StandardScaler#
- класс sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)[источник]#
Стандартизировать признаки, удаляя среднее и масштабируя до единичной дисперсии.
Стандартная оценка образца
xрассчитывается как:z = (x - u) / s
где
uявляется средним значением обучающих выборок или нулем, еслиwith_mean=False, иsявляется стандартным отклонением обучающих выборок или единицей, еслиwith_std=False.Центрирование и масштабирование происходят независимо для каждого признака путем вычисления соответствующих статистик на выборках обучающего набора. Среднее значение и стандартное отклонение затем сохраняются для использования на последующих данных с помощью
transform.Стандартизация набора данных является общим требованием для многих оценщиков машинного обучения: они могут работать плохо, если отдельные признаки не выглядят более или менее как стандартные нормально распределенные данные (например, гауссовские с нулевым средним и единичной дисперсией).
Например, многие элементы, используемые в целевой функции алгоритма обучения (такие как RBF-ядро метода опорных векторов или L1 и L2 регуляризаторы линейных моделей), предполагают, что все признаки центрированы около 0 и имеют дисперсию одного порядка. Если признак имеет дисперсию, которая на порядки больше, чем у других, он может доминировать в целевой функции и сделать оценку неспособной обучаться на других признаках корректно, как ожидалось.
StandardScalerчувствителен к выбросам, и признаки могут масштабироваться по-разному друг от друга при наличии выбросов. Для примера визуализации см. Сравните StandardScaler с другими масштабаторами.Этот масштабатор также может быть применён к разреженным матрицам CSR или CSC путём передачи
with_mean=Falseчтобы избежать нарушения разреженной структуры данных.Подробнее в Руководство пользователя.
- Параметры:
- copybool, по умолчанию=True
Если False, пытаться избежать копирования и выполнять масштабирование на месте. Это не гарантирует всегда работать на месте; например, если данные не являются массивом NumPy или разреженной матрицей scipy.sparse CSR, все равно может быть возвращена копия.
- with_meanbool, по умолчанию=True
Если True, центрировать данные перед масштабированием. Это не работает (и вызовет исключение) при попытке применить к разреженным матрицам, потому что их центрирование требует построения плотной матрицы, которая в типичных случаях использования, вероятно, будет слишком большой для размещения в памяти.
- with_stdbool, по умолчанию=True
Если True, масштабировать данные до единичной дисперсии (или, что эквивалентно, единичного стандартного отклонения).
- Атрибуты:
- scale_ndarray формы (n_features,) или None
Относительное масштабирование данных по каждому признаку для достижения нулевого среднего и единичной дисперсии. Обычно это вычисляется с использованием
np.sqrt(var_). Если дисперсия равна нулю, мы не можем достичь единичной дисперсии, и данные остаются как есть, давая коэффициент масштабирования 1.scale_равноNoneкогдаwith_std=False.Добавлено в версии 0.17: scale_
- mean_ndarray формы (n_features,) или None
Среднее значение для каждого признака в обучающем наборе. Равно
Noneкогдаwith_mean=Falseиwith_std=False.- var_ndarray формы (n_features,) или None
Дисперсия для каждого признака в тренировочном наборе. Используется для вычисления
scale_. РавноNoneкогдаwith_mean=Falseиwith_std=False.- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
- n_samples_seen_int или ndarray формы (n_features,)
Количество образцов, обработанных оценщиком для каждого признака. Если нет пропущенных образцов,
n_samples_seenбудет целым числом, в противном случае это будет массив типа int. Еслиsample_weightsиспользуются, это будет float (если нет пропущенных данных) или массив типа float, суммирующий веса, наблюдаемые до сих пор. Будет сброшен при новых вызовах fit, но увеличивается приpartial_fitвызовы.
Смотрите также
Примечания
NaN обрабатываются как пропущенные значения: игнорируются при обучении и сохраняются при преобразовании.
Мы используем смещённый оценщик для стандартного отклонения, эквивалентный
numpy.std(x, ddof=0). Обратите внимание, что выборddofмаловероятно, что повлияет на производительность модели.Примеры
>>> from sklearn.preprocessing import StandardScaler >>> data = [[0, 0], [0, 0], [1, 1], [1, 1]] >>> scaler = StandardScaler() >>> print(scaler.fit(data)) StandardScaler() >>> print(scaler.mean_) [0.5 0.5] >>> print(scaler.transform(data)) [[-1. -1.] [-1. -1.] [ 1. 1.] [ 1. 1.]] >>> print(scaler.transform([[2, 2]])) [[3. 3.]]
- fit(X, y=None, sample_weight=None)[источник]#
Вычислить среднее и стандартное отклонение для последующего масштабирования.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для вычисления среднего и стандартного отклонения используемых для последующего масштабирования по оси признаков.
- yNone
Игнорируется.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Индивидуальные веса для каждого образца.
Добавлено в версии 0.24: параметр sample_weight поддержка для StandardScaler.
- Возвращает:
- selfobject
Обученный масштабатор.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Входные признаки.
Если
input_featuresявляетсяNone, затемfeature_names_in_используется как имена признаков в. Еслиfeature_names_in_не определено, тогда генерируются следующие имена входных признаков:["x0", "x1", ..., "x(n_features_in_ - 1)"].Если
input_featuresявляется массивоподобным, тогдаinput_featuresдолжен соответствоватьfeature_names_in_iffeature_names_in_определен.
- Возвращает:
- feature_names_outndarray из str объектов
То же, что и входные признаки.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X, copy=None)[источник]#
Масштабировать данные обратно к исходному представлению.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для масштабирования по оси признаков.
- copybool, по умолчанию=None
Копировать входные данные
Xили нет.
- Возвращает:
- X_original{ndarray, разреженная матрица} формы (n_samples, n_features)
Преобразованный массив.
- partial_fit(X, y=None, sample_weight=None)[источник]#
Онлайн-вычисление среднего и стандартного отклонения X для последующего масштабирования.
Весь X обрабатывается как единый пакет. Это предназначено для случаев, когда
fitнеосуществимо из-за очень большого количестваn_samplesили потому что X считывается из непрерывного потока.Алгоритм для инкрементального среднего и стандартного отклонения приведен в уравнении 1.5a,b в Chan, Tony F., Gene H. Golub, and Randall J. LeVeque. "Algorithms for computing the sample variance: Analysis and recommendations." The American Statistician 37.3 (1983): 242-247:
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Данные, используемые для вычисления среднего и стандартного отклонения используемых для последующего масштабирования по оси признаков.
- yNone
Игнорируется.
- sample_weightarray-like формы (n_samples,), по умолчанию=None
Индивидуальные веса для каждого образца.
Добавлено в версии 0.24: параметр sample_weight поддержка для StandardScaler.
- Возвращает:
- selfobject
Обученный масштабатор.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') StandardScaler[источник]#
Настроить, следует ли запрашивать передачу метаданных в
fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяfitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вfit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вfit.
- Возвращает:
- selfobject
Обновленный объект.
- set_inverse_transform_request(*, copy: bool | None | str = '$UNCHANGED$') StandardScaler[источник]#
Настроить, следует ли запрашивать передачу метаданных в
inverse_transformметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяinverse_transformесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вinverse_transform.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вinverse_transform.
- Возвращает:
- selfobject
Обновленный объект.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_partial_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') StandardScaler[источник]#
Настроить, следует ли запрашивать передачу метаданных в
partial_fitметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяpartial_fitесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вpartial_fit.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вpartial_fit.
- Возвращает:
- selfobject
Обновленный объект.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') StandardScaler[источник]#
Настроить, следует ли запрашивать передачу метаданных в
transformметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяtransformесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вtransform.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- copystr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
copyпараметр вtransform.
- Возвращает:
- selfobject
Обновленный объект.
- преобразовать(X, copy=None)[источник]#
Выполнить стандартизацию путем центрирования и масштабирования.
- Параметры:
- X{array-like, разреженная матрица формы (n_samples, n_features)
Данные, используемые для масштабирования по оси признаков.
- copybool, по умолчанию=None
Копировать входные данные X или нет.
- Возвращает:
- X_tr{ndarray, разреженная матрица} формы (n_samples, n_features)
Преобразованный массив.
Примеры галереи#
Пример распознавания лиц с использованием собственных лиц и SVM

Сравнение различных алгоритмов кластеризации на игрушечных наборах данных
Демонстрация кластеризации K-Means на данных рукописных цифр
Сравнение различных методов иерархической связи на игрушечных наборах данных
Конвейеризация: объединение PCA и логистической регрессии
Регрессия на главных компонентах против регрессии методом частичных наименьших квадратов
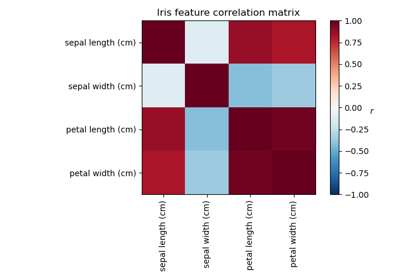
Факторный анализ (с вращением) для визуализации паттернов

Визуализация вероятностных предсказаний VotingClassifier
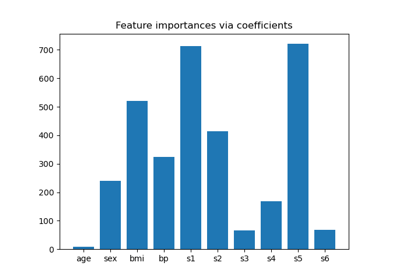
Основанный на модели и последовательный отбор признаков

Распространённые ошибки в интерпретации коэффициентов линейных моделей
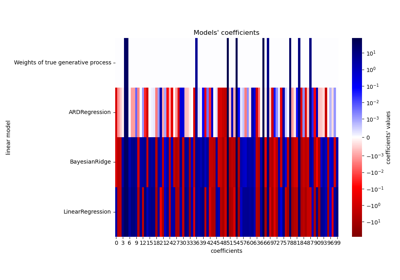
Выбор модели Lasso с помощью информационных критериев
Выбор модели Lasso: AIC-BIC / перекрёстная проверка
L1-штраф и разреженность в логистической регрессии
Классификация MNIST с использованием мультиномиальной логистической регрессии + L1



Расширенное построение графиков с частичной зависимостью

Последующая настройка порога принятия решений для обучения с учетом стоимости
Пост-фактумная настройка точки отсечения функции принятия решений
Сравнение ближайших соседей с анализом компонент соседства и без него
Снижение размерности с помощью анализа компонентов соседства
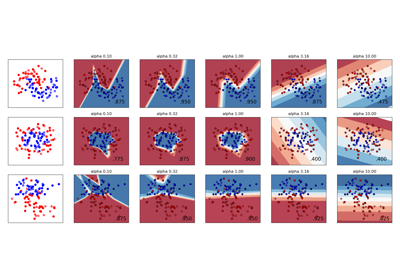
Изменение регуляризации в многослойном перцептроне
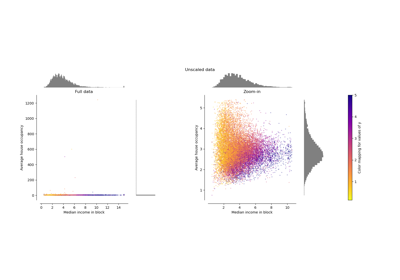
Сравнение влияния различных масштабировщиков на данные с выбросами