SimpleImputer#
- класс sklearn.impute.SimpleImputer(*, missing_values=nan, стратегия='mean', fill_value=None, copy=True, add_indicator=False, keep_empty_features=False)[источник]#
Одномерный импутер для заполнения пропущенных значений простыми стратегиями.
Заменить пропущенные значения с помощью описательной статистики (например, среднего, медианы или наиболее частого значения) вдоль каждого столбца или с использованием постоянного значения.
Подробнее в Руководство пользователя.
Добавлено в версии 0.20:
SimpleImputerзаменяет предыдущийsklearn.preprocessing.Imputerоценщик, который теперь удален.- Параметры:
- missing_valuesint, float, str, np.nan, None или pandas.NA, default=np.nan
Заполнитель для пропущенных значений. Все вхождения
missing_valuesбудут импутированы. Для датафреймов pandas с нуллабельными целочисленными типами данных с пропущенными значениями,missing_valuesможет быть установлен либоnp.nanилиpd.NA.- стратегияstr или Callable, по умолчанию='mean'
Стратегия импутации.
Если "mean", то заменяет пропущенные значения с использованием среднего значения по каждому столбцу. Может использоваться только с числовыми данными.
Если "median", то заменяет пропущенные значения с использованием медианы вдоль каждого столбца. Может использоваться только с числовыми данными.
Если “most_frequent”, то заменить пропуски, используя наиболее частое значение вдоль каждого столбца. Может использоваться со строками или числовыми данными. Если таких значений несколько, возвращается только наименьшее.
Если "constant", то заменяет пропущенные значения на fill_value. Может использоваться со строковыми или числовыми данными.
Если экземпляр Callable, то замените пропущенные значения с помощью скалярной статистики, возвращаемой выполнением вызываемого объекта над плотным одномерным массивом, содержащим непропущенные значения каждого столбца.
Добавлено в версии 0.20: strategy=”constant” для фиксированной импутации значений.
Добавлено в версии 1.5: strategy=callable для пользовательской импутации значений.
- fill_valuestr или числовое значение, по умолчанию=None
Когда strategy == “constant”,
fill_valueиспользуется для замены всех вхождений missing_values. Для строковых или объектных типов данных,fill_valueдолжен быть строкой. ЕслиNone,fill_valueбудет 0 при импутации числовых данных и «missing_value» для строковых или объектных типов данных.- copybool, по умолчанию=True
Если True, будет создана копия X. Если False, импутация будет выполнена на месте, когда это возможно. Обратите внимание, что в следующих случаях всегда будет создана новая копия, даже если
copy=False:Если
Xне является массивом значений с плавающей точкой;Если
Xкодируется как CSR-матрица;Если
add_indicator=True.
- add_indicatorbool, по умолчанию=False
Если True,
MissingIndicatortransform будет добавляться к выходу transform импутера. Это позволяет прогнозному оценщику учитывать пропуски, несмотря на импутацию. Если признак не имеет пропущенных значений во время обучения, признак не появится в индикаторе пропусков, даже если есть пропущенные значения во время transform/тестирования.- keep_empty_featuresbool, по умолчанию=False
Если True, признаки, которые состоят исключительно из пропущенных значений, когда
fitвызывается, возвращаются в результатах, когдаtransformвызывается. Импутированное значение всегда0кроме случаев, когдаstrategy="constant"в этом случаеfill_valueбудет использоваться вместо.Добавлено в версии 1.2.
- Атрибуты:
- statistics_массив формы (n_features,)
Значение заполнения для импутации каждого признака. Вычисление статистики может привести к
np.nanзначения. Во времяtransform, признаки, соответствующиеnp.nanстатистика будет отброшена.- indicator_
MissingIndicator Индикатор, используемый для добавления бинарных индикаторов пропущенных значений.
Noneifadd_indicator=False.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
IterativeImputerМногомерный импутер, который оценивает значения для заполнения каждого признака с пропущенными значениями на основе всех остальных.
KNNImputerМногомерный импутер, который оценивает отсутствующие признаки с использованием ближайших образцов.
Примечания
Столбцы, которые содержали только пропущенные значения в
fitотбрасываются приtransformесли стратегия не"constant".В контексте предсказания простая импутация обычно показывает плохие результаты, когда связана со слабым обучающимся алгоритмом. Однако с мощным обучающимся алгоритмом она может привести к таким же или лучшим результатам, чем сложная импутация, такая как
IterativeImputerилиKNNImputer.Примеры
>>> import numpy as np >>> from sklearn.impute import SimpleImputer >>> imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean') >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) SimpleImputer() >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> print(imp_mean.transform(X)) [[ 7. 2. 3. ] [ 4. 3.5 6. ] [10. 3.5 9. ]]
Более подробный пример см. в Заполнение пропущенных значений перед построением оценщика.
- fit(X, y=None)[источник]#
Обучить импутер на
X.- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Входные данные, где
n_samples— это количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует здесь для согласованности API по соглашению.
- Возвращает:
- selfobject
Обученный оценщик.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Преобразовать данные обратно в исходное представление.
Инвертирует
transformоперация, выполняемая над массивом. Эта операция может быть выполнена только послеSimpleImputerинициализируется сadd_indicator=True.Обратите внимание, что
inverse_transformможет инвертировать преобразование только в признаках, которые имеют бинарные индикаторы для пропущенных значений. Если признак не имеет пропущенных значений вfitвремя, признак не будет иметь бинарный индикатор, и импутация, выполненная вtransformвремя не будет инвертировано.Добавлено в версии 0.24.
- Параметры:
- Xarray-like формы (n_samples, n_features + n_features_missing_indicator)
Импутированные данные для возврата к исходным данным. Это должен быть расширенный массив импутированных данных и маска индикатора пропусков.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Оригинальный
Xс пропущенными значениями, как это было до заполнения.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X)[источник]#
Заполнить все пропущенные значения в
X.- Параметры:
- X{array-like, sparse matrix}, форма (n_samples, n_features)
Входные данные для завершения.
- Возвращает:
- X_imputed{ndarray, sparse matrix} формы (n_samples, n_features_out)
Xс импутированными значениями.
Примеры галереи#

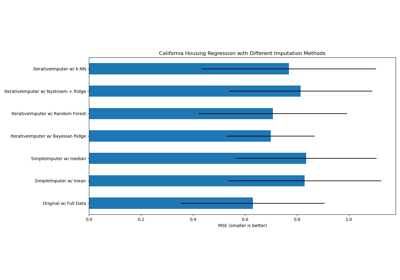
Заполнение пропущенных значений с вариантами IterativeImputer
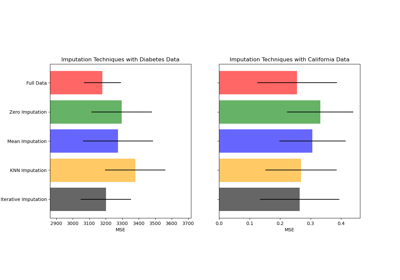
Заполнение пропущенных значений перед построением оценщика
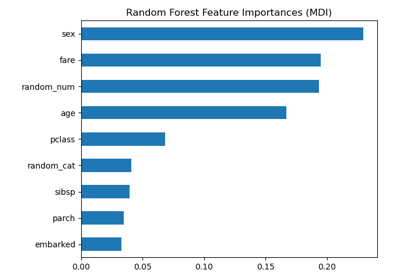
Важность перестановок против важности признаков случайного леса (MDI)