолчанию=False
Если
True, создаются только признаки взаимодействия: признаки, которые являются произведениями не более чемdegreeразличные входные признаки, т.е. члены со степенью 2 или выше одного и того же входного признака исключаются:включены:
x[0],x[1],x[0] * x[1], и т.д.исключены:
x[0] ** 2,x[0] ** 2 * x[1], и т.д.
- include_biasbool, по умолчанию=True
Если
True(по умолчанию), то включите столбец смещения, признак, в котором все полиномиальные степени равны нулю (т.е. столбец из единиц - действует как член перехвата в линейной модели).- порядок{‘C’, ‘F’}, по умолчанию ‘C’
Порядок выходного массива в плотном случае.
'F'порядок быстрее вычисляется, но может замедлить последующие оценщики.Добавлено в версии 0.21.
- Атрибуты:
powers_ndarray формы (n_output_features_,n_features_in_)Показатель степени для каждого из входов в выходе.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_output_features_int
Общее количество полиномиальных выходных признаков. Количество выходных признаков вычисляется путем перебора всех подходящих комбинаций входных признаков.
Смотрите также
SplineTransformerТрансформер, который генерирует одномерные B-сплайновые базисы для признаков.
Примечания
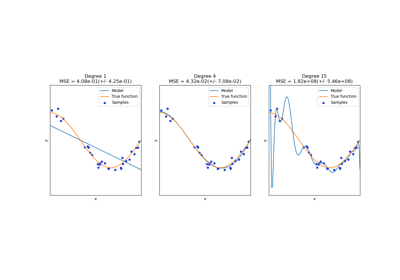
Учтите, что количество признаков в выходном массиве масштабируется полиномиально в зависимости от количества признаков во входном массиве и экспоненциально в зависимости от степени. Высокие степени могут привести к переобучению.
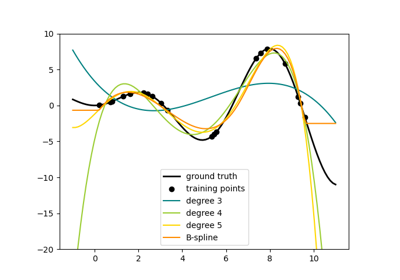
См. examples/linear_model/plot_polynomial_interpolation.py
Примеры
>>> import numpy as np >>> from sklearn.preprocessing import PolynomialFeatures >>> X = np.arange(6).reshape(3, 2) >>> X array([[0, 1], [2, 3], [4, 5]]) >>> poly = PolynomialFeatures(2) >>> poly.fit_transform(X) array([[ 1., 0., 1., 0., 0., 1.], [ 1., 2., 3., 4., 6., 9.], [ 1., 4., 5., 16., 20., 25.]]) >>> poly = PolynomialFeatures(interaction_only=True) >>> poly.fit_transform(X) array([[ 1., 0., 1., 0.], [ 1., 2., 3., 6.], [ 1., 4., 5., 20.]])
- fit(X, y=None)[источник]#
Вычислить количество выходных признаков.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные.
- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Обученный преобразователь.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_features is None, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Преобразовать данные в полиномиальные признаки.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные для преобразования, строка за строкой.
Предпочитайте CSR вместо CSC для разреженных входных данных (для скорости), но CSC требуется, если степень равна 4 или выше. Если степень меньше 4 и входной формат - CSC, он будет преобразован в CSR, затем сгенерированы полиномиальные признаки, а затем преобразованы обратно в CSC.
Если степень равна 2 или 3, используется метод, описанный в статье «Leveraging Sparsity to Speed Up Polynomial Feature Expansions of CSR Matrices Using K-Simplex Numbers» Эндрю Нистрома и Джона Хьюза, который значительно быстрее метода, используемого для CSC-входных данных. По этой причине CSC-входные данные будут преобразованы в CSR, а выходные данные будут преобразованы обратно в CSC перед возвратом, отсюда предпочтение CSR.
- Возвращает:
- XP{ndarray, разреженная матрица} формы (n_samples, NP)
Матрица признаков, где
NPэто количество полиномиальных признаков, сгенерированных из комбинации входных данных. Если предоставлена разреженная матрица, она будет преобразована в разреженнуюcsr_matrix.
Примеры галереи#

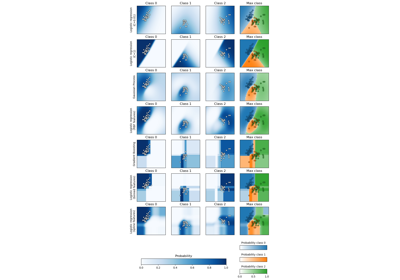
Визуализация вероятностных предсказаний VotingClassifier

Построение границ классификации с различными ядрами SVM