FixedThresholdClassifier#
- класс sklearn.model_selection.FixedThresholdClassifier(estimator, *, порог='auto', pos_label=None, response_method='auto')[источник]#
Бинарный классификатор, который вручную устанавливает порог принятия решения.
Этот классификатор позволяет изменять порог принятия решений по умолчанию, используемый для преобразования оценок апостериорной вероятности (т.е. вывода
predict_proba) или оценки решений (т.е. выходdecision_function) в метку класса.Здесь порог не оптимизируется и установлен на постоянное значение.
Подробнее в Руководство пользователя.
Добавлено в версии 1.5.
- Параметры:
- estimatorэкземпляр estimator
Бинарный классификатор, обученный или нет, для которого мы хотим оптимизировать порог принятия решения, используемый во время
predict.- порог{"auto"} или float, по умолчанию="auto"
Порог принятия решения для использования при преобразовании оценок апостериорной вероятности (т.е. вывода
predict_proba) или оценки решений (т.е. выходdecision_function) в метку класса. Когда"auto", порог устанавливается в 0.5, еслиpredict_probaиспользуется какresponse_method, иначе устанавливается в 0 (т.е. порог по умолчанию дляdecision_function).- pos_labelint, float, bool или str, по умолчанию=None
Метка положительного класса. Используется для обработки вывода
response_methodметодом. Когдаpos_label=None, еслиy_trueнаходится в{-1, 1}или{0, 1},pos_labelустановлен в 1, иначе будет вызвана ошибка.- response_method{“auto”, “decision_function”, “predict_proba”}, по умолчанию=”auto”
Методы классификатора
estimatorсоответствующий функции принятия решения, для которой мы хотим найти порог. Это может быть:if
"auto", он попытается вызвать"predict_proba"или"decision_function"в таком порядке.в противном случае, один из
"predict_proba"или"decision_function". Если метод не реализован классификатором, он вызовет ошибку.
- Атрибуты:
- estimator_экземпляр estimator
Обученный классификатор, используемый при предсказании.
classes_ndarray формы (n_classes,)Метки классов.
- n_features_in_int
Количество признаков, замеченных во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определяется только если базовая оценка предоставляет такой атрибут при обучении.
Смотрите также
sklearn.model_selection.TunedThresholdClassifierCVКлассификатор, который пост-настраивает порог принятия решений на основе некоторых метрик с использованием перекрестной проверки.
sklearn.calibration.CalibratedClassifierCVОценщик, который калибрует вероятности.
Примеры
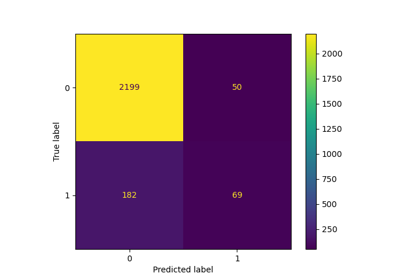
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.metrics import confusion_matrix >>> from sklearn.model_selection import FixedThresholdClassifier, train_test_split >>> X, y = make_classification( ... n_samples=1_000, weights=[0.9, 0.1], class_sep=0.8, random_state=42 ... ) >>> X_train, X_test, y_train, y_test = train_test_split( ... X, y, stratify=y, random_state=42 ... ) >>> classifier = LogisticRegression(random_state=0).fit(X_train, y_train) >>> print(confusion_matrix(y_test, classifier.predict(X_test))) [[217 7] [ 19 7]] >>> classifier_other_threshold = FixedThresholdClassifier( ... classifier, threshold=0.1, response_method="predict_proba" ... ).fit(X_train, y_train) >>> print(confusion_matrix(y_test, classifier_other_threshold.predict(X_test))) [[184 40] [ 6 20]]
- decision_function(X)[источник]#
Функция принятия решений для образцов в
Xс использованием обученного оценщика.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.
- Возвращает:
- решенияndarray формы (n_samples,)
Функция принятия решений вычисляет обученный оценщик.
- fit(X, y, **params)[источник]#
Обучить классификатор.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие данные.
- yarray-like формы (n_samples,)
Целевые значения.
- **paramsdict
Параметры для передачи в
fitметод базового классификатора.
- Возвращает:
- selfobject
Возвращает экземпляр self.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRouter
A
MetadataRouterИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- predict(X)[источник]#
Предсказать цель для новых образцов.
- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Образцы, как принято в
estimator.predict.
- Возвращает:
- class_labelsndarray формы (n_samples,)
Предсказанный класс.
- predict_log_proba(X)[источник]#
Предсказать логарифмические вероятности классов для
Xс использованием обученного оценщика.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.
- Возвращает:
- log_probabilitiesndarray формы (n_samples, n_classes)
Логарифмические вероятности классов входных выборок.
- predict_proba(X)[источник]#
Предсказать вероятности классов для
Xс использованием обученного оценщика.- Параметры:
- X{array-like, sparse matrix} формы (n_samples, n_features)
Обучающие векторы, где
n_samples— это количество образцов иn_featuresэто количество признаков.
- Возвращает:
- вероятностиndarray формы (n_samples, n_classes)
Вероятности классов входных образцов.
- score(X, y, sample_weight=None)[источник]#
Возвращает точность на предоставленных данных и метках.
В многометочной классификации это точность подмножества, которая является строгой метрикой, поскольку требует для каждого образца правильного предсказания каждого набора меток.
- Параметры:
- Xarray-like формы (n_samples, n_features)
Тестовые выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs)
Истинные метки для
X.- sample_weightarray-like формы (n_samples,), по умолчанию=None
Веса выборок.
- Возвращает:
- scorefloat
Средняя точность
self.predict(X)относительноy.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') FixedThresholdClassifier[источник]#
Настроить, следует ли запрашивать передачу метаданных в
scoreметод.Обратите внимание, что этот метод актуален только тогда, когда этот оценщик используется как под-оценщик внутри мета-оценщик и маршрутизация метаданных включена с помощью
enable_metadata_routing=True(см.sklearn.set_config). Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.Варианты для каждого параметра:
True: запрашиваются метаданные и передаютсяscoreесли предоставлено. Запрос игнорируется, если метаданные не предоставлены.False: метаданные не запрашиваются, и мета-оценщик не передаст их вscore.None: метаданные не запрашиваются, и мета-оценщик выдаст ошибку, если пользователь предоставит их.str: метаданные должны передаваться мета-оценщику с этим заданным псевдонимом вместо исходного имени.
По умолчанию (
sklearn.utils.metadata_routing.UNCHANGED) сохраняет существующий запрос. Это позволяет изменять запрос для некоторых параметров, но не для других.Добавлено в версии 1.3.
- Параметры:
- sample_weightstr, True, False или None, по умолчанию=sklearn.utils.metadata_routing.UNCHANGED
Маршрутизация метаданных для
sample_weightпараметр вscore.
- Возвращает:
- selfobject
Обновленный объект.
Примеры галереи#
Визуализация вероятностных предсказаний VotingClassifier

Последующая настройка порога принятия решений для обучения с учетом стоимости