SparseCoder#
- класс sklearn.decomposition.SparseCoder(словарь, *, transform_algorithm='omp', transform_n_nonzero_coefs=None, transform_alpha=None, split_sign=False, n_jobs=None, positive_code=False, transform_max_iter=1000)[источник]#
Разреженное кодирование.
Находит разреженное представление данных относительно фиксированного, предварительно вычисленного словаря.
Каждая строка результата является решением задачи разреженного кодирования. Цель — найти разреженный массив
codeтакой, что:X ~= code * dictionary
Подробнее в Руководство пользователя.
- Параметры:
- словарьndarray формы (n_components, n_features)
Атомы словаря, используемые для разреженного кодирования. Строки предполагаются нормализованными к единичной норме.
- transform_algorithm{‘lasso_lars’, ‘lasso_cd’, ‘lars’, ‘omp’, ‘threshold’}, по умолчанию=’omp’
Алгоритм, используемый для преобразования данных:
'lars': использует метод наименьшего угла регрессии (linear_model.lars_path);'lasso_lars': использует Lars для вычисления решения Lasso;'lasso_cd': использует метод координатного спуска для вычисления решения Lasso (linear_model.Lasso).'lasso_lars'будет быстрее, если оцененные компоненты разрежены;'omp': использует ортогональное согласованное преследование для оценки разреженного решения;'threshold': обнуляет все коэффициенты меньше alpha из проекцииdictionary * X'.
- transform_n_nonzero_coefsint, default=None
Количество ненулевых коэффициентов для целевого значения в каждом столбце решения. Используется только
algorithm='lars'иalgorithm='omp'и переопределяетсяalphaвompслучай. ЕслиNone, затемtransform_n_nonzero_coefs=int(n_features / 10).- transform_alphafloat, по умолчанию=None
Если
algorithm='lasso_lars'илиalgorithm='lasso_cd',alphaявляется штрафом, применяемым к норме L1. Еслиalgorithm='threshold',alphaявляется абсолютным значением порога, ниже которого коэффициенты будут сжаты до нуля. Еслиalgorithm='omp',alphaэто параметр допуска: значение целевой ошибки реконструкции. В этом случае он переопределяетn_nonzero_coefs. ЕслиNone, по умолчанию 1.- split_signbool, по умолчанию=False
Разделять ли разреженный вектор признаков на конкатенацию его отрицательной части и его положительной части. Это может улучшить производительность последующих классификаторов.
- n_jobsint, default=None
Количество параллельных задач для выполнения.
Noneозначает 1, если только не вjoblib.parallel_backendконтекст.-1означает использование всех процессоров. См. Глоссарий для получения дополнительной информации.- positive_codebool, по умолчанию=False
Следует ли обеспечивать положительность при нахождении кода.
Добавлено в версии 0.20.
- transform_max_iterint, по умолчанию=1000
Максимальное количество итераций для выполнения, если
algorithm='lasso_cd'илиlasso_lars.Добавлено в версии 0.22.
- Атрибуты:
- n_components_int
Количество атомов.
- n_features_in_int
Количество признаков, замеченных во время fit.
Добавлено в версии 0.24.
- feature_names_in_ndarray формы (
n_features_in_,) Имена признаков, наблюдаемых во время fit. Определено только когда
Xимеет имена признаков, которые все являются строками.Добавлено в версии 1.0.
Смотрите также
DictionaryLearningНайти словарь, который разреженно кодирует данные.
MiniBatchDictionaryLearningБолее быстрая, но менее точная версия алгоритма обучения словарю.
MiniBatchSparsePCAМини-пакетный разреженный анализ главных компонент.
SparsePCAРазреженный анализ главных компонент.
sparse_encodeРазреженное кодирование, где каждая строка результата является решением задачи разреженного кодирования.
Примеры
>>> import numpy as np >>> from sklearn.decomposition import SparseCoder >>> X = np.array([[-1, -1, -1], [0, 0, 3]]) >>> dictionary = np.array( ... [[0, 1, 0], ... [-1, -1, 2], ... [1, 1, 1], ... [0, 1, 1], ... [0, 2, 1]], ... dtype=np.float64 ... ) >>> coder = SparseCoder( ... dictionary=dictionary, transform_algorithm='lasso_lars', ... transform_alpha=1e-10, ... ) >>> coder.transform(X) array([[ 0., 0., -1., 0., 0.], [ 0., 1., 1., 0., 0.]])
- fit(X, y=None)[источник]#
Проверяйте только параметры оценщика.
вернет, например,
- Параметры:
- Xarray-like формы (n_samples, n_features)
Обучающие данные. Используются только для проверки входных данных.
- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- selfobject
Возвращает сам экземпляр.
- fit_transform(X, y=None, **fit_params)[источник]#
Обучение на данных с последующим преобразованием.
Обучает преобразователь на
Xиyс необязательными параметрамиfit_paramsи возвращает преобразованную версиюX.- Параметры:
- Xarray-like формы (n_samples, n_features)
Входные выборки.
- yarray-like формы (n_samples,) или (n_samples, n_outputs), default=None
Целевые значения (None для неконтролируемых преобразований).
- **fit_paramsdict
Дополнительные параметры обучения. Передавайте только если оценщик принимает дополнительные параметры в своем
fitметод.
- Возвращает:
- X_newndarray массив формы (n_samples, n_features_new)
Преобразованный массив.
- get_feature_names_out(input_features=None)[источник]#
Получить имена выходных признаков для преобразования.
Имена признаков на выходе будут иметь префикс в виде имени класса в нижнем регистре. Например, если преобразователь выводит 3 признака, то имена признаков на выходе:
["class_name0", "class_name1", "class_name2"].- Параметры:
- input_featuresarray-like из str или None, по умолчанию=None
Используется только для проверки имен признаков с именами, встреченными в
fit.
- Возвращает:
- feature_names_outndarray из str объектов
Преобразованные имена признаков.
- 6332()[источник]#
Получить маршрутизацию метаданных этого объекта.
Пожалуйста, проверьте Руководство пользователя о том, как работает механизм маршрутизации.
- Возвращает:
- маршрутизацияMetadataRequest
A
MetadataRequestИнкапсуляция информации о маршрутизации.
- get_params(глубокий=True)[источник]#
Получить параметры для этого оценщика.
- Параметры:
- глубокийbool, по умолчанию=True
Если True, вернет параметры для этого оценщика и вложенных подобъектов, которые являются оценщиками.
- Возвращает:
- paramsdict
Имена параметров, сопоставленные с их значениями.
- inverse_transform(X)[источник]#
Преобразование данных обратно в исходное пространство.
- Параметры:
- Xarray-like формы (n_samples, n_components)
Данные для обратного преобразования. Должны иметь то же количество компонентов, что и данные, использованные для обучения модели.
- Возвращает:
- X_originalndarray формы (n_samples, n_features)
Преобразованные данные.
- set_output(*, преобразовать=None)[источник]#
Установить контейнер вывода.
См. Введение API set_output для примера использования API.
- Параметры:
- преобразовать{“default”, “pandas”, “polars”}, по умолчанию=None
Настройка вывода
transformиfit_transform."default": Формат вывода трансформера по умолчанию"pandas": DataFrame вывод"polars": Вывод PolarsNone: Конфигурация преобразования не изменена
Добавлено в версии 1.4:
"polars"опция была добавлена.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- set_params(**params)[источник]#
Установить параметры этого оценщика.
Метод работает как на простых оценщиках, так и на вложенных объектах (таких как
Pipeline). Последние имеют параметры вида__ - Параметры:
- **paramsdict
Параметры оценщика.
- Возвращает:
- selfэкземпляр estimator
Экземпляр оценщика.
- преобразовать(X, y=None)[источник]#
Закодируйте данные как разреженную комбинацию атомов словаря.
Метод кодирования определяется параметром объекта
transform_algorithm.- Параметры:
- Xarray-like формы (n_samples, n_features)
Вектор обучения, где
n_samplesэто количество образцов иn_featuresэто количество признаков.- yИгнорируется
Не используется, присутствует для согласованности API по соглашению.
- Возвращает:
- X_newndarray формы (n_samples, n_components)
Преобразованные данные.
Примеры галереи#
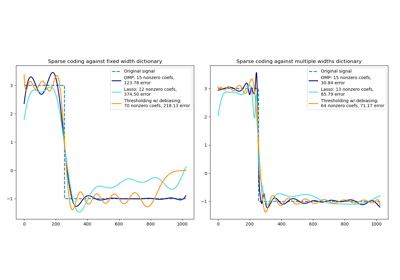
Разреженное кодирование с предвычисленным словарём